高低聚类是使用 Getis-Ord General G 统计可度量高值或低值的聚类程度。General G 指数也是一种推论统计,即利用有限的数据来对整体情况的特征进行估计。当结果返回的P值较小,且在统计学上显著,则可以拒绝零假设,此时,若 Z 值为正数,则观测的 General G 指数会比期望的 General G 指数要大,表明属性的高值将在研究区域中聚类;若 Z 值为负数,则观测的 General G 指数会比期望的 General G 指数要小一些,表明属性的低值将在研究区域中聚类。
应用案例
- 在访问急症室的次数中查找出现的异常峰值,可能表明在局部或区域的健康问题的爆发。
- 比较在城市中不同种类零售业的空间模式,利用比较购物的方式来了解哪类行业充满竞争性(如汽车经销商)以及哪类行业拒绝竞争(如健康中心/健身房)。
- 汇总空间现象聚类的程度以检查不同时期或不同位置的变化。例如,众所周知的城市及其人口聚类。使用高/低聚类分析时,可以随时间来比较某个城市的人口聚类的程度(城镇发展以及密集度的分析)
功能入口
- 空间分析 选项卡 -> 空间统计分析 组 -> 分析模式 -> 高低值聚类 。(iDesktop)
- 空间统计分析 选项卡 -> 分析模式 -> 高低值聚类 。(iDesktopX)
- 工具箱 -> 空间统计分析 -> 分析模式 -> 高低值聚类 。(iDesktopX)
主要参数
- 源数据 :设置待分析的矢量数据集,支持点、线、面三种类型的数据集。
- 评估字段 :设置分析要素参与分析的属性字段值,仅支持数值型字段。
-
概念化模型 :选择应反映要分析的要素之间的固有关系,设置要素在空间中彼此交互方式构建的模型越逼真,结果就越准确。
- 固定距离模型:适用于点数据、及面大小变化较大的面数据。
- 面邻接模型(共边、相交):适用于存在相邻边、相交的面数据。
- 面邻接模型(邻接点、共边、相交):适用于有邻接点、相邻边、相交的面数据。
- 反距离模型:所有要素均被视为所有其他要素的相邻要素,所有要素都会影响目标要素,但是随着距离的增加,影响会越小,要素之间的权重为距离分之一,适用于连续数据。
- 反距离平方模型:与”反距离模型”相似,随着距离的增加,影响下降的更快,要素之间的权重为距离的平方分之一。
- K最邻近模型:距目标要素最近的K个要素包含在目标要素的计算中(权重为1),其余的要素将会排除在目标要素计算之外(权重为0)。如果想要确保具有一个用于分析的最小相邻要素数,该选项非常有效。当数据的分布在研究区域上存在变化以致于某些要素远离其他所有要素时,该方法十分适用。当固定分析的比例不如固定相邻对象数目重要时,K 最近邻方法较适合。
- 空间权重矩阵:需要提供空间权重矩阵文件,空间权重是反映数据集中每个要素和其他任何一个要素之间的距离、时间或其他成本的数字。如果要对城市服务的访问性进行建模,例如要查找城市犯罪集中的地区,借助网络对空间关系进行建模是一个好办法。可选择已有的空间权重矩阵文件 (.swmb),也可根据源数据集创建一个新的空间矩阵文件。
