迭代循环,是指自动地重复某个过程。迭代循环主要用于需要自动执行重复任务的情况,相比于手动执行重复任务,迭代循环能够极大节省执行任务所需的时间和精力。迭代循环分为两种模式,分别是配对循环和嵌套循环。默认模式为配对循环。
- 配对循环:即对集合数据中的每个数据按顺序进行一对一的匹配。需要注意的是,当元素的个数分别为 m,n 个时,执行的次数为 m,n 中的最小值。即 m>n 时,循环只会执行 n 次。
- 嵌套循环:即对集合数据中的每个数据进行交叉循环匹配。
操作说明
1.首先将集合数据集连接到单值输入上。
2.鼠标右键工具节点-迭代模式-配对循环/嵌套循环。
3.需要注意的是,迭代循坏只有在多重循环下使用,才会有意义。
4.迭代循环只有在单值输入的情况下使用,才具有意义,否则不能得出正确的迭代结果。
各种使用场景
1.迭代数据集批量处理。
2.集合型数据集批量处理。
3.与集合型变量结合使用,实现批量处理。
4.与行内变量结合使用,实现批量处理。
使用场景一:迭代数据集批量处理
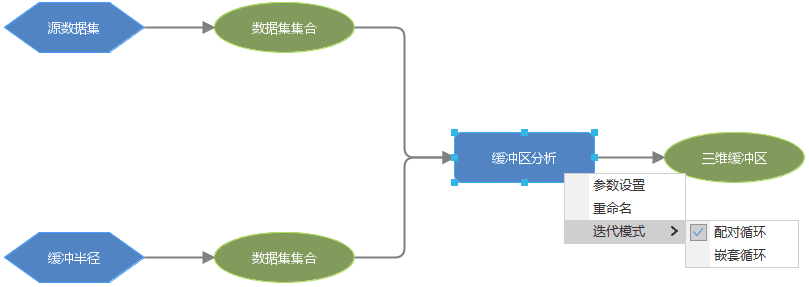
当数据源中的数据集数量非常大时,可以使用迭代数据集对数据进行批量处理。对迭代数据集进行迭代循环时,可根据实际情况,选择迭代模式,实现迭代批处理。在下方模型中,需要对迭代数据集进行缓冲区分析,当两个迭代数据集连接在缓冲区分析工具节点时,即可选择迭代模式,之后模型运行时就可以对两个迭代数据集进行配对循环/嵌套循环。
使用场景二: 集合型数据集批量处理
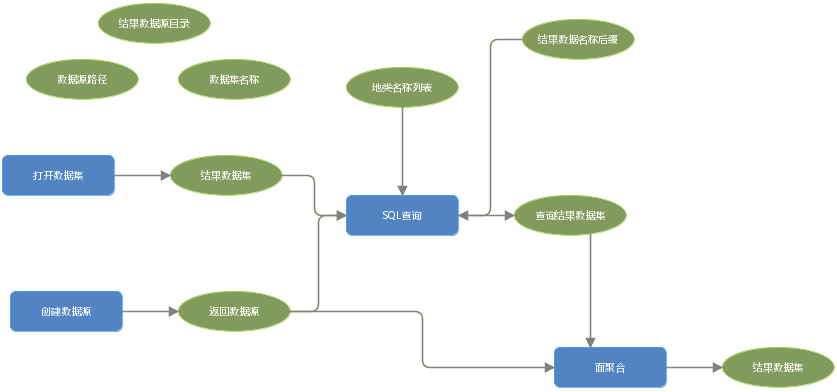
当数据类型多样且数据量大时,迭代模式还可以在输出类型为集合型的数据集中使用。如下方模型是根据图斑类型拆分成不同数据集。在对数据集根据不同图斑类型进行【SQL查询】后,可对【SQL查询】后得到的集合型数据集,在【面闭合】的工作节点进行迭代模式的选择。
使用场景三:集合型变量批量处理
变量支持创建集合数据,可批量设置多个数据。同时集合型变量支持跨数据源选择数据,通过使用迭代循环,可以实现批处理。
-
创建集合型变量:点击”处理自动化“选项卡,选择”变量“组,下拉菜单中将显示可在模型中使用的所有数据类型的列表,包含布尔型、长整型、单精度等多种类型。根据实际情况,选择所需要的数据类型,勾选集合选项,则可在工具属性面板通过“添加”按钮,设置多个数据。
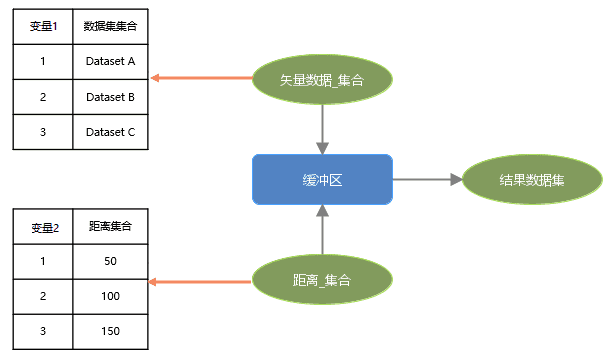
如下图需要对某区域的三个数据分别做缓冲区分析,创建类型为矢量数据集的集合型变量,分别添加三个矢量数据集;将缓冲距离,分别设置 50、100、150 三个距离;在画布中构建得到如下模型:
-
当创建集合型变量时,支持对引用节点的工具设置迭代模式,选中工具节点,鼠标右键弹出菜单项,可选择配对/嵌套循环两种迭代模式:
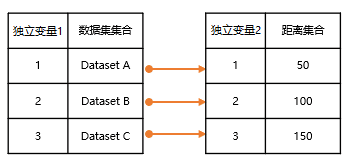
- 配对循环。如下图所示,按照数据对应关系,Dataset A 对应距离 50;Dataset B 对应距离 100;Dataset C 对应距离 150 分别进行缓冲区分析,最终得到三个结果。
-
嵌套循环。如下图所示,Dataset A 按照 50、100、150 做三次分析、同理 Dataset B、Dataset C 也分别会按照三个距离做分析,最终得到九个结果。

-
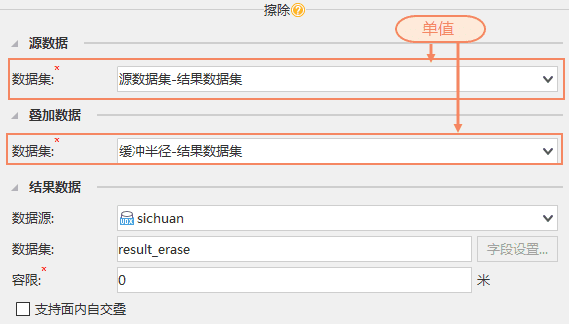
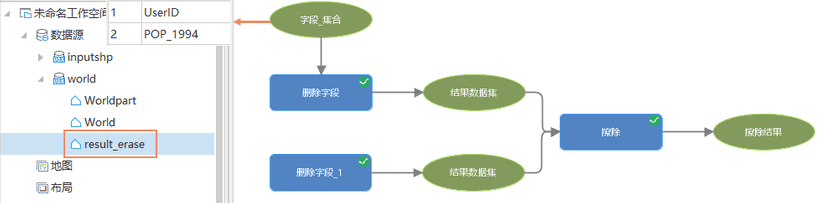
对源数据进行批量处理,有时只需要输出一个结果数据集。如下图所示,批量删除Worldpart数据集中的UserID和POP_1994字段,再将Worldpart数据集从World数据中擦除。按照嵌套循环的原理,擦除会执行两次生成两个相同的结果数据集。但为了避免资源浪费,支持对计算结果进行智能去重,最终得到一个结果数据集。

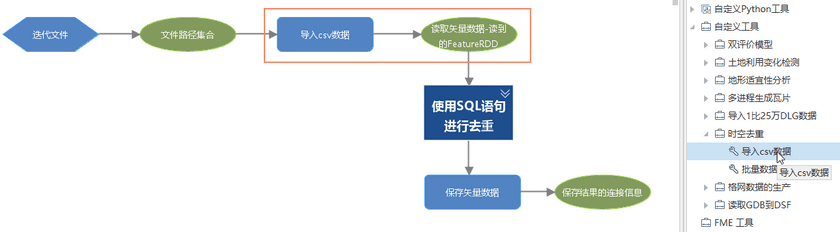
使用场景四:与行内变量结合使用,批量导入csv数据
对数据集或者数据文件进行批量处理时,有些场景下需要将迭代循环和行内变量替换结合使用。例如,批量导入csv数据时,使用【迭代文件】连接【读取矢量数据】后,无法再设置坐标系信息。这时,我们就需要使用行内变量替换文件路径。然而,工具直接连接时才能进行迭代循环,我们可以将需要迭代循环的内容,做成一个单独的工具,然后嵌套使用,具体步骤如下:
-
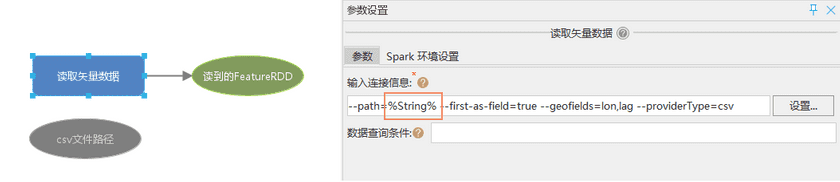
创建文件路径类型的变量,将变量重命名为【csv文件路径】,接着使用行内变量替换【读取矢量数据】连接信息中的“文件路径”,并在高级设置中设置坐标信息。最后将模型通过“保存为工具”或者“发布模型”,保存到桌面工具箱或者iServer GPA WebUI的工具列表中,以便后续在模型中复用该工具。
-
将保存的工具【导入csv数据】拖拽到画布上,接着将【迭代文件】的输出连接至【导入csv数据】的“csv文件路径”参数上,后续使用SQL语句对数据进行时空去重,这里为了方便理解将相关工具添加分组并进行折叠,最后将矢量数据进行保存。