空间抽样与统计推断相关模型在这里分别介绍,有利于用户了解功能使用,及抽样模型选择。
单点地域估计(SPA)
在调查对象只有一个有效样本点,且同时能获取到与该对象相关性大的相关变量全覆盖情况下,以该相关变量为协变量,通过该样本点对总体均值进行无偏估计的方法。当协变量与该调查对象具有强相关性时,该模型可以实现对目标总体的无偏估计。
BShade模型
在样本有偏情况下,由已有数据或协变量计算每两个样本之间的关联系数,即样本与总体、样本均值与总体均值(估计目标之比值),实现有偏样本对总体均值的无偏估计的一种方法。 在有充分的历史数据或者先验信息能够度量出每个样本点相对于目标总体(总量或者均值)的比值,且能够计算出总体内两两样本之间的协方差时,该模型能显著提高估计的精度。
简单随机抽样
从总体中抽取n个抽样单元构成样本,使n个抽样单元所有的可能组合都有相等被抽到概率。当总体各组成不存在相关性和异质性时,可以选择该模型;当总体各组成部分存在相关性或异质性时,该模型抽样误差大、效率低。是否存在空间相关性和空间异质性可分别用Moran’s I统计量和地理探测器q值进行判断。
系统随机抽样
假设总体单元数为N,样本量为n,且总体中的N个单元按某种确定顺序编号为1,2,……,N。首先随机抽取一个样本单元编号,然后按照某种预设的顺序,抽取其他n-1个样本编号。该方法在操作上比简单随机抽样更容易。
空间简单随机抽样
以简单随机抽样方法为基础,计算样本量和统计推断时考虑空间自相关性。为达到给定精度,所需样本量比使用简单随机抽样少。当空间分布对象存在自相关,但不存在空间异质性时,该方法抽样效率较好、运用简单。
分层随机抽样
抽样在每一层中独立进行,总的样本由各层样本组成,总体参数则根据各层样本参数的汇总做出估计。设总的样本量为n,从L个层中所抽取的样本量分别为n1,n2,……,nL,则有n1+n2+nL=n。每层中的抽样都是独立地按照简单随机抽样进行的,所得的样本称为分层随机样本。 在总体情况复杂,各组成部分之间差异较大且各组成部分内部变差较小的情况下,该方法的优势比较明显。适用于存在异质性而不存在自相关性的空间分布对象。
空间分层随机抽样
针对具有空间分层异质性的调查对象,可以先进行空间分类,再用空间分层抽样方法进行空间布样和统计推断。划分层的原则是:层内方差小,层间方差大,属性值相对接近的点被划分到同一层抽样在每一层中独立进行。 在总体情况复杂、各层之间的差异较大、内部差异较小且具有空间相关性的情况下,该方法的优势比较明显。
三明治随机抽样
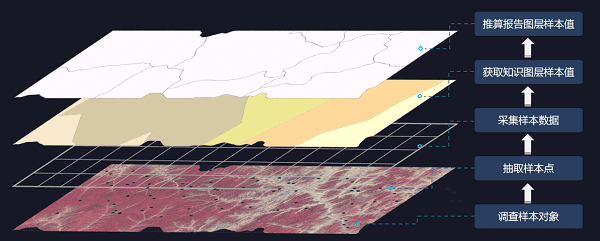
在空间分层抽样的基础上,增加报告单元层(如行政单元、自然单元或其他用户感兴趣的多个单元),可以一次抽样,多单元、多报告系统同时报告。 当被调查对象空间分异比较明显,知识分区逼近被调查对象真实分异,样本量小,并且需要按照指定的多单元汇报结果的情况下,该模型的优势比较明显。解决了在总体分异条件下小样本多报告单元抽样问题,可以用较少的样本量实现多报告单元报告。
下图为三明治随机抽样应用示意图:
总结下表为每个模型的定义和特点,用户可参考理解,方便选择合适的模型进行空间抽样与统计推断。
| 模型名称 | 描述 | 特点 |
|---|---|---|
| 简单随机抽样 | 从总体中不加任何分工、划类、排队等,完全随机地抽取调查单位。 | 每个样本单位被抽中的概率相等,样本的每个单位完全独立,彼此间无一定的关联性和排斥性。简单随机抽样是其他各种抽样形式的基础。 |
| 系统随机抽样 | 将总体各单位按一定标志和次序排列成为图形或一览表式,然后按相等的距离或间隔抽取样本单位。 | 抽出的单位在总体中是均匀分布的,且抽取的样本可少于纯随机抽样。等距抽样即可以用同调查项目相关的标志排队,也以用同调查项目无关的标志排队。 |
| 分层随机抽样 | 先将总体的单位按某种特征分为次级总体(层),然后再从每一层内进行单纯随机抽样,组成一组样本,分层可以提高总体指标估计值的精确度,它可以将一个内部变异很大的总体分成一些内部变异较小的层(次总体)。 | 由于通过划类分层,增大了各类型中的样本的共同性,容易抽出具有代表性的调查样本。 |
| 空间简单随机抽样 | 在简单随机抽样基础上,考虑空间自相关性所抽取出来的样本单位。在计算抽样精度的时候,考虑样本间的空间相关性。 | 比简单随机样本量小,考虑相关性,减少同类样本的重复抽取,提高效率,计算结果精度更高。 |
| 空间分层随机抽样 | 在分层基础上,考虑空间自相关性所抽取出来的样本单位。在计算抽样精度的时候,考虑样本间的空间相关性。 | 考虑空间自相关,比分层抽样抽取的样本点少,提高了精度。 |
| 三明治随机抽样 | 在空间分层基础上,与实际应用相结合,增加报告单元层(用户希望知道的报告单元)。 | 避免传统方法,根据报告单元和分层关系,直接计算结果,方便用户,提高精度,并减少样本量。 |
| 单点地域估计(SPA) | 当数据特征同时包括空间自相关和空间分异性,且调查对象只有一个有效样本点,该样本点对总体均值进行无偏估计。 | 在只有一个样本点时选择单点地域估计(SPA)方法 |
| BShade模型 | 当数据特征同时包括空间自相关和空间分异性,B-Shade模型充分利用地理空间横向相关性,以及样本与区域总体之间的纵向相关性,广泛应用于样本有偏的统计推断。 | 如果有些层没有样本,此时样本有偏,即样本直方图不等于总体直方图,需要用具有纠偏能力的BShade方法 |