- 无差别区域模型:该模型是”反距离模型”和”固定距离模型”的结合,会将每个要素视为其他各个要素的相邻要素,该选项不适合大型数据集,在指定的固定距离范围内的要素具有相等的权重(权重为1);在指定的固定距离范围之外的要素,随着距离的增加,影响会越小。
- 中断距离容限 :”-1”表示计算并应用默认距离,此默认值为保证每个要素至少有一个相邻的要素;“0”表示为未应用任何距离,则每个要素都是相邻要素。非零正值表示当要素间的距离小于此值时为相邻要素。
- 反距离幂指数 :控制距离值的重要性的指数,幂值越高,远处的影响会越小。
- 相邻数目 :设置一个正整数,表示目标要素周围最近的K个要素为相邻要素。当概念化模型选择的是“K最邻近模型”时需要设置该参数。
- 距离计算方法 :距离计算的方法采用欧氏距离和曼哈顿距离。有关欧式距离和曼哈顿距离的详细描述,请参看空间统计分析基本词汇。
- 空间权重矩阵标准化 :当要素的分布由于采样设计或施加的聚合方案而可能偏离时,建议使用空间权重矩阵标准化。选择空间权重矩阵标准化后,每个权重都会除以行的和(所有相邻要素的权重和)。空间权重矩阵标准化的权重通常与固定距离相邻要素结合使用,并且几乎总是用于基于面邻接的相邻要素。这样可减少因为要素具有不同数量的相邻要素而产生的偏离。空间权重矩阵标准化将换算所有权重,使它们在 0 和 1 之间,从而创建相对(而不是绝对)权重方案。每当要处理表示行政边界的面要素时,您都可能会希望选择“空间权重矩阵标准化”选项。
结果说明
分析结果为CAD数据集,并且将在地图窗口中展示。
高低值聚类分析结果包括:General G指数、期望值、方差、Z得分、P值五个参数。高低值聚类分析是一种推论统计,这意味着分析结果将在零假设的情况下进行解释。分析结果返回的 p 值较小且在统计学上显著,则可以拒绝零假设。如果零假设被拒绝,则 z 得分的符号将变得十分重要,若 z 得分值为正数,则观测的 General G 指数会比期望的 General G 指数要大一些,表明属性的高值将在研究区域中聚类;若 z 得分值为负数,则观测的 General G 指数会比期望的 General G 指数要小一些,表明属性的低值将在研究区域中聚类。如下图所示:
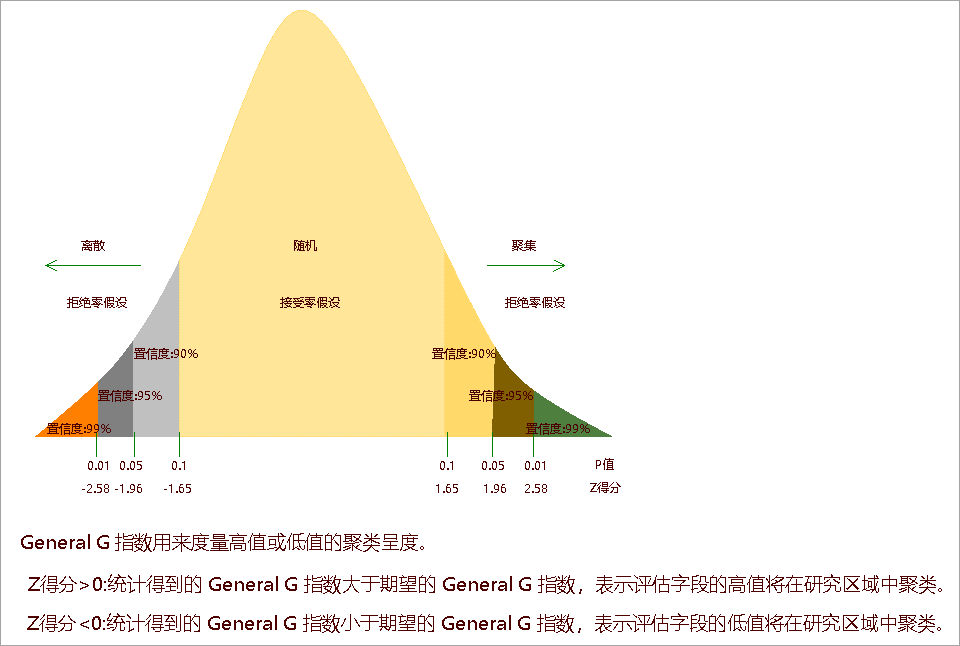
当存在完全均匀分布的值并且要查找高值的异常空间峰值时,首选高低值聚类分析。当观测 General G 指数等于期望 General G 指数时,高值和低值同时聚类,它们倾向于彼此相互抵消。此时可以使用空间自相关分析。
实例
案例数据:单击此处可下载AnalysisPatterns 案例数据,下载后解压即可使用。
现有某省某年病毒性肝炎数据(Pneumonia),对病毒性肝炎数据的发病数进行高低值聚类分析,设置评估字段分别为发病数,概念化模式为反距离模型,距离计算方法为欧式距离,对空间权重矩阵进行标准化,其它默认。分析结果如下:

通过分析结果可以得出以下结论:
在随机分布的假设下,P值 < 0.01 且 z得分 > 2.58, 该省当年肝炎发病数的分析结果具有99%的置信度是具有显著性的。General G 值高于期望 GeneralG 指数且Z值显著,观测值发病数呈现高值聚集,说明发病数在高值区域呈现聚类。
