



Feature Description
The point clustering function refers to the algorithm based on density-based clustering, which divides points with relatively dense spatial distribution into a cluster and forms a polygon from the same cluster of points. After point clustering, a 'ResultType' field is generated in the source dataset to record clustering category information.
Application Scenarios
This function is suitable for large-volume data, used for classifying points based on the closeness of their spatial relationships, removing noise points, and constructing tightly clustered points geographically into polygon objects. Specific application scenarios are as follows:
- Removing noise points from point cloud data: During the acquisition of point cloud data, it is affected and interfered by factors such as human, instruments, environment, and measurement methods, resulting in noise points in the acquired data. The point cloud of the measured object is usually continuously distributed along the surface, while noise points are typically located outside the point cloud with random distribution. Therefore, noise points can be removed using the aggregate points function.
- Building areas with weak signals based on communication signal monitoring data: The communication monitoring system monitors signal strength in real-time. Points with signals below a certain threshold can be extracted based on signal strength, and areas with weak signals can be constructed using the density-based clustering function, serving as a reference for the location of new signal towers.
Function Entrances
- Data Tab -> Data Processing -> Vector -> Point Clustering.
- Toolbox -> Data Processing -> Vector -> Point Clustering.
Parameter description
- Source Dataset: Used to display and set the point dataset for density-based clustering and the data source it belongs to.
- Cluster Radius: Sets the radius for aggregating points. It indicates that when the number of points within the specified radius is no less than the threshold, these points are considered as one category, and they share the same attribute value in the newly added 'ResultType' field in the original dataset.
- Distance unit: Used to set the unit of the cluster radius.
- Point Count Threshold: Used to display and set the minimum number of points required to form a cluster. This value must be greater than or equal to 2. A larger threshold indicates stricter conditions for clustering. The recommended value is 4.
- Result Data: Used to display and set the result dataset and the data source to save it to.
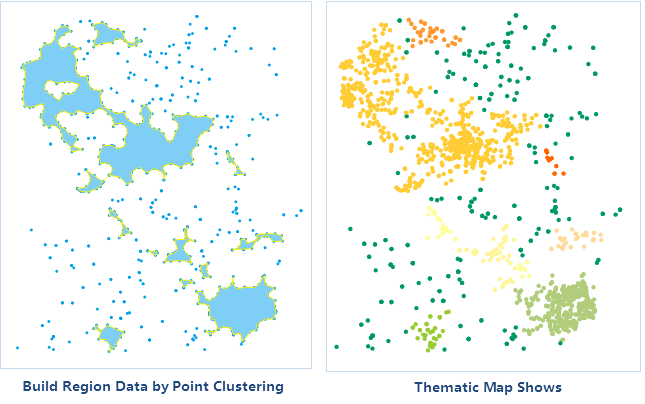
After successful execution, the output window will display corresponding prompts, indicating the field name in the dataset where the clustering categories are saved. The obtained aggregate result is shown in the figure below. As shown, points that cannot form a polygon are discrete points (noise points), specifically the dark green points in the right figure, with their 'ResultType' attribute value being 0.
Related Topics