k均值聚类(k-means)算法是一种迭代求解的聚类分析算法,其原理为预将数据分为K组,选取K个对象作为初始的聚类中心,然后把每个对象分配给最近的初始聚类中心,聚类中心以及分配给它们的对象代表一个聚类。每分配一次样本,聚类中心会被重新计算。这个过程将不断重复直到达到期望结果。迭代的终止条件可以是没有对象被重新分配给不同的聚类,没有聚类中心再发生变化,或者达到最大迭代次数(默认迭代次数:300)。
k均值方法对异常值敏感,因此可以在分析前将异常/离群值剔除,否则会对聚类结果有影响。
应用场景:
- 配送中心选址,如某供应链需要添加配送中心来满足业务需求,根据成本确定配送中心个数后需要进行选址,以满足各供应点能被分配到最近的配送中心。
- 多点任务划分,如产品直销人员需要拜访经销超市,如何将多家超市合理分配给N个直销人员,可利用k均值聚类分析将地理位置相近的超市聚类为一类,每个产品直销人员可对应一个聚类。
聚类分析属于探索性分析,其结果不一定能直接解决问题,但可提供一定指导。
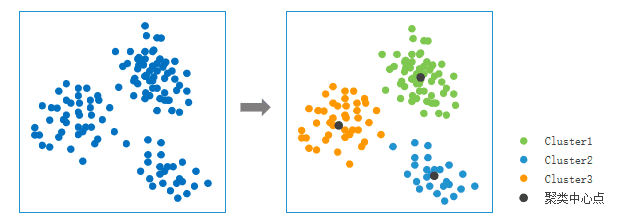
使用说明
功能入口:
- 在 工具箱 -> 空间统计分析 -> 聚类分布 ->双击 K均值聚类 。
主要参数
- 源数据 :设置待分析的矢量数据集,支持点数据集。
- 聚类数目 :聚类数目为期望经过聚类得到的分组数。一般来说会根据对数据的先验经验选择一个合适的k值,或经过多次尝试以选取最佳数目。默认值为0。
- 聚类中心初始化方法 :K均值聚类方法的一个重要步骤为选择初始质心位置,它会对聚类结果和运行时间都有影响。组件中提供了2个初始化方法,KMEASPLUSPLUS(k-means++方法,该方法是对随机选择的优化,默认使用该方法)和KMEASRANDOM(随机选择K个质心)。
- 结果数据 :设置结果数据所要保存在的数据源及数据集名称,与源数据的数据类型一致。
结果输出
1、在源数据集中增加了一个 Cluster_ID 字段表示结果聚类类别;
2、结果矢量数据集表示最终聚类的K个聚类中心点。