本指南主要用于希望使用SuperMap iServer Geoprocessing Modeler或SuperMap iDesktopX工具箱进行地理处理模型搭建,且现有工具无法满足功能需求的用户。您可跟随本指南完成地理处理工具的自定义扩展,并掌握在 SuperMap iServer Geoprocessing Modeler或SuperMap iDesktopX工具箱中投入使用的步骤。在此之前您需要了解:
- 在使用本指南前,您需要具备Maven仓库的使用、Scala或Java代码开发以及如何构建JAR文件的背景知识。
- 扩展开发的实现基于SuperMap SPS扩展机制来完成,在自定义工具的实现过程中,您能够使用SuperMap iObjects Java或SuperMap iObjects for Spark 中提供的空间分析算法。
- 扩展的工具能够在SuperMap iServer Geoprocessing Modeler或SuperMap iDesktopX工具箱的可视化界面中被发现和自动生成工具参数设置界面,并能与其他的地理处理工具连接完成模型搭建,省去了操作界面的开发过程,降低了自定义工具的使用门槛。
-
本指南可与示例代码sps-geocoder共同使用,示例代码提供地理编码功能,将地址文本文件转为带有经纬度信息的空间文件。示例代码在产品中的位置:
- %SuperMap iServer_HOME%\samples\code\sps\samplecode\sps-geocoder
- %SuperMap iDesktopX_HOME%\template\sps\samplecode\sps-geocoder
可点击此处下载SampleCode和数据。
1. 扩展开发步骤
1.1. 添加Maven项目依赖
https://maven.supermap.io 是超图官方为开发者提供的 maven 仓库,方便您使用 SuperMap 相关产品进行扩展开发。
仓库包含 SuperMap iServer、SuperMap iObjects 等相关 Jar 和其所依赖的第三方库。通过在 pom 文件中添加 SuperMap maven仓库,您可以将开发使用到的依赖项直接添加到 maven 项目中,避免使用 SuperMap 相关产品时遇到的第三方依赖缺失问题。
在 pom.xml 中添加如下
<repositories>
<repository>
<id>iserver</id>
<name>iserver</name>
<url>https://maven.supermap.io/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
<releases>
<enabled>true</enabled>
</releases>
</repository>
</repositories>接下来,需要在pom.xml文件中添加扩展开发需要的依赖项。sps-core为扩展开发主要的依赖项,在SuperMap
Maven仓库中可以自动找到,您只需要在pom文件中的添加一个
<dependency>
<groupId>com.supermap.sps</groupId>
<artifactId>sps-core</artifactId>
<version>1.0</version>
</dependency>注:当扩展的算法需要使用Spark分布式计算时,还需要依赖SuperMap iObjects for Spark提供的bdt- processing项目,在SuperMap Maven仓库中可以自动找到,在pom文件中的添加方法为:
<dependency>
<groupId>com.supermap.bdt</groupId>
<artifactId>bdt-processing</artifactId>
<version>10.1.0-SNAPSHOT</version>
</dependency>1.2. 创建自定义工具相关类型
新建的自定义工具类需继承自com.supermap.sps.impl.annotated. AnnotatedProcessBean类。
注:当使用Spark分布式计算时,需继承自com.supermap.bdt.processing.sps.BDTAnnotatedBean类,即可在类的execute函数内使用SuperMap iObjects for Spark产品提供的API进行扩展开发(开发指南参见《SuperMap iObjects for Spark 编程指南》)。并能够支持在处理自动化界面中设置工具的分布式集群参数。
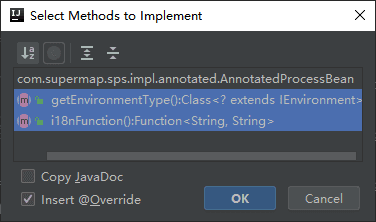
您可以先建立一个继承AnnotatedProcessBean类的基类作为扩展工具的基础,例如这里创建了一个DemoProcess类作为工具基类:
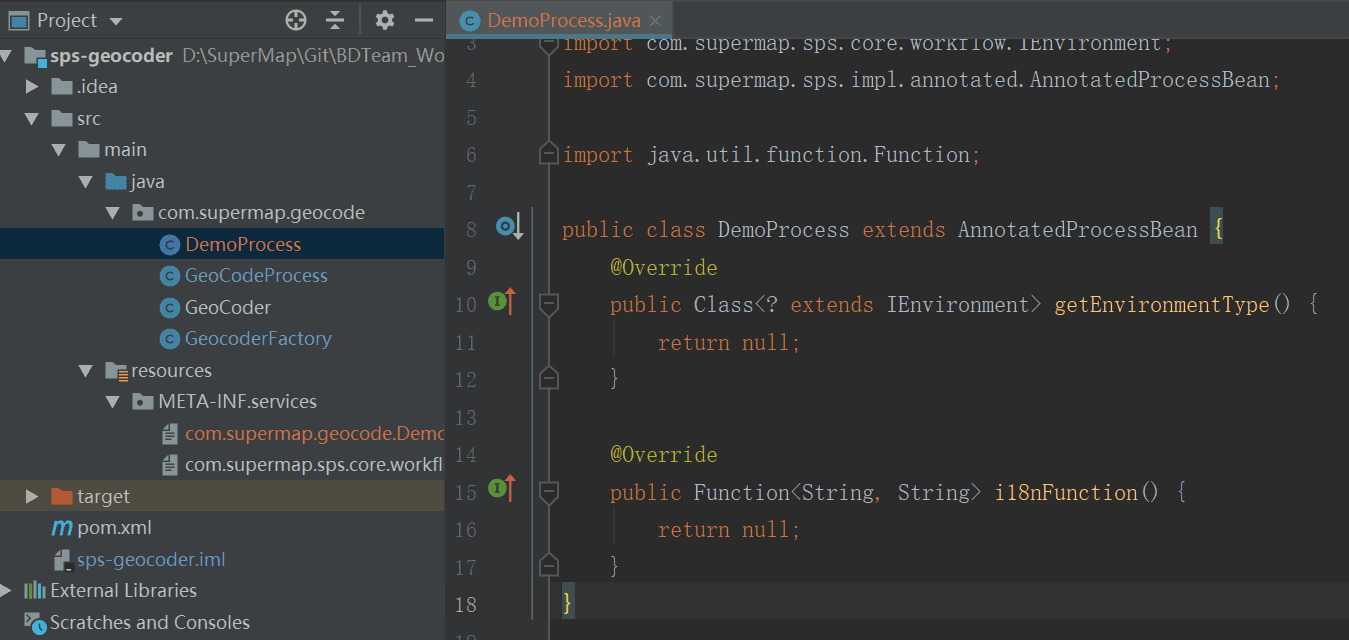
再创建一个工具实现类,继承自DemoProcess类,在进行自定义工具的具体实现时,您可以在execute函数中实现工具的功能。
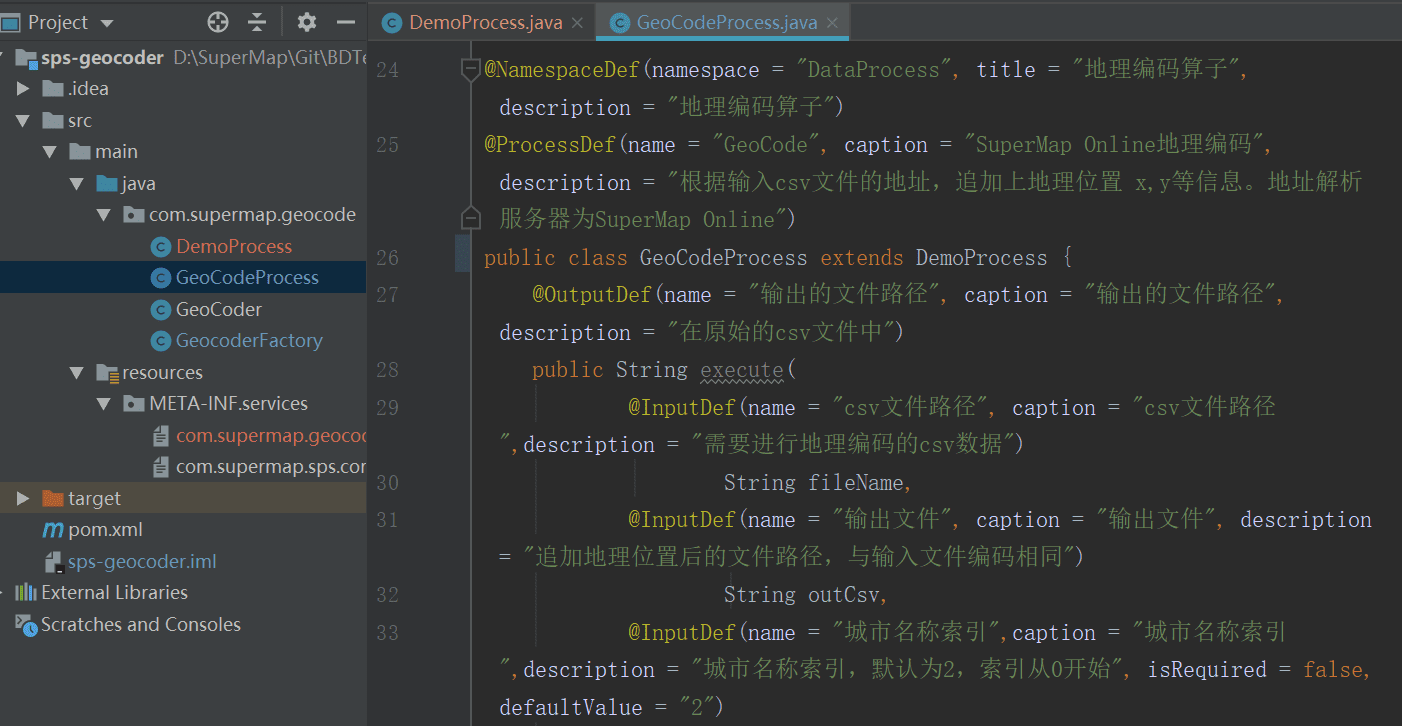
我们需要使用SuperMap注解来描述工具的基本信息、结果和参数等,使前端界面能够发现该工具。常用的注解有:
- @ProcessDef:基本信息,caption参数用于设置工具在处理自动化界面显示的名称,例如:
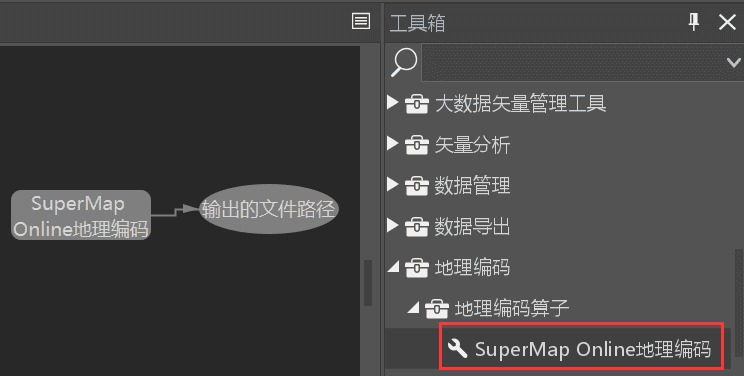
- @OutputDef:输出结果
- @InputDef:输入参数
- @NamespaceDef:命名空间,当工具数量较多时可进行多级目录的设置,例如:
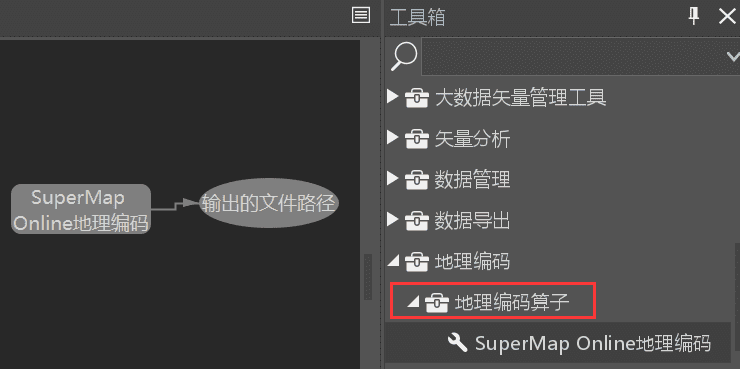
注解后的括号内填写该注解的相关参数。详细注解参数说明见第2章节。
1.3. 创建自定义工厂
创建一个自定义工厂类,用于对接工具工厂的类,并装载自定义的扩展工具,需继承自com.supermap.sps.impl.annotated.AbstractAnnotatedProcessFactory类。
注:当使用Spark分布式计算时,需继承自com.supermap.bdt. processing.sps.AbstractBDTProcessFactory类
例如,创建一个装载地理编码算子的工厂类GeocoderFactory类:
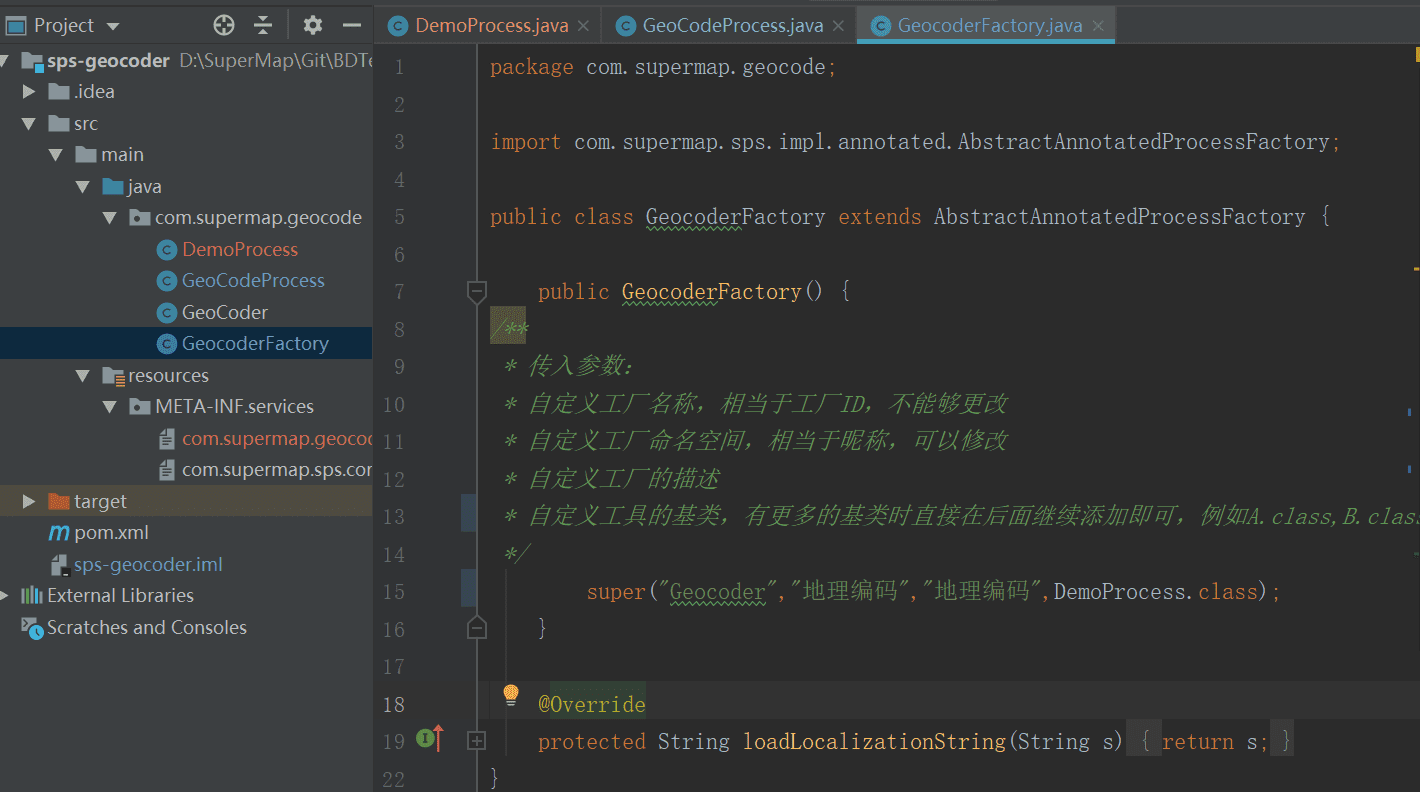 构造函数中传入参数:
构造函数中传入参数:
- 自定义工厂名称,相当于工厂ID,不能够更改
- 自定义工厂命名空间,相当于昵称,可以修改,处理自动化界面中作为一级目录存在。例如:
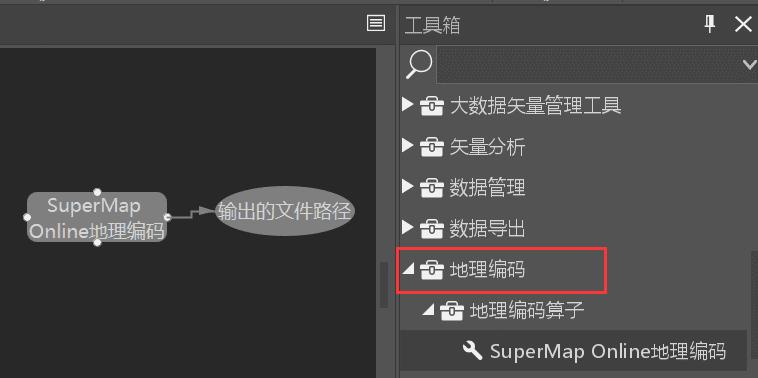
- 自定义工厂的描述
- 自定义工具的基类,有更多的基类时直接在后面继续添加即可,例如A.class,B.class
1.4. 注册自定义工具
使用SPI注册自定义工具与基类的关系。新建META- INF/service/com.supermap.geocode.DemoProcess文件,并注册自定义工具类GeoCodeProcess:
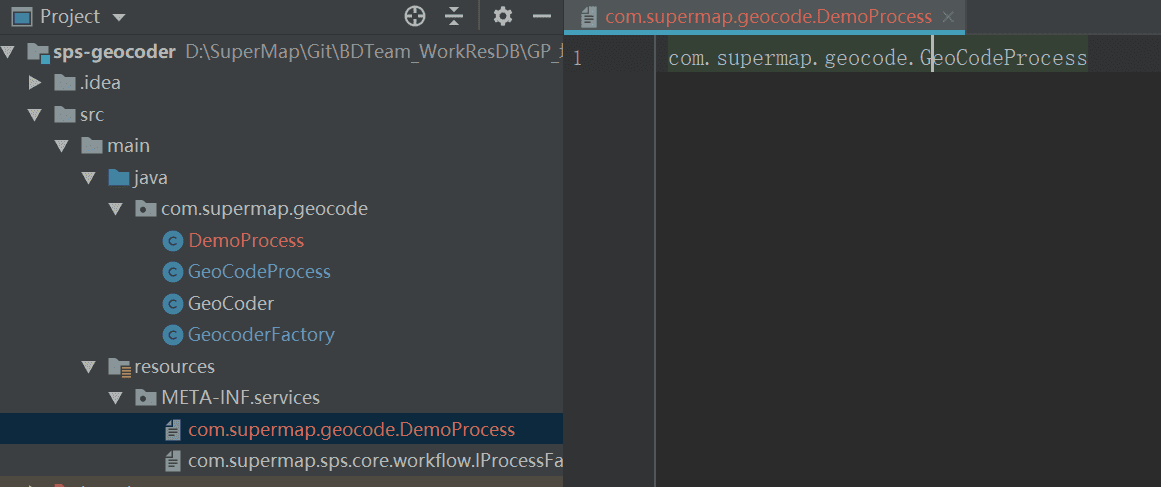
1.5. 注册自定义工厂
使用SPI注册工厂,在META-INF/service/com.supermap.sps.core.workflow.IProcessFactory中注册自定义工厂类,例如,本例需要将GeocoderFactory类进行注册:
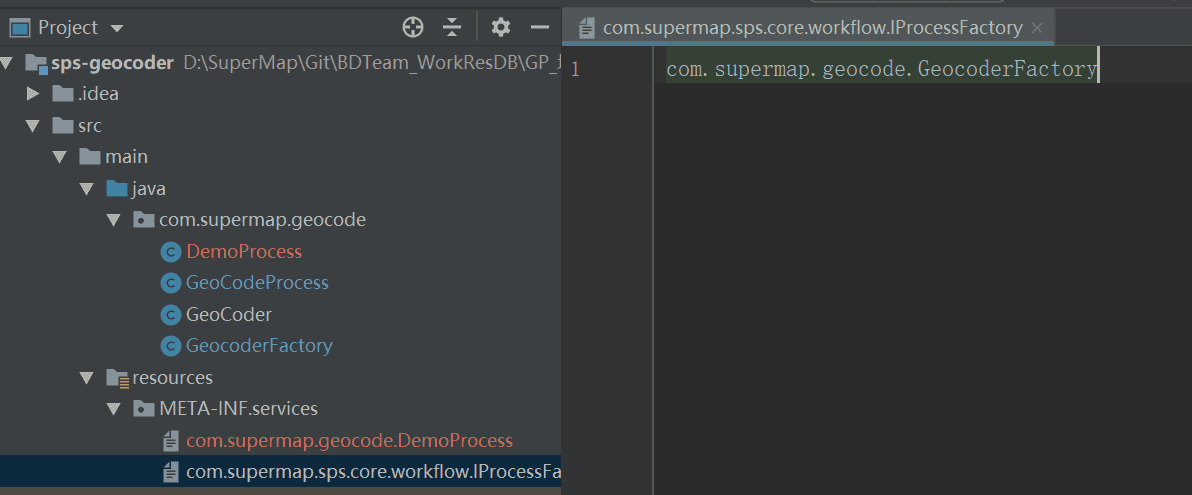
完成该步骤后即完成了在代码中的扩展开发工作。
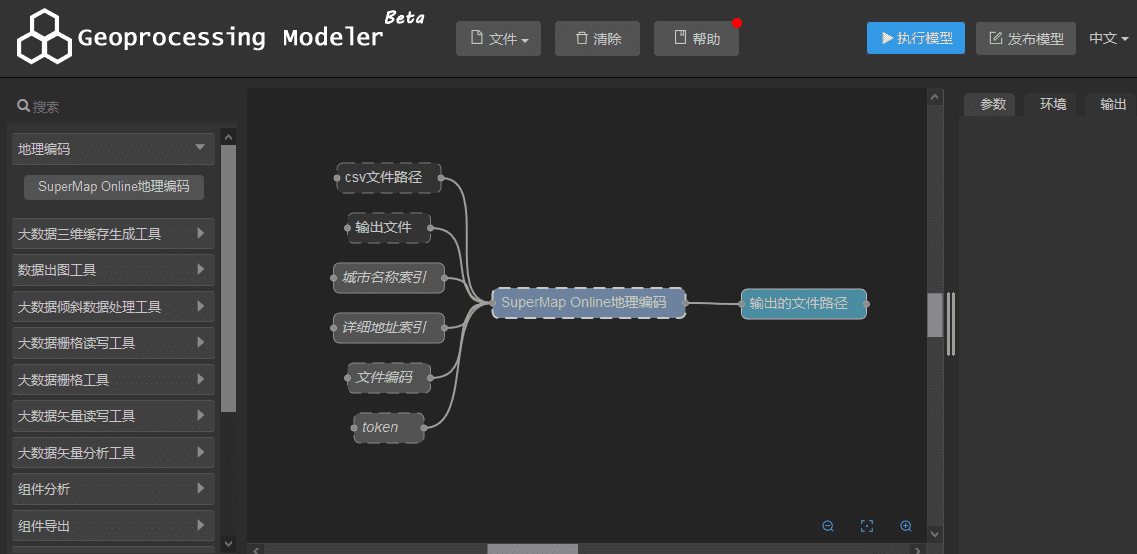
1.6. 添加至iServer Geoprocessing Modeler
如需在iServer Geoprocesssing Modeler中使用扩展开发的工具,您还需要执行以下步骤。
将扩展包打包为JAR文件,再将包含自定义工具的JAR文件添加至 %SuperMap iServer_HOME%\support\geoprocessing\lib路径下,重新启动iServer后进入Geoprocessing Modeler页面,即可在页面左侧的工具列表中找到自定义工具。
注:当扩展的算法需要使用Spark分布式计算时,需要手动在JAR文件名后添加“withbdt”,保证Geoprocessing Modeler在向集群提交任务时自动将JAR文件 下发至集群。例如:

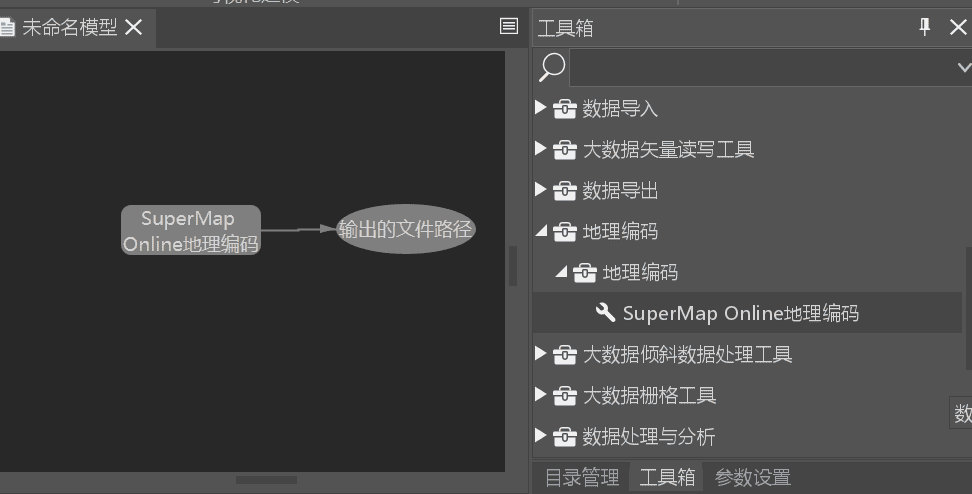
1.7. 添加至iDesktopX处理自动化工具箱
如需在iDesktopX工具箱中使用扩展开发的工具,您还需要执行以下步骤。
扩展包打包为JAR文件,将包含自定义工具的JAR文件添加至 %SuperMap iDesktop_HOME%\lib路径下,重新启动iDesktopX后,即可在工具箱列表中找到添加的自定义工具。
注:当扩展的算法需要使用Spark分布式计算时,需要同时将JAR文件拷贝到 %SuperMap iDesktopHOME%\support\bdtJars路径下,保证iDesktopX在向集群提交任务时自动将JAR文件下发至集群。_
2. 注解说明
SuperMap注解体系由sps- core-.jar提供(为版本号),支持定义输入输出参数的中文名称、支持定义是否为可选参数、支持设置参数默认值等实用功能。
SuperMap注解体系
创建自定义工具时需要用到的SuperMap注解:
@ProcessDef
用来标注方法或类,描述工具的基本信息
- name(),process 工具的名字,类比 maven dependency 的 artifactId
- caption(),process 工具的别名,默认为空,生成工具时会取 name 作为默认值。设置后成为工具在界面中显示的名称。
- description(),process 工具的描述信息,默认为空
- version(),工具的版本信息,默认为1.0
- compatiableVersion(),工具兼容版本信息,默认为1.0
@NamespaceDef
- namespace(),工具所在的名称空间id,类比 maven dependency 的 groupId。当工具数量较多时可进行多级目录的设置,支持以“.”符合分隔进行更多级别的目录设置。
- title(),工具所在的命名空间名字,作为处理自动化界面显示出的分级目录名。
- description(),工具所在的命名空间描述,与title保持一致。
@InputDef
用来标注方法参数,绑定 process 工具的 Input 和具体参数
- name(),Process 工具里对应 Input 的名称,同一个工具输入名称唯一不可重复
- caption(),Process 工具里对应 Input 的别名,默认为空,取 name() 作为默认值
- description(),Process 工具里对应 Input 的描述信息
- isRequired(),Process 工具里对应 Input 是否必填,默认为 true
- defaultValue(),process工具里对应的input的默认值,单参数有效,集合类型会忽略这个属性
- meta(),输入参数的附加信息,比如数值类型的值域,字符串类型参数是连接信息还是普通字符串等内容。Key=value的形式编写
-
dataType(),指定 Process 工具里对应 Input 的数据类型,一般不需要设置,运行时反射对应的参数获取类型即可。仅在以下两种情况有效
- 当参数类型是 List
之类的泛型集合时,由于运行时 T 会被擦除,无法获取到正确的类型,因此需要在 dataType 里指定子项数据类型 - 当 BDTInputDef 是同一个参数的多个注解之一时,由于程序无法知道 BDTParameterBuilder 会如何处理这些参数以及这些参数是什么类型,因此需要在 dataType 里指定数据类型
