使用说明
分析样本数据的空间分布规律和空间趋势,判断是否存在空间自相关(可用空间统计),然后可以基于样本数据对总体数据的总量或均值等进行估计,如区域人口数、人口密度、气候变化、污染量、疾病流行率等。提供与随机抽样下对应的六种模型的统计推断方法,包括简单随机抽样、系统随机抽样、空间简单随机抽样、分层随机抽样、空间分层随机抽样、三明治随机抽样六种方式。
功能入口
- 空间统计分析 选项卡 -> 空间抽样与统计推断 -> 统计推断 。(iDesktopX)
- 工具箱 -> 空间统计分析 -> 空间抽样与统计推断 -> 统计推断 。(iDesktopX)
参数说明
- 源数据 :设置待进行统计推断的数据集及所在数据源。
- 分层数据 :设置三明治随机抽样的分层数据集及所在数据源。分层数据指的是基于知识经验、历史数据和辅助数据对研究区域按照层内方差最小、层间方差最大(空间分异性显著)的目标对研究区进行分层得到的。划分层既可以是地理空间也可以在属性空间,即分类,同一层不要求连片。(只在选择 三明治随机抽样 方法时需要设置)
- 报告单元数据 :设置三明治随机抽样的报告单元数据集及所在数据源。报告单元是在“三明治”模型中,顶层的各单元,可以是行政单元、自然单元、格网单元、或用户感兴趣的其他任意空间单元。最后结果是对每个报告单元的估计值。 (只在选择 三明治随机抽样 方法时需要设置)
-
参数设置 :根据不同随机抽样类型进行设置。
- 随机抽样类型:包括简单随机抽样、系统随机抽样、空间简单随机抽样、分层随机抽样、空间分层随机抽样、三明治随机抽样六种方式,根据数据特征选择合适的抽样模型进行统计推断。
- 抽样数据字段 :指定的抽样数据字段名称。
- 置信度:根据均值正态分布假设,用户希望在多大程度上相信得到的结果可信。可参考空间统计分析基本词汇中的解释。
- 样本图层ID :指定的样本所属的分层ID(系统会自动生成Layered_ID)。(在选择 分层随机抽样 、 空间分层随机抽样 、 三明治随机抽样 方法时需要设置)
- 总体样本总数 :指定的分层对象包含的总体样本总数(系统会自动生成Layered_PopulationSize)。(在选择 分层随机抽样 、空间分层随机抽样 、 三明治随机抽样 方法时需要设置)
应用案例
为了解1998年山西省和顺县总的人口数,需要从326个行政村中,以镇行政区为层分层抽取行政村进行抽样调查,要求估算总人口的标准差不超过12626,即软件中设置的估算总人口均值方差不超过1500,各镇所含行政村的数量已知,由以往调查数据可估算得到各分层村人口数量的标准差。
根据分层随机抽样中的案例,已得到样本点,并输入了样本的人工总数,此时,根据 统计推断 功能即可推断出山西省和顺县1998年的人口总数均值。具体说明如下:
-
案例数据 :单击此处可下载分层随机抽样及预测推断的案例数据,下载后解压即可。
- hs_samplingframe :行政村点数据集;
- hs_town :镇行政区划数据,作为分层数据,属性表中的CODE为镇的编号,NAME为镇名,NUM为该镇的行政村数量,STDEV为以往调查的该镇人口的标准差;
- RandomSamplingResult :行政村样本数据,其中Value字段为样本点1998年的人口总数;
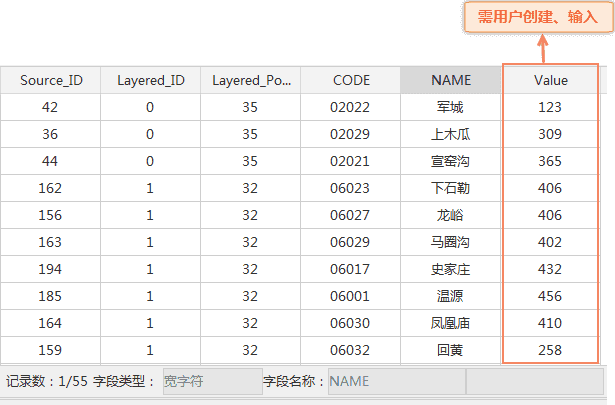
- 参数设置 :下载上述案例数据后,在桌面打开 RandomSamplingData.udbx,打开 统计推断 对话框后,参数设置如下图所示,设置源数据、抽样类型、抽样数据、样本图层ID和样本总数等参数后,单击 执行 按钮,即可进行统计推断。
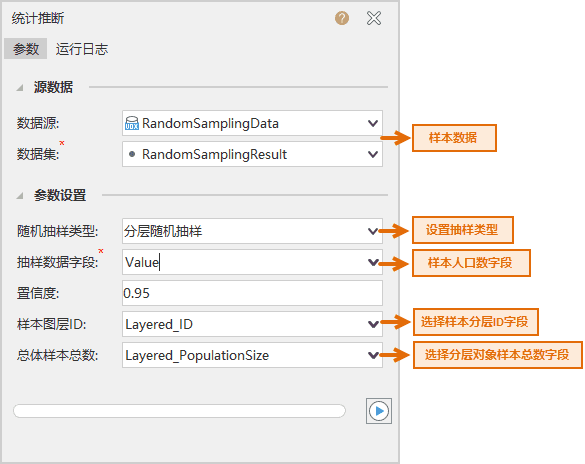
- 结果说明 :根据 55个行政村样本点的人口数据,推断出行政村人口总数的人口平均数为:272.57,以及标准差、每层样本的均值等参数,其中标准方差为242.89,小于1500,满足案例要求。输出窗口中的结果如下图: