使用说明
在样本有偏情况下,由已有数据或协变量计算每两个样本之间的关联系数,即样本与总体、样本均值与总体均值(估计目标之比值),实现有偏样本对总体均值的无偏估计的一种方法。
(样本有偏:在统计学研究中,用于估计所研究的参数数据依赖于从总体中抽取的样本。如果抽取的样本是随机的,即类似“抽签”的方式获得的样本,根据这些样本数据所估计的各种参数能够准确反映总体的相关特性, 理论上就是所估计的参数是无偏的;但是如果所抽取的样本不是随机的,那么根据这些样本所估计的参数就不能准确反映所研究的总体性质的分布。但是多数的抽样都不是随机的,只在研究者所选择的界定范围和规则内进行,这就可能出现抽样选择的偏差。)
在有充分的历史数据或者先验信息能够度量出每个样本点相对于目标总体(总量或者均值)的比值,且能够计算出总体内两两样本之间的协方差时,该模型能显著提高估计的精度。B-Shade模型充分利用地理空间横向相关性,以及样本与区域总体之间的纵向相关性,广泛应用于样本有偏的统计推断。即使样本有偏,用B- shade模型也可以得到区域总体无偏最优估计。
功能入口
- 空间统计分析 选项卡 -> 空间抽样与统计推断 -> ->BShade抽样。(iDesktopX)
- 工具箱 -> 空间统计分析 -> 空间抽样与统计推断 -> BShade抽样。(iDesktopX)
参数说明
- 历史数据 :指定的历史数据集及所在数据源。以下案例中表示19家医院去年的发病数据。
-
参数设置 :
- 历史数据字段 :勾选指定的历史数据集数据字段。以下案例中表示记录去年19家医院数据的字段,共勾选19条。
- 抽样数目方法 :选择固定字段或范围字段。
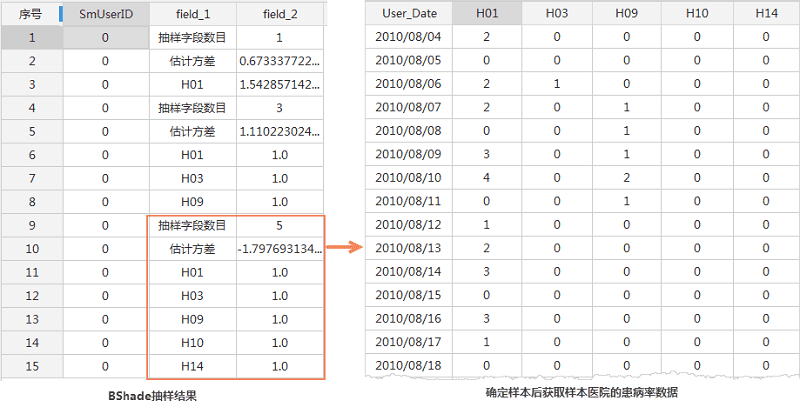
- 固定字段 :即抽样获得估计差异最小的固定数量的样本,以下案例中 样本数目 设置为5,表估计差异最小的5家医院被选为最佳采样选择。
- 范围字段 :将根据设置的抽样数目上限、下限和步长产生所有样本选择和对应的估计方差。可根据尽可能少的样本数目(减少成本)和尽可能小的估计方差(更高准确度)选择最佳方案。
- 估计方法 :BShade估计方法。总量方法,即按照样本与总体之比值;均量方法,即按照样本均值与总体均值的比值。
- 模拟退火算法选项:模拟退火算法是一种通用的优化算法,出发点是基于物理中固体物质的退火过程与一般组合优化问题之间的相似性。从某一较高初温出发,伴随温度参数的不断下降,结合概率突跳特性在解空间中随机寻找目标函数的全局最优解,即在局部最优解能概率性地跳出并最终区域全局最优。相关参数包括起始温度、最小温度、最小能量、退火速率、最大拒绝数目、最大尝试数目、最大成功数目、最大组合数目。都已有默认值。
- 结果数据 :设置结果数据集及所在数据源。
- 单击“ 执行 ”按钮,执行准备好的分析功能。执行完成后输出窗口中,会提示执行结果是成功还是失败。
应用案例
某区域需得到今年某月某疾病每天的发病率,由于医院较多,所有医院的数据收集较为耗时,现需对定点医院进行抽样作为样本,进而得到预测结果。预测前已收集区域内19家定点医院去年的发病数据作为参考,使用BShade抽样功能,能抽取得到估计方差最小的5家医院作为样本,并用这5家医院今年的发病率数据进行预测分析。
- 案例数据 :单击此处可下载BShade抽样及预测的案例数据,下载后解压即可。参与分析的数据为:HospitalCaseHistorical,为该区域所有医院的历史发病率数据。
- 参数设置 :下载上述案例数据后,在桌面打开 BShadeData.udbx,进行下图所示的参数设置,执行 BShade抽样分析即可。本案例采用范围字段的方式进行抽样,根据设置的抽样数目上限、下限以及步长,得到多组抽样结果。
- 结果说明 :通过BShade抽样的范围字段方法分析之后,可得到多组样本,最终我们选择最后一组为样本医院,并整理这5个医院最近的发病率数据,用于后期的BShade预测分析,结果数据如下图: