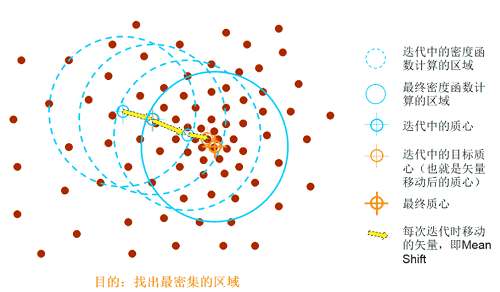
均值偏移聚类(Means Shift算法)是一种基于聚类中心迭代求解的聚类算法,与K均值聚类不同的是不需要事先确定聚类个数K。均值偏移聚类的原理为:从初始聚类中心点开始,沿着带宽内点群密度上升的方向不断寻找新的聚类中心点,直到满足终止条件。终止条件为迭代过程中前后两次聚类的中心移动距离几乎不变 或者达到最大迭代次数(默认迭代次数:300)。
使用说明
功能入口:
- 在 工具箱 -> 空间统计分析 -> 聚类分布 ->双击 均值偏移聚类 。
主要参数
- 源数据 :设置待分析的矢量数据集,支持点数据集。
- 带宽 :带宽值为以某个聚类中心点为核心时的搜索半径。默认值为-1,系统会自动计算一个默认带宽值。聚类结果受带宽的影响,若带宽设置太小,收敛较慢,簇类个数过多;带宽设置太大,一些簇类可能会丢失。
- 自定义初始化聚类中心点种子 :自定义初始聚类中心。默认不设置。
- 结果数据 :设置结果数据所要保存在的数据源及数据集名称,与源数据的数据类型一致。
结果输出
1、在源数据集中增加了一个 Cluster_ID 字段表示结果聚类类别;
2、结果矢量数据集表示最终聚类的聚类中心点。