



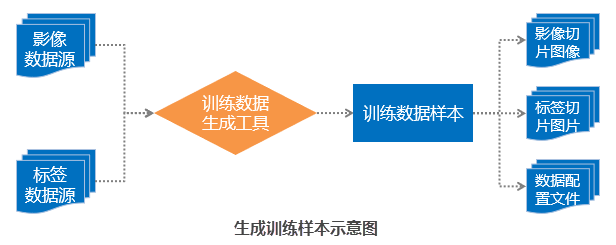
When no model exists, the Generate Training Data tool can produce required training data based on original remote sensing imagery and vector annotation data. Given the large volume of remote sensing images and high memory demands of convolutional neural networks, this tool converts raw imagery into machine learning-ready formats. Its core function is synchronously cropping imagery and label data into smaller tiles suitable for neural network training.
Training data characteristics (resolution, observation height, angle, object spacing, etc.) significantly impact model accuracy. Optimal training data should meet three criteria: large sample size, diversity, and high quality.
Data Preparation
Prepare two essential datasets before generation:
- Sample Imagery: High-resolution aerial/satellite imagery of target areas.
- Sample Tag Data: Vector polygon datasets outlining targets with attributes (e.g., aircraft identification, coordinates, model).

Generate Training Data
Operational workflow:
- Access Path: Toolbox-> Machine Learning-> Imagery Analysis-> Generate Training Data.
- Training Purpose: Select from six applications: Object Detection, Binary Classification, Multiple Classification, Scene Classification, Object Extraction, Detect Common Change.
- File Type: Choose between Dataset (default) or Folder for batch processing. Disabled for Detect Common Change.
- Sample Imagery Source: (Dataset mode) Select image/mosaic dataset. Detect Common Change requires Image Dataset.
- Folder Path: (Folder mode) Select directory containing *.tif/*.img files.
- Tag Data Source: Select vector datasource and region dataset containing labels.
- Category Field: Specify attribute field indicating target type. Disabled for Binary Classification/Detect Common Change.
- Tile Dimensions: Set equal row/column pixel values (default 1024). Recommend 64 multiples. Larger sizes increase memory usage.
- Advanced Settings:
- Output Format: Same as Input/TIFF/PNG/JPEG (JPEG mandatory for Object Detection)
- Overlap Offset: Default 0. Increase for data augmentation.
- Index Start: Default -1 appends to existing data. Custom values overwrite same-index files.
- Save Unlabeled Tiles: Optional negative sample storage.
- Comparison Imagery: (Detect Common Change only) Input change detection image dataset.
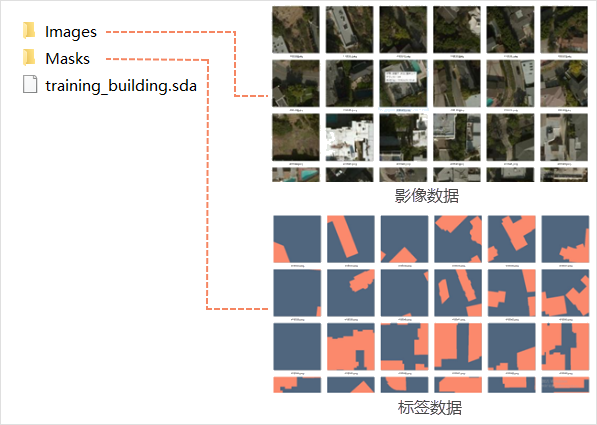
- Output Configuration: Set export directory (English-only paths) and folder name. Output includes imagery tiles, label tiles, and *.sda config file.
Related Topics
 Machine Learning Environment Configuration
Machine Learning Environment Configuration