- 当参数类型是 List
补充:目前已经支持的meta数据类型:
-
数值类型(自动匹配类型):double、float、int、short,key与对应含义如下:
- minValue:数值类型参数规定的最小值
- maxValue:数值类型参数规定的最大值
- left:数值类型规定范围的左区间,可选值为:{open,close}
- Right:数值类型规定范围的右区间,可选值为:{open,close}
例如下面@InputDef定义的数值区间为(0,1)

-
String类型(需要指定字符串的具体意义)
- stringType:String的意义;目前支持{connection,FieldType}
- stringType=connection时其他key的含义
- connection.mode:连接模型,可选值为{SELECT,CREATE}
- stringType=FieldType时其他key的含义
- supportType:支持的FieldType类型,可选值为FieldType类型枚举字符串

-
DatasetVector类型:支持的矢量数据集类型
- supportType:支持的DatasetType类型,可选值为DatasetType类型枚举字符串
@OutputDef
用来标注工具的输出,有 OutputDefs 作为容器,支持重复注解。
- name(),Process 工具里对应的 Output 的名字,同一个工具输出名字唯一,不可重复
- caption(),Process 工具里对应的 Output 的别名,默认为空,取 name 作为默认值
- description(),Process 工具里对应的 Output 的描述信息
- outputSourceType(),输出绑定类型,RETURN 表示使用方法返回值作为输出数据;FIELD表示某个字段作为Output;PARAMETER 表示绑定某个参数作为输出数据,与 outputSource() 搭配使用
