使用说明
单点地域估计,即SPA统计推断方法,在调查对象只有一个有效样本点且同时能获取到该对象相关性大的相关变量全覆盖数据情况下,以该相关变量为协变量,通过该单个样本点对总体均值进行无偏估计的方法。当协方差与调查对象之间具有强的相关性时,该模型可以实现对目标总体的无偏估计。
例如当只有一个站点的PM2.5浓度数据时,很难插值得到整个城市的平均值,但是如果有北京18个站点的PM10数据,可以用该数据的数据趋势为参考插值到PM2.5数据中,进行北京PM2.5的平均浓度估计。

注 :功能原理及案例引自:Wang JF,Hu MG,Xu CD,Christakos G,Zhao Y.2012.Estimation of citywide air pollution in Beijing.PLoS ONE (1):e53400.
功能入口
- 空间统计分析 选项卡-> 空间抽样与统计推断 -> 单点地域估计。(iDesktopX)
- 工具箱 -> 空间统计分析 -> 空间抽样与统计推断 -> 单点地域估计。(iDesktopX)
参数说明
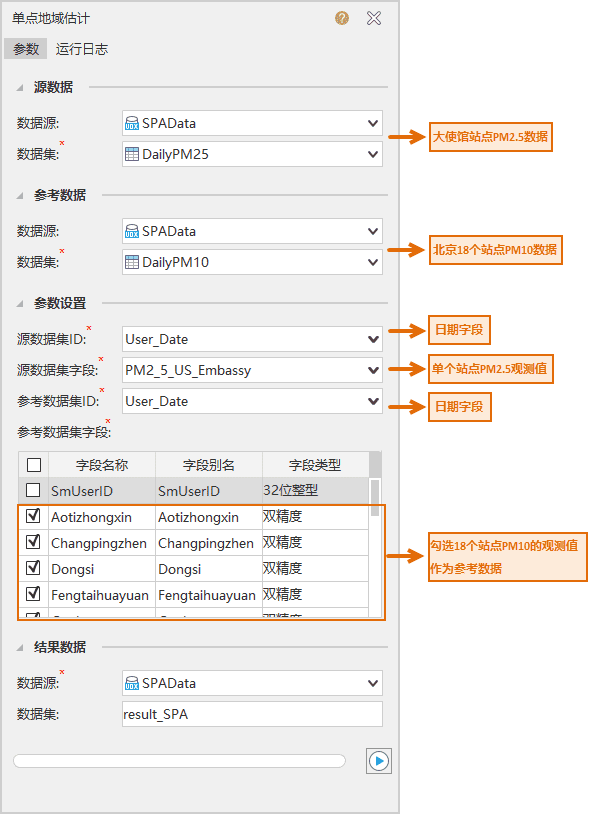
- 源数据 :设置待进行SPA统计推断的数据集及所在数据源。案例中为大使馆PM2.5数据(多天)。
- 参考数据 :设置参考数据集及所在数据源。案例中为北京18个站点PM10数据(多天)。
-
参数设置 :
- 源数据集ID :指定的源数据集唯一字段名称。案例中为PM2.5数据中标注日期的字段。
- 源数据集字段 :指定的源数据集数据字段名称。案例中为记录大使馆PM2.5观测值的字段。
- 参考数据集ID :指定的参考数据集唯一字段名称。案例中为PM10数据中标注日期的字段,与源数据集ID保持一致。
- 参考数据集字段 :勾选指定的参考数据集数据字段。案例中为记录多个站点PM10观测值的字段,共勾选18条。
- 结果数据 :设置结果数据集及所在数据源。
- 单击“ 执行 ”按钮,执行准备好的分析功能。执行完成后输出窗口中,会提示执行结果是成功还是失败。
应用案例
现有北京18个观测站的 PM10 质量浓度值(多天),以及美国驻华大使馆一个观测站 PM2.5 的质量浓度值(多天),想根据这两个数据推断北京整个区域的 PM2.5 浓度平均值。由于 PM10 和 PM2.5 的浓度是相关的,大多数 PM10 是由 PM2.5 贡献的。因此,可以使用 SPA 单点地狱统计模型进行分析。案例的数据、参数设置及结果展示如下:
案例数据 :单击此处可下载SPA案例数据,下载后解压即可使用。
参数设置 :下载上述案例数据后,在桌面打开SPAData.udbx,进行下图所示的参数设置,即可执行SPA分析。
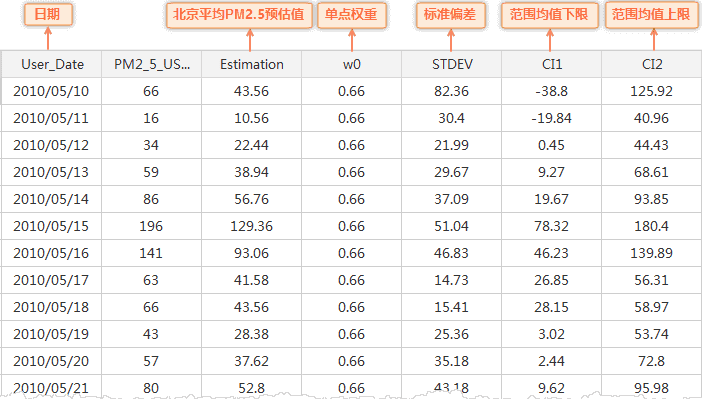
结果说明 :通过SPA单点地域估计后,可得到北京区域的 PM2.5平均值,结果数据如下图: