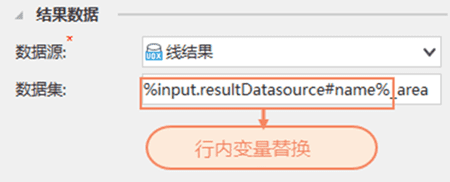
在模型构建器中,行内变量替换用百分号 (%**%) 括起来的方式进行表达。行内变量替换能够替换输入参数的部分内容。在模型构建时灵活使用行内变量替换能够大大减轻我们的工作量,达到数据处理规范化、模型复用率更高的目的。同时,在选择对应的行内变量替换后,也可输入 ’#’, 即能自动显示出可用的属性列表,选择需要的属性即组成了完整的行内变量替换。
行内变量替换的各种使用方式
-
一个完整的行内变量替换需要使用 ’%’ 括起来。 在文本框内输入’%‘,即可自动显示可引用的参数列表。

-
根据具体情况,在选择对应的行内变量替换后,也可输入 ’#’, 即能自动显示出可用的具体属性。

-
行内变量替换可在工具参数界面的所有文本框中使用,如结果数据名、SQL 查询语句等。

-
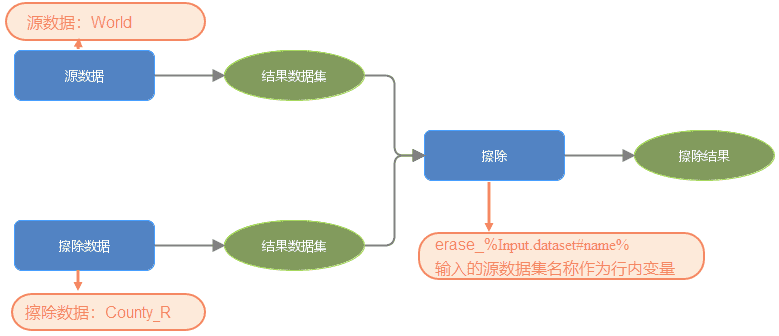
行内变量替换支持在字符串型变量前后增加字符串,组成新的字符串。在下方模型中,对擦除分析的结果数据集命名使用行内变量替换。%input.dataset% 指代源数据集,#name 指代名称,二者结合 %input.dataset#name% 就表示源数据集的名称。源数据集名为 “World”,因此,模型执行时将使用 %input.dataset#name% 来替换 “World” ,使用字符串 ”“,将结果数据集名称输出为 “eraseWorld”。
-
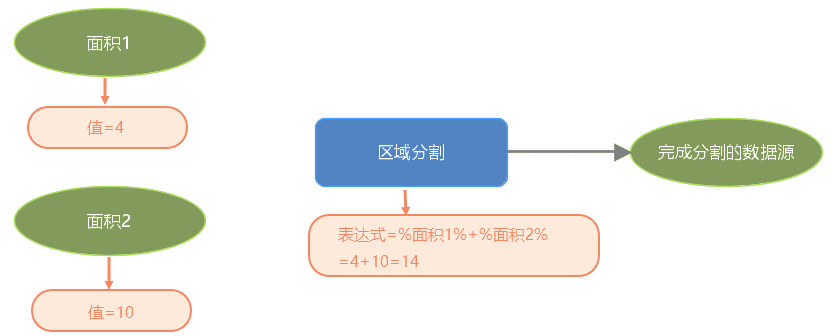
行内变量替换支持在数值型变量前后使用四则运算,生成新的数值。如:当需要计算某一区域的分割时,可以参考下方模型。本模型中含有两个变量,分别是面积1和面积2,这两个变量都是双精度类型。在运行区域分割工具时,变量的名称就会被替换为所指定的值,面积1会被替换为“4”,面积2会被替换为“10”,最后区域分割的面积大小即为这两个值相加后的值“14”。
典型的使用场景有:
- 行内变量与变量结合使用,能够将变量作为全局变量应用到模型的不同工具中。
- 行内变量替换与迭代工具结合使用,能够规范批量处理的结果数据名,使得数据结果可查可追溯。
- 行内变量替换在 SQL 查询语句中使用,在输入数据改变时,无需频繁修改 SQL 语句,使得模型复用率更高。
使用场景一:变量作为全局变量
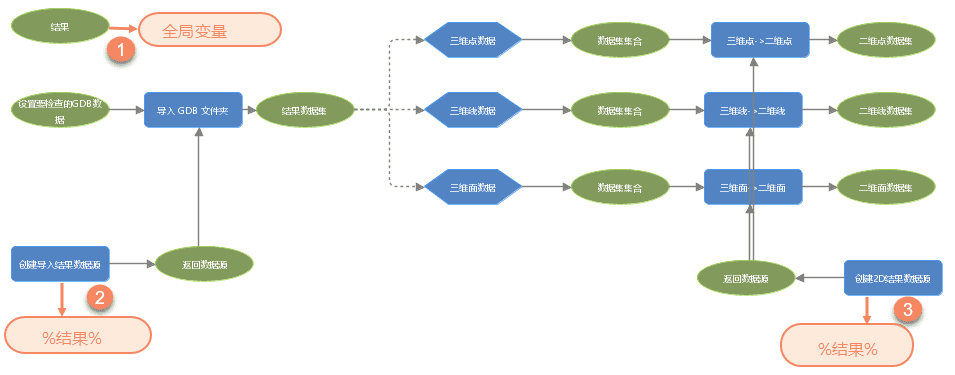
变量在模型中主要用于存放数据。当模型过于复杂时,可在模型中添加变量作为其他工具的参数,以此来简化模型。在下方模型中,需要将 gdb 数据转为 udbx 数据,并且将 gdb 数据中的三维数据转为二维数据。本模型中的变量 “结果” 为全局变量,设置了“结果”的存储路径,之后对 “创建导入结果数据源”和“创建 2D 结果数据源”使用行内变量替换 %结果%,最后的在模型运行的时候,所有的运行结果都会被行内变量替换。当需要修改运行结果的存储位置时,只需要修改“结果”的参数即可。
使用场景二:输入数据文件名替换结果数据名
将 shapefile 文件导入到 udbx 中时,可以选择文件名作为行内变量。在以下模型中,输入数据路径为 E:\BETA\Road.shp,输出结果数据集使用 %input.sourceFilePath% 指代输入路径,#fileName 指代文件名称,因此,模型执行时会将 “Road” 文件名替代 %input.sourceFilePath#fileName%,输出数据集名称为 “Road”。


使用场景三:批量处理中规范结果数据名
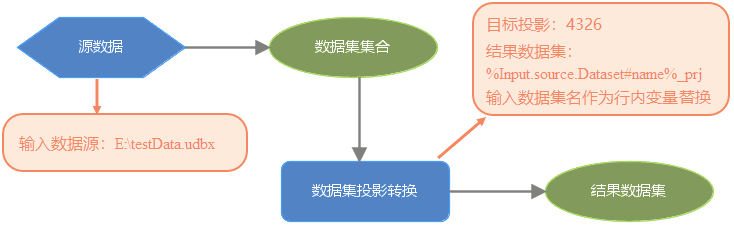
当需要对数据源中的数据集或者数据文件进行批量处理时,通常会使用“迭代数据集”或“迭代文件”。行内变量替换与“迭代数据集”或“迭代文件”结合使用,能够对批量数据处理的结果进行规范命名。在下方模型中,对 testData.udbx 数据源中所有数据集做批量投影转换处理,在对投影转换的结果数据集命名时,使用 %input.sourceDataset#name% 指代输入数据集的名称,通过【迭代数据集】工具对 udbx 数据源中的数据集进行遍历,得到的结果为每个输入数据集名加 “_prj” 组成的新数据集名。
操作说明:
在需使用行内变量替换的参数框中输入’%‘,程序会自动弹出可引用的参数列表,选择参数即可。通常指定的是参数的路径或数据集,如需再指定该参数(路径或数据集)下具体的属性,可再输入连接符 ’#‘,会自动弹出可引用的属性列表,选择需要的属性即组成了完整的行内变量替换。
例如:在使用迭代器进行批量数据处理时,对于每个迭代文件都会输出一个结果,可以将输入数据文件的名称作为行内变量替换,替换输出结果的数据集名称,以便更好的识别数据结果文件。
附录-行内变量替换支持的数据类型与属性
| 数据类型 | 属性英文名 | 属性中文名 |
|---|---|---|
| 栅格数据集 | name datasetType encodeType bounds datasource prjCoordSys width height maxValue minValue noValue pixelFormat |
名称 数据集类型 编码类型 范围 数据源 投影系统 宽度 高度 最大值 最小值 无值 像素格式 |
| 影像数据集 | name datasetType encodeType bounds datasource prjCoordSys width height bandCount |
名称 数据集类型 编码类型 范围 数据源 投影系统 宽度 高度 波段个数 |
| 矢量数据集 | name datasetType encodeType bounds datasource prjCoordSys fieldCount recordCount charset spatialIndexType |
名称 数据集类型 编码类型 范围 数据源 投影系统 字段数 记录数 字符集 空间索引类型 |
| 数据源 | name engineType prjCoordSys workspace |
名称 数据源类型 投影系统 工作空间 |
| 字段 | name caption type |
名称 字段别名 字段类型 |
| 工作空间 | name type |
名称 工作空间类型 |
| 点几何对象 | X Y |
X Y |
| 线几何对象 | bounds inner length |
范围 内点 长度 |
| 面几何对象 | bounds inner area perimeter |
范围 内点 面积 周长 |
| 投影系统 | name epsg |
名称 EPSG |
| 双精度 | hex octal binary round ceil floor |
十六进制 八进制 二进制 取整(四舍五入) 向上取整 向下取整 |
| 单精度 | hex octal binary round ceil floor |
十六进制 八进制 二进制 取整(四舍五入) 向上取整 向下取整 |
| 整型 | hex octal binary |
十六进制 八进制 二进制 |
| 长整型 | hex octal binary |
十六进制 八进制 二进制 |
| 字符串 | length upperCase lowerCase |
长度 大写 小写 |
| 文件路径 | fileName fileExtension parentFile |
文件名 扩展名 父目录 |