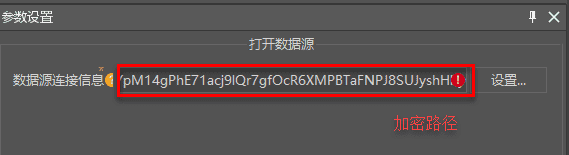
1.在10i(2021)版本中创建的模型,导入到先前版本,模型执行失败。
答:如果数据源连接信息出现乱码,如下图所示,因为10i(2021)版本出于安全考虑对数据路径进行了加密处理,先前版本无法还原加密后的路径,导致数据打开失败,请重新填写数据路径或对产品进行升级。
2.产品升级后,使用之前保存的模型,出现导入失败或连接信息丢失。
答:可能的原因及解决办法有:
(1)在 iServer 中无法导入模型,可能是浏览器缓存了先前版本的静态资源,需先清空浏览器缓存来获取更新的资源,再进行模型的导入与执行。
(2)模型执行失败,可能是产品升级对部分参数进行了优化,模型中的工具可能发生变更导致不兼容,具体变更情况请参阅”处理自动化工具参数变更”,您需要对变更工具进行重新添加并保存模型。
3.将桌面制作的模型导入到iServer中,但模型无法导入或执行失败。
答:可能的原因及解决办法有:
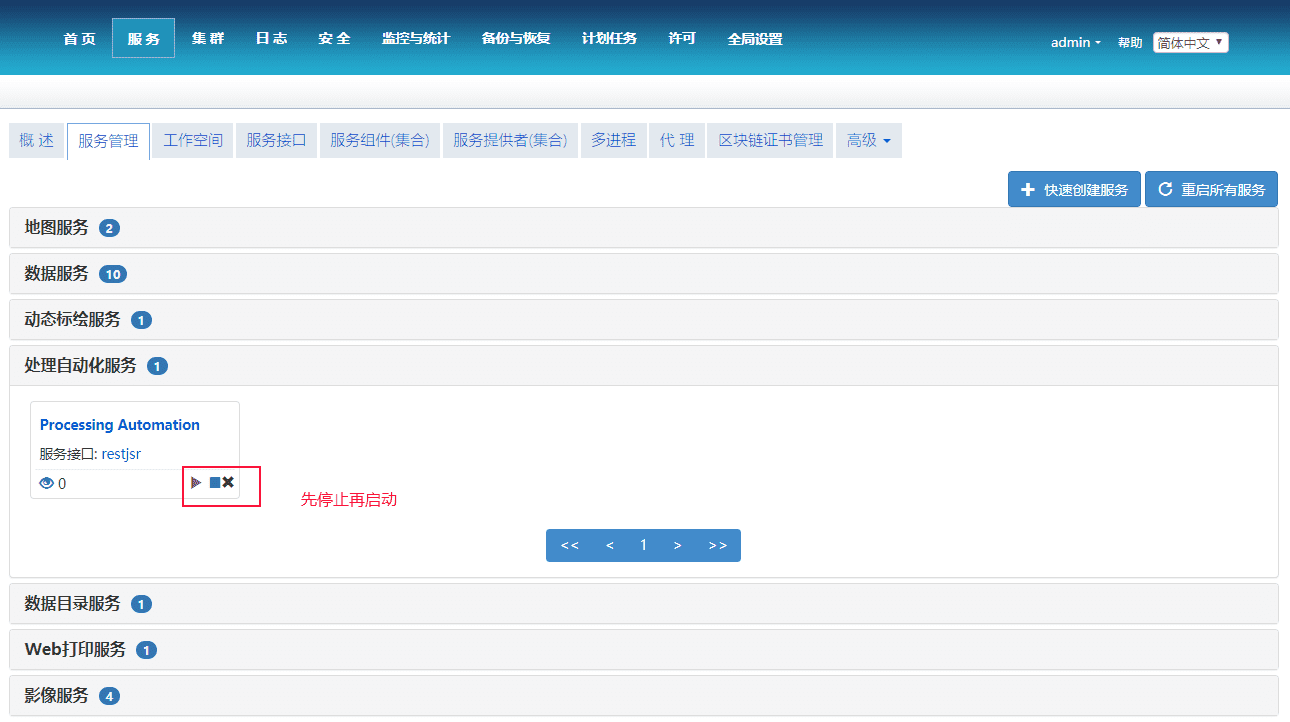
(1)在版本相同的情况下,将桌面制作的模型导入到iServer中执行失败,可能是桌面制作的模型中包含扩展开发的自定义工具,iServer无法直接使用,您需要将自定义工具.jar 文件复制到 iServer 安装路径的 \support\geoprocessing\lib 目录下,通过重新启动服务便可将自定义工具加载到工具箱中,如下:
(2)如果使用了本地数据,可能是远程 iServer 无法访问本地文件,请将数据上传至服务器并填写正确的数据连接路径或使用数据库型数据源。
4.在填写数据连接信息时遇到问题。
答:要了解如何填写数据连接信息,请参阅读取矢量数据、保存矢量数据使用说明。
5.在进行工具连接时需要注意什么?
