



Feature Description
Ordinary kriging is the most common and widely used kriging method. It assumes that the expectation (mean) of the field values used for interpolation is unknown and constant.
- The data used in ordinary kriging should satisfy the prerequisite assumption that the data variation follows a normal distribution.
- The most significant feature of ordinary kriging interpolation is not only providing a prediction value with minimal estimation error but also clearly indicating the magnitude of the error.
- Ordinary kriging employs two approaches to obtain sample points for interpolation, thereby deriving prediction values at corresponding locations: one is to retrieve all sample points within a specified range around the location where the prediction value is to be calculated, using a specific interpolation formula to obtain the prediction value; the other is to acquire a fixed number of sample points around the location, using a specific interpolation formula to obtain the prediction value.
Open the 'Precipitation' data source in the 'ExerciseData/RasterAnalysis' folder, which contains precipitation data from meteorological monitoring stations in some areas. We use this data as an example.
Functional Entry
- Spatial Analysis tab->Raster Analysis group->Interpolation Analysis->Ordinary Kriging.
- Toolbox->Raster Analysis->Interpolation Analysis->Ordinary Kriging.
Parameter description
Fixed Count: Indicates using a fixed number of sample points within the maximum radius for interpolation.
- Set common parameters for interpolation analysis, including source data, bounds, result data, and environment settings. For settings of common parameters such as source data, bounds, and result data, please refer to: Common Parameter Description.
- Set the sample point search method: Supports fixed count, fixed radius, and block search. For detailed descriptions of these search methods, please refer to: About Interpolation.
- Maximum Radius: Enter the radius size for fixed count. The default value is 0, meaning using the maximum radius for search.
- Number of Search Points: Enter the number of points for fixed count. The default is 12 points.
Fixed Radius: All points within the search radius must participate in the interpolation operation.
- Search Radius: Enter the search radius size. The default search radius is 1/5 of the larger value of the length or width of the dataset involved in interpolation analysis. All sample points within this radius must participate in the interpolation operation.
- Minimum Points: Enter the minimum number of points for fixed count. The default is 5 points. When the number of points in the neighborhood is less than the specified minimum, the search radius will continuously increase until it can include the input minimum number of points. The maximum value is 12.
Block: Divide the dataset into blocks based on the set "Maximum Points per Block", then use points within the block for interpolation operation.
The settings of the "Maximum Participation Points" and "Maximum Points per Block" parameters directly affect the performance of block search. The larger these two values are set, the longer the search time will be. Therefore, it is recommended that users set reasonable parameters when configuring block search settings.
- Maximum Participation Points: Enter the maximum number of points participating in interpolation. The default maximum is 200. To avoid crack zones during interpolation, the interpolation block used in actual calculation will expand uniformly outward based on each block region. The "Maximum Participation Points" determines the size of the outward expansion of the block region. Generally, this value should be greater than the set "Maximum Points per Block".
- Maximum Points per Block: Enter the maximum number of points within each block. The default maximum is 50. If the number of points within a block exceeds this value, it continues to subdivide; otherwise, it stops subdividing.
- Other Parameters: Include semi-variogram, rotation angle, mean, sill, range, nugget effect value, etc.
Semi-variogram: Supports three types of semi-variograms: spherical, exponential, and Gaussian. Which model to use depends on the spatial autocorrelation of the data and prior knowledge of the data phenomenon. The default is spherical function.
Rotate: The angle by which each search neighborhood rotates counterclockwise relative to the horizontal direction. Default is 0 degrees. Block search does not support rotation settings.
Sill: The peak value reached by the semi-variogram, i.e., the value where the semi-variogram intersects the Y-axis when the distance (X-axis) is 0. Default is 0.
Range: The distance at which the semi-variogram reaches the sill, i.e., the corresponding value on the X-axis. Default is 0.
Nugget Effect Value: The value where the semi-variogram intersects the Y-axis when h=0 (X-axis). Default is 0.
For the relationship among the three parameters: sill, range, and nugget effect, please refer to: Kriging Interpolation.
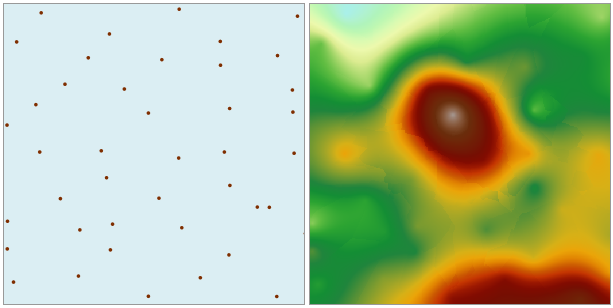 |
| Figure: Ordinary Kriging Interpolation Result |