



Inverse Distance Weighted (IDW) Interpolation
Feature Description
Inverse Distance Weighted (IDW) interpolation estimates cell values by calculating the weighted mean of neighboring sample points based on their spatial similarity, ultimately generating a continuous surface.
- The source dataset must contain a numeric field as the interpolation field.
- IDW is a precise interpolation method suitable for uniformly distributed sample point datasets where point density reflects local variations.
- IDW uses weighted mean distances between sample points. The interpolated values cannot exceed the input maximum or minimum, ensuring all raster values in the result data remain within the sample data range.
- If known observation points lack local extremes (e.g., mountain peaks), interpolated values at those locations may inaccurately appear lower than surrounding points. Therefore, sample datasets should ideally include maximum and minimum values of the study area.
Open the "Precipitation" datasource in the "ExerciseData/RasterAnalysis" folder, which contains precipitation data from meteorological stations. This dataset will be used as an example.
Feature Entry
- Spatial Analysis Tab->Raster Analysis group->Interpolation Analysis->Inverse Distance Weighted (IDW).
- Toolbox->Raster Analysis->Interpolation Analysis->Inverse Distance Weighted (IDW).
Parameter Description
Fixed Count: Uses a fixed number of sample points within the maximum radius for interpolation.
Fixed Radius: All points within the specified radius participate in interpolation.
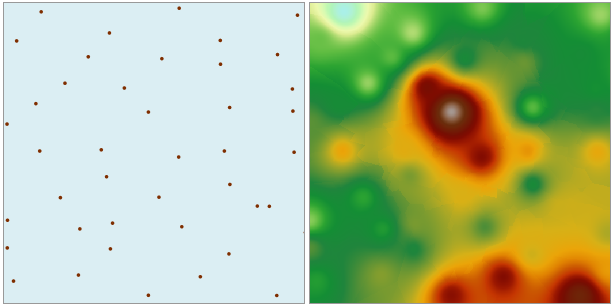 |
| Figure: Inverse Distance Weighted (IDW) Interpolation Result |
- Set common parameters for interpolation analysis, including source data, bounds, result data, and environment settings. For details about these parameters, see: Common Parameter Description.
- Set sample point search mode: supports Fixed Count and Fixed Radius. For detailed explanations, see: Inverse Distance Weighted (IDW) Interpolation.
- Maximum Radius: Defines the search radius for Fixed Count. Default is 0 (uses maximum radius).
- Search Points: Specifies the number of sample points. Default is 12.
- Search Radius: Defines the search radius. Default is 1/5 of the longer side of the dataset extent.
- Minimum Points: Specifies the minimum required points. Default is 5. If fewer points are found, the radius expands until meeting this threshold. Maximum is 12.
- Power: The exponent controlling distance weight influence. Must be a positive integer. Default is 2.