使用说明
驻留分析是对含有时间信息的点数据集,使用密度聚类(DBSCAN)算法或方形格网进行空间维度的聚类。密度聚类要求点数目的阈值大于1。在使用密度聚类时,可能会产生不属于任何类的孤立点(噪声点),每个孤立点在计算驻留点时将会单独作为一个点簇。结果返回一个点数据集,点数据集中将保留点标识字段值和时间间隔值和。返回的结果类型为要素数据集(FeatureRDD)。
以下为驻留分析示意图:
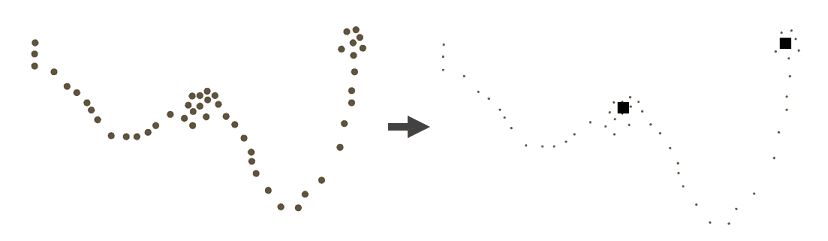
分析原理
方形格网聚类基本原理是基于网格聚合算法,通过网格对地图点要素进行网格划分,然后,计算每个网格单元内点要素的数量,并作为网格的统计值,也可以引入点的权重信息,考虑网格单元内点的加权值作为网格的统计值。
密度聚类方法 DBSCAN,它能将具有足够高密度的区域划分为簇,并可以在带有噪声的空间数据中发现任意形状的聚类。它定义簇为密度相连的点的最大集合。DBSCAN 使用点数目阈值和聚类半径(e)来控制簇的生成。其中,给定对象半径内的区域称为该对象的 e一邻域。如果一个对象的 e一邻域至少包含最小数目 MinPtS 个对象,则称该对象为核心对象。给定一个对象集合 D,如果 P 是在 Q 的 e一邻域内,而 Q 是一个核心对象,我们说对象 P 从对象 Q 出发是直接密度可达的。DBSCAN 通过检查数据中每个点的 e-领域来寻找聚类,如果一个点 P 的 e-领域包含多于 MinPts 个点,则创建一个以 P 作为核心对象的新簇,然后,DBSCAN反复地寻找从这些核心对象直接密度可达的对象并加入该簇,直到没有新的点可以被添加。
应用场景
- 对大量手机信令数据进行计算,包含用户ID、时间、位置等信息,分析出每个用户驻留时间最长的K个位置。
参数说明
| 参数名 | 默认值 | 参数释义 | 参数类型 |
|---|---|---|---|
| 原始点数据集 | 原始点数据集 | FeatureRDD | |
| 点标识字段 | 点标识字段,具有相同标识的点划分为一组,例如,手机号 | String | |
| 用于标识要素时间的字段 | 用于标识要素时间的字段,时间字段没有设置时,将会默认从要素数据集中找默认的时间字段,如果没有默认的时间字段,将会抛出异常。 | String | |
| 常驻位置数 | 0 | 同一标识点取 maxTop 个常驻位置 | Integer |
| 密度聚类半径 | 如果设置了minPilePoints 且 minPilePoints 大于1,则空间聚类使用密度聚类 (DBSCAN),radius 表示密度聚类半径,否则使用方形格网聚类,radius 表示格网的宽度。填写示例:30.0 Meter。 | JavaDistance | |
| 密度聚类点数目阈值 | 0 | 如果空间聚类需要使用密度聚类,则需要设置此参数大于等于2,表示密度聚类点最小数目阈值。如果 minPilePoints 小于2,则空间聚类会使用方形格网聚类。 | Integer |
| 时间权重 (可选) |
时间权重,时间权重值的每一项为时间段(没有日期)对应的权重值,例如,对于8点到9:59:59可以设置时间权重为1。10点到12点,可以设置权重值为2,这样,在计算时,对于属于指定时间区间的时刻长度,将会乘以时间权重值作为最后选择最长驻留时间的依据。不在指定的时间权重区间内权重值为1。如果指定的时间权重区间有重叠,会取权重值大的值作为这个时间区间的权重值,例如,如果指定8点到10点权重为1,9点到12点为10,那9点到10点的权重为10,8点到8:59:59的时间权重为1.设置格式如“08:00:00,09:59:59,10” | JavaLocalTimeWeight | |
| 驻留点返回的结果的类型 | MeanCenter表示返回平均中心,ConvexHull表示返回凸包面,StayLocations表示返回所有停留点 | JavaStayLocationResultType |