



Class EncodeType
- java.lang.Object
-
- com.supermap.data.Enum
-
- com.supermap.data.EncodeType
-
public class EncodeType extends Enum
Defines the encoding modes for dataset compression.For the volume of spatial data is usually very tremendous, to encode the dataset can compress the data, in this way, the space used to store the dataset can be saved. For vector dataset, four encode types are supported, they are single-byte, double-byte, triple-byte and four-byte. The four encode types are based on the similar encoding mechanism, but the compression ratios are different, and the four encodings are lossy. Note that the point dataset and the tabular dataset can not be encoded. Note that the point dataset and the tabular dataset can not be encoded. For the raster data, four kinds of encoding can be used, they are DCT, SGL and LZW, among which, the SGL and LZW encoding are lossless.The cad dataset do not support any encode type.
Now taking encoding a line dataset with the single-byte encoding type as an example to explain how the four encodings for the vector dataset work.
Suppose the spatial data in the line dataset is stored as double values, and the single-byte encoding will be performed on this dataset.
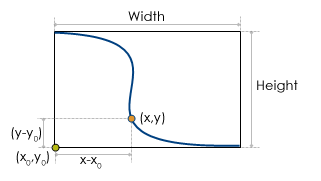
The figure shows a line object in the line dataset, and the width of the boundary rectangle is Width, the height of the boundary rectangle is Height, thus, the compression ratio of the single-byte encoding for this line object is:
ratio = max(Width,Height)/255.Here, 255 is the maximum value that can be represented by single-byte. If the coordinates of the lower-left corner of the line object are (x0,y0), for a vertex (one of the points used to form the line) in the line, whose coordinates are (x,y), its coordinates after encoding are:
x'=byte[(x-x0)/ratio]
y'=byte[(y-y0)/ratio]
The coordinates of a point is stored as byte values, so the storage space of the dataset after encoding reduces to 1/8 of that before encoding. Obviously, when the double values are encoded with byte values, the precision will loss, and in this example, the maximum loss of precision is ratio. For other encoding types of vector data, the mechanisms are similar, and the maximum loss of coordinate values after encoding is:
ratio = max(Width, Height)/maxValue
Here, Width and Height are the width and height of the boundary rectangle of the geometric object, maxValue is the maximum value that the data type of the encoding can represent (the maxValue for single-byte encoding is 255, for double-byte is 65535, for triple-byte is 16777215, and for four-byte is 4294967295).
-
-
Field Summary
Fields Modifier and Type Field and Description static EncodeTypeBYTESingle-byte encoding.static EncodeTypeDCTDCT(Discrete Cosine Transform) is a transform encoding method widely used to compress images.static EncodeTypeINT16Double-byte encoding.static EncodeTypeINT24Three-byte encoding.static EncodeTypeINT32Four-byte encoding.static EncodeTypeLZWLZW is a widely used dictionary compression method, and from the very beginning it is used in the compression of text.static EncodeTypeNONEDo not used encoding.static EncodeTypeSGLSGL (SuperMap Grid LZW) is a compression format defined by SuperMap.
-
-
-
Field Detail
-
NONE
public static final EncodeType NONE
Do not used encoding.
-
BYTE
public static final EncodeType BYTE
Single-byte encoding. After encoding, a coordinate is stored with one byte.(For vector dataset only except point and tabular dataset)
-
INT16
public static final EncodeType INT16
Double-byte encoding. After encoding, a coordinate is stored with two bytes.(For vector dataset only except point and tabular dataset)
-
INT24
public static final EncodeType INT24
Three-byte encoding. After encoding, a coordinate is stored with three bytes.(For vector dataset only except point and tabular dataset)
-
INT32
public static final EncodeType INT32
Four-byte encoding. After encoding, a coordinate is stored with four bytes.(For vector dataset only except point and tabular dataset)
-
DCT
public static final EncodeType DCT
DCT(Discrete Cosine Transform) is a transform encoding method widely used to compress images. This transform method provides a balance between compression ability, the quality of the reconstructed image, applicable scope and complexity of algorithm etc., and is the most widely used image compression technology recently. The principle of this method is to reduce the strong relativity that exists in the spatial domain representation through transformation, so that the signals can be expressed compactly. This method has got high compression ratio and performance, but the encoding will lack fidelity. For the image dataset usually not used to do some analysis, DCT encoding type often applies to image dataset. (For Image dataset only)
-
SGL
public static final EncodeType SGL
SGL (SuperMap Grid LZW) is a compression format defined by SuperMap. Actually, it is an improved LZW encoding. SGL improves the LZW encoding, and is a more effective compression and storage manner. So far, the compression or storage used for the Grid dataset and the DEM dataset in SuperMap is the SGL encoding, and it is a lossless compression. (For Grid and DEM dataset only)
-
LZW
public static final EncodeType LZW
LZW is a widely used dictionary compression method, and from the very beginning it is used in the compression of text. The principle of LZW encoding is to use certain code to replace a section of string, the following identical string will be replaced by the same code, so this method not only can compress the repeated data, but also can compress data that does not repeat. It applies to index color images, and is a lossless encoding. (For Grid, DEM or Image dataset)
-
-