答:连接符用于将数据和值连接到工具,其类型分为数据和前提条件。通过连接符将前一个工具的结果输出数据作为后一个工具的输入数据时,请确保前一个工具的输出类型和后一个工具的输入类型保持一致。
目前工具输出的类型主要有以下三种:
- 结果数据集(Dataset),是将同类空间数据存储在一类数据集中,作为空间数据的基本组织单位之一是传统GIS工具的输出结果数据类型。
- 结果要素数据集(FeatureRDD/RasterRDD),是基于Spark的 RDD 扩展的分布式要素数据集,是大数据读取、存储以及分析的通用模型,通常作为大数据工具的输出结果数据类型。
- 地理分区要素数据集(DSFFeatureRDD/DSFFeatureRDD),是在要素数据集的基础上提供的一种新的数据模型,适用于对海量空间数据进行分布式计算,作为大数据DSF工具的输出结果数据类型。
我们以缓冲区分析为例:
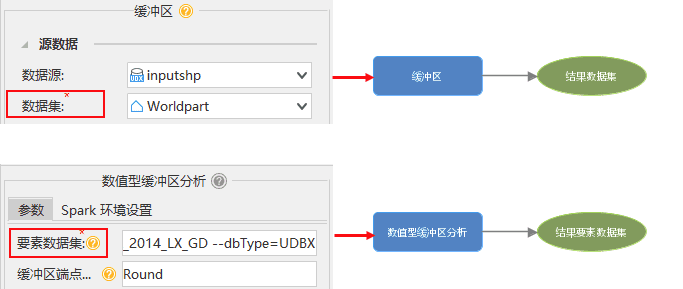
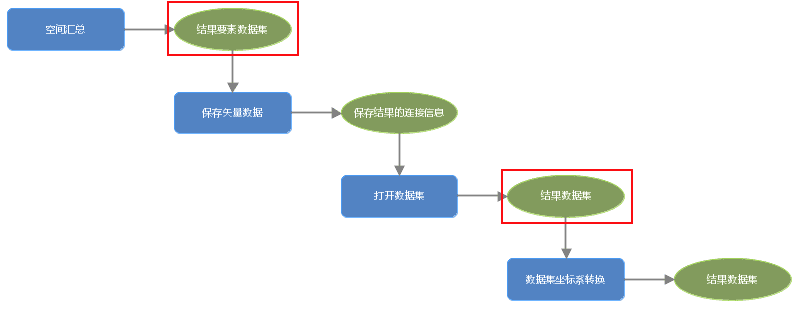
从上述的数据类型,我们可以看到传统GIS工具与大数据工具的输入与输出类型均不同,无法直接进行连接。如果单独使用传统工具或者大数据工具无法满足您的需求,如下图所示,可以通过【保存矢量数据】工具将结果要素数据集(FeatureRDD)保存到数据源当中,再通过【打开数据源】或者【打开数据集】工具,获取数据连接信息作为后续工具的输入。
6.如何提升模型运算效率?
答:当数据量较大时,模型运算耗时较长,希望提升运算效率可以从以下两个方面进行优化:
(1)使用集群环境:在使用处理自动化工具中的大数据工具时,您可以选择使用分布式集群环境进行算法功能的计算,从而提升大批量数据的计算效率,具体使用方法请参阅处理自动化工具说明。
(2)优化模型:您可以使用 DSF 相关工具,通过基于空间格网建立空间索引的方式,有针对性地优化读写存储在HDFS上的经典空间数据的性能,使得接入 Spark 分布式计算的大体量经典空间数据分析性能显著提升。
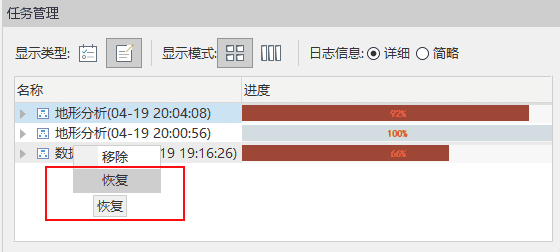
7.在桌面构建模型时,没有保存直接执行,执行过程中出现崩溃导致模型丢失怎么办?
答:重启桌面,打开任务管理器,找到刚刚执行的任务,即可一键恢复尚未保存的模型。