- outputSource(),仅 outputSourceType 为 PARAMETER 时有效,与对应索引值的参数绑定,之所以不使用参数名,是因为组件编译打包会进行混淆
@ParameterBuilderDef
指定多个 InputDef 标注一个参数时,用来在运行时构造参数实例。
- value(),指定 ParameterBuilder 的某个实现,用来构造参数。
@ParameterBuilder
参数构造工具。
- Object build(Map<String, Object> map),接收一个 map 返回 ParameterBuilderDef 标注的参数实例,map key 是 InputDef 的 name,map value 是运行时设置到 Input 上的值。
@OutputSourceType
- RETURN,表示使用方法返回值作为输出数据
- PARAMETR,表示绑定参数作为输出数据
- FIELD,表示绑定字段作为输出数据
@OutputDefs
OutputDef 的注解容器,是 java 8 及以上版本的新特性,以更友好易读的方式支持重复注解。
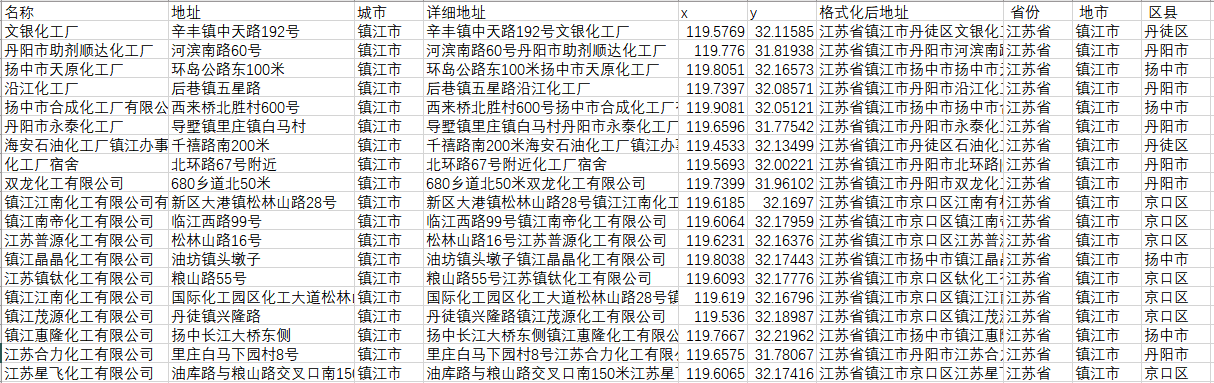
附:扩展开发示例代码-地理编码
示例代码参考附件sps-geocoder。
使用数据:镇江市-高德.csv

计算结果:
常见问题
1、在编译时报错自定义工厂类中的工具名称找不到符号
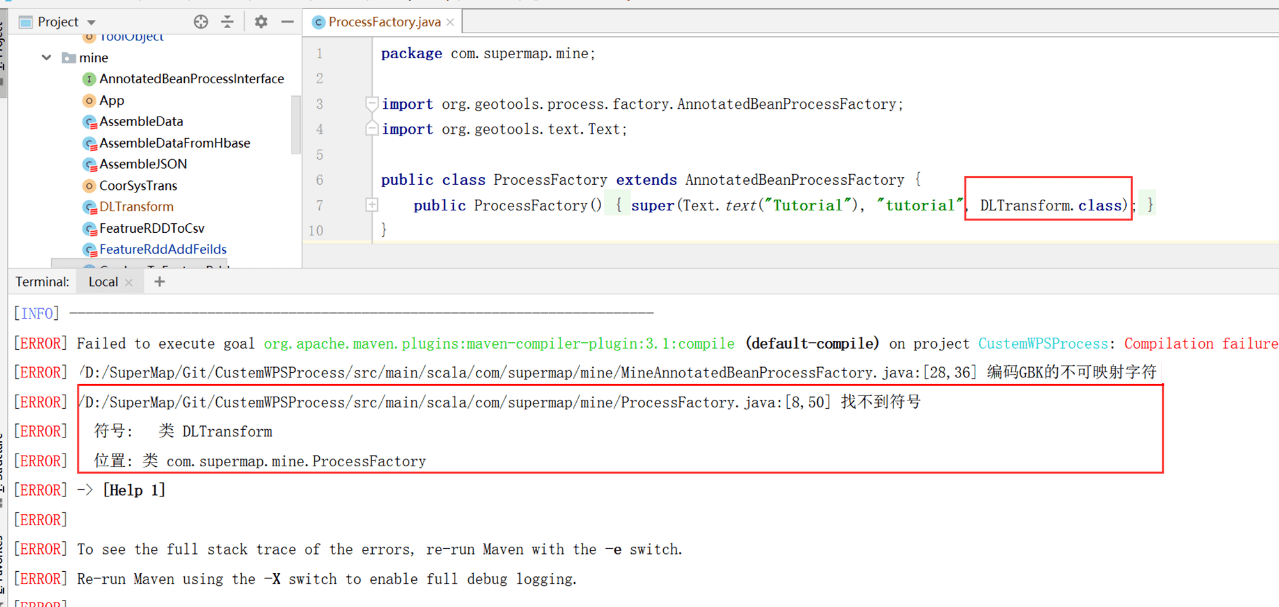
是由于工厂类为Java代码编写、工具实现算法为Scala代码编写,需要设置在编译时首先执行Scala代码编译可解决该问题,在pom 文件中设置 scala plugin 的配置:

2、 当AnnotatedProcessBean继承无法识别时,需要手动Alt+Enter,添加执行方法: