



Query time refers to the time required to query the objects to be displayed in the current Map from the Dataset, which is generally related to the data structure of Vector Data. Its time-consuming optimization can be started from the aspects of Spatial Index, data coding, etc., as follows:
- Spatial Index
With the increasing amount of GIS data, the access speed of Spatial Data is reduced, and Spatial Index is a data structure used to improve the efficiency of Spatial Query. It is the DatasetCreate Spatial Index displayed in the map, which can improve the efficiency of map browsing and query. It is recommended to use R-tree Index and Mapsheet Index ( Note: File Database only supports R-tree Index).
- R-tree Index
Advantages: Highest query performance in general use. However, for some specially organized data, Mapsheet Index + local cache is the fastest.
Disadvantages: The concurrent support is poor, so it is generally only used for the exclusive File Database, but not for the Database-type Datasource that requires frequent concurrent editing; the maintenance cost is high, and the index creation time is long.
Note: For static data, the advantage of R-tree is obvious.
- Q-tree Index
Advantages: Better concurrency support and faster indexing.
Disadvantages: Query performance is lower than R-Tree.
It is recommended to use Dynamic Index instead of quadtree.
- Dynamic Index
Advantages: good concurrency support, fast indexing, and support for large amounts of data. The size of each level of the grid can be customized and is not limited by Dataset Bounds. It is suitable for Database-type Datasource, and its performance is slightly lower than Mapsheet Index in the case of large data volume and read-only.
- Mapsheet Index
For some applications, Mapsheet Index is the fastest one, which is most suitable for regularly divided data, such as 1: 250,000 or 1: 100,000 national Basic Scale topographic maps numbered by standard map sheets. For ordinary data, if Mapsheet Index is used, it will also bring performance improvement. The Mapsheet Index is for the database Datasource. Create a Mapsheet Index for a Vector Dataset based on a range or a field. Mapsheet Index is created with the field representing the area to which the object belongs, or when creating by range, the number of records in each block should be as average as possible, for example, there are 2000 to 20000 objects in each block, and the range should not be too large or too small, so the effect is very good. General recommended range: 30 × 30, i.e. 900 grids, which is suitable for Dataset with 100,000 records. If the actual data is different, you need to modify the length and width of the range.
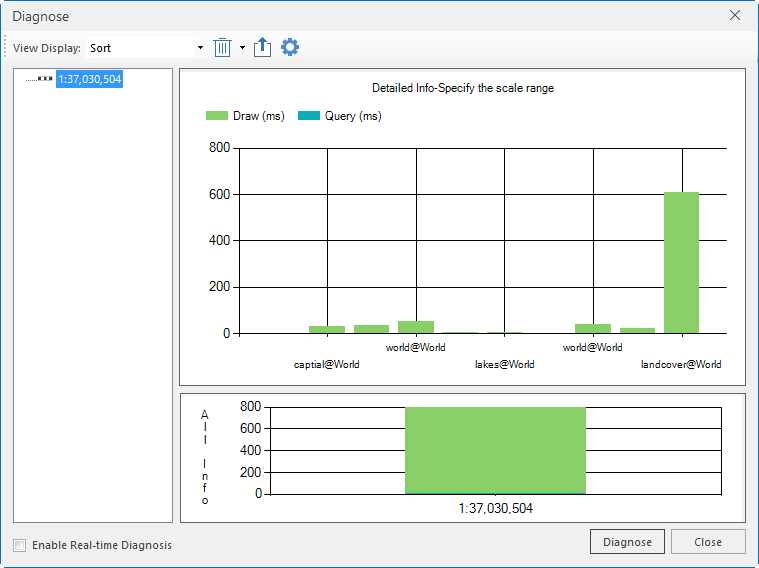
As shown in the figure below, the map query efficiency is different before and after the establishment of Spatial Index for road network data. The query time is 36 ms before the establishment of Spatial Index and 2 ms after the establishment of R-tree Index. The efficiency of map browsing has been significantly improved.
- R-tree Index
- Data Encoding
- Map Cache Map Cache is generally used for browsing when the map is used
in the browser and server (B/S). In the case of Publich Service, it is recommended to publish Cache Data (save the cache sci as a Workspace) instead of the original Workspace. Publish Cache reads cached images directly, while Publish Workspace needs to read the location of the images, which is a big difference in performance.
Data encoding is a concept of compression, similar to ZIP, RAR, etc. Dataset encoding can reduce the amount of data, which can greatly improve the efficiency of disk reading and writing and network transmission, and significantly improve performance. DatasetEncode Type can be modified by functions such as Create Dataset, Copy Dataset, Import Dataset, and Export Image Dataset. The Vector Dataset has a variety of Encode types, such as single-byte, double-byte, three-byte, and four-byte. Note that points, attribute tables, and CAD Datasets are not compression-coded.
Executive summary
 Time consuming optimization of data acquisition
Time consuming optimization of data acquisition
Draw time consuming optimization