经济社会、土地利用、生物多样性、气候特征等空间分布不均匀情况,是空间分异现象在自然和社会经济发展过程中的多样性表现。空间分异性又称空间分层异质性,是指层内方差小于层间方差的地理现象,表现为分类或分区。例如地理分区、气候带、土地利用图、以及全国主体功能区划等。各种类型的生境如不同的地貌、土壤类型和气候为大量物种提供了避所,空间分层异质性对地理学研究具有重要意义。空间分层异质性是空间异质性表现出来的分层规律性。
地理探测器是探测空间分异性,以及揭示其背后驱动力的空间分析方法。其核心思想是基于这样的假设:如果某个自变量对某个因变量有重要影响,那么自变量和因变量的空间分布应该具有相似性。地理分异可以利用地理探测器进行统计分析,地理探测器有两大优势,第一,地理探测器既可以探测数值型数据,也可以探测定性数据。第二,可探测两因子交互作用于因变量。地理探测器通过分别计算和比较各单因子q值及两因子叠加后的q值,可以判断两因子是否存在交互作用,以及交互作用的强弱、方向、线性还是非线性等。两因子叠加既包括相乘关系,也包括其他关系,只要有关系,就能检验出来。
注 :功能原理及案例引自:王劲峰, 徐成东. 地理探测器:原理与展望[J].地理学报, 2017, 72(1): 116-134.
 功能原理
功能原理
地理探测器用于分析空间分层异质性,主要包括4个探测器(因子探测器、风险区探测器、生态探测器、交互作用探测器),分析结果可分别回答以下问题:①是否存在空间异质性?什么因素造成了这种分层异质性?②变量Y是否存在显著的区际差别?③因素X之间的相对重要性如何?④因素X对于因变量Y是独立起作用还是具有广义的交互作用?
分异及因子探测
探测Y的空间分异性以及探测某因子X多大程度上解释了属性Y的空间分异,用q值度量(Wang et al.,2010b),表达式为:
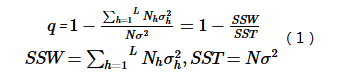
式中:h = 1, …, L为变量Y或因子X的分层,即分类或分区;Nh和N分别为层h和全区的单元数; σ2h和 σ2分别是层h和全区的Y值的方差。SSW和SST分别为层内方差之和(Within Sum of Squares)和全区总方差(Total Sum of Squares)。q的值域为[0, 1],值越大说明Y的空间分异性越明显;如果分层是由自变量X生成的,则q值越大表示自变量X对属性Y的解释力越强,反之则越弱。极端情况下,q值为1表明因子X完全控制了Y的空间分布,q值为0则表明因子X与Y没有任何关系,q值表示X解释了100×q%的Y。
q值的一个简单变换满足非中心F分布(Wang et al.,2016a):
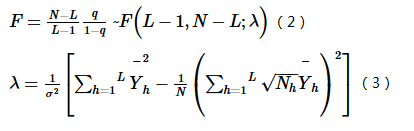
式中:λ为非中心参数;Yh为层h的均值。
交互作用探测
识别不同风险因子Xs之间的交互作用,即评估因子X1和X2共同作用时是否会增加或减弱对因变量Y的解释力,或这些因子对Y的影响是相互独立的。评估的方法是首先分别计算两种因子X1和X2对Y的q值:q(X1)和q(X2),并且计算它们交互(叠加变量X1和X2两个图层相切所形成的新的多边形分布)时的q值: q(X1∩X2),并对 q(X1)、 q(X2)与 q(X1∩X2)进行比较。两个因子之间的关系可分为以下几类:
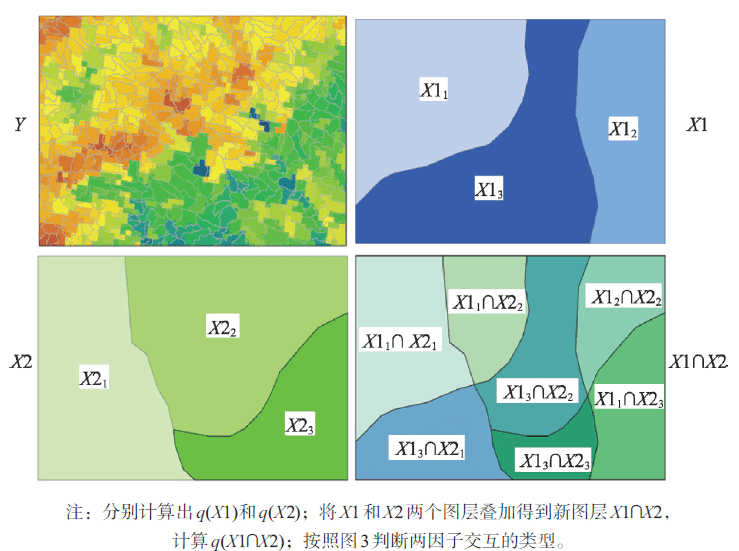

风险区探测
用于判断两个子区域间的属性均值是否有显著的差别,用t统计量来检验:
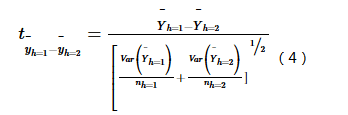
式中: Yh表示子区域h内的属性均值,如发病率或流行率;nh为子区域h内样本数量,Var表示方差。统计量t近似地服从Student’s t分布,其中自由度的计算方法为:
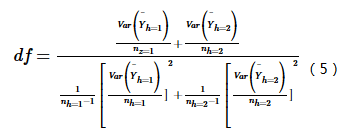
零假设H0: Yh=1=Yh=2,如果在置信水平α下拒绝H0,则认为两个子区域间的属性均值存在着明显的差异。
生态探测
用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异,以F统计量来衡量:
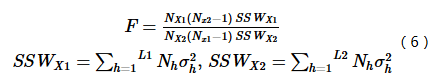
式中:NX1及NX2分别表示两个因子X1和X2的样本量;SSWX1和SSWX2分别表示由X1和X2形成的分层的层内方差之和;L1和L2分别表示变量X1和X2分层数目。其中零假设H0:SSWX1=SSWX2。如果在α的显著性水平上拒绝H0,这表明两因子X1和X2对属性Y的空间分布的影响存在着显著的差异。
功能入口
- 空间统计分析 选项卡 -> 分析模式 -> 地理探测器 。(iDesktopX)
- 工具箱 -> 空间统计分析 -> 分析模式 -> 地理探测器 。(iDesktopX)
主要参数
- 源数据 :设置待分析的数据集,支持点、线、面及属性表四类数据集。
- 因变量字段 :是被测定或被记录的变量,会随另一个(或另几个)变量的变动而发生变动,为数值量,如各村庄神经管畸形出生缺陷(NTDs)发生率。
- 自变量字段 :是引起因变量发生变化的因素或条件,是对因变量的解释变量,支持设置多个解释变量,如土壤类型、高程、水文流域等。注意这里的自变量应为类型量,如果为数值量,则需对其进行分组或分层,使组内方差最小,组间方差最大。分组可以基于专家知识,也可以使用k-means,或者排序后等分。应保证各组或层分类变量中至少有因变量的两个样本单元,从而可以计算该层的均值或方差。
- 结果数据 :指定的保存分析结果的数据源。四种探测器分析结果将分别生成新的属性表数据集存放至该数据源中。
结果说明
所有探测器结果将生成新的属性表数据集存储至数据源中,同时在右侧地理探测器面板中输出分析结果,下面将对各探测器结果进行分析:
- 因子探测器 :探测变量Y的空间分层异质性,以及探测某因子X多大程度上解释了变量Y的空间分异,用q值度量。如果分层是由自变量X生成的,则q值越大表示X和Y的空间分布越一致,自变量X对属性Y的解释力越强,反之则越弱。FactorDetector_result 属性表数据集为因子探测结果。
- 生态探测器 :用于比较不同影响因子对属性值的空间分布的影响是否有显著的差异。EcologicalDetector_result 属性表数据集为生态探测结果。
-
交互探测器 :用于识别不同解释变量之间的交互作用,评估两因子共同作用时是否会增加或减弱对因变量的解释力,或这些因子对其影响是否相互独立的。InteractionDetector_result 属性表数据集为交互探测结果,解释变量对因变量交互作用的类型包括:
- Weaken,nonlinear:非线性减弱;
- Weaken,uni-:单因子非线性减弱;
- Enhance, bi-:双因子增强;
- Independent:独立;
- Enhance,nonlinear:非线性增强。
- 风险探测器 :用于判断不同区域的属性均值是否具有显著性。RiskDetector_result 属性表数据集为风险区探测结果。
实例
下面利用地理探测器功能对某县神经管畸形出生缺陷(NTDs)发生率进行分析,环境因子变量包括:土壤类型、高程、水文流域。下图为环境因子分析的数据示意:
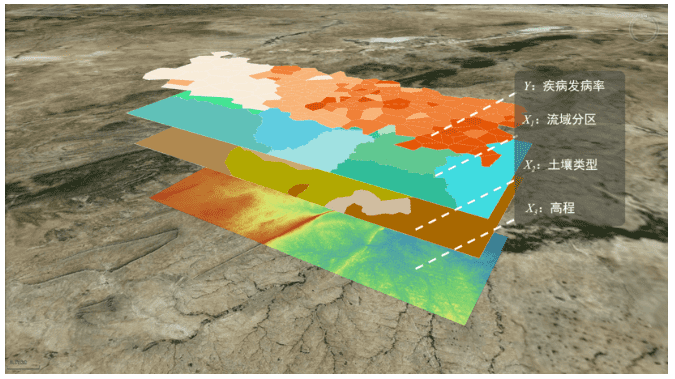
分析结果如下:
- 因子探测器:结果展示了所有因子 q 值的计算结果,结果表明,水文流域变量(watershed)具有最高的 q 值,说明这些变量中河流是决定 NTDs 空间格局最主要的环境因子。

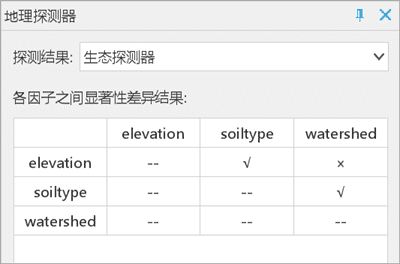
- 生态探测器:结果采用显著性水平为0.05的 t 检验,“√” 表示存在显著性,“×” 表示不显著。就对NTDs空间分布的作用而言,土壤类型与其他变量存在着显著差异。
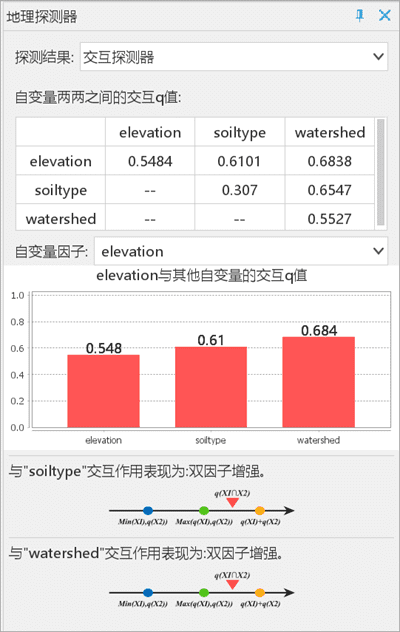
- 交互探测器:以高程因子( elevation)为例,结果表明任何两种变量对 NTDs 空间分布的交互作用都要大于第一种变量的独自作用,两两解释变量对NTDs空间分布的交互作用为双因子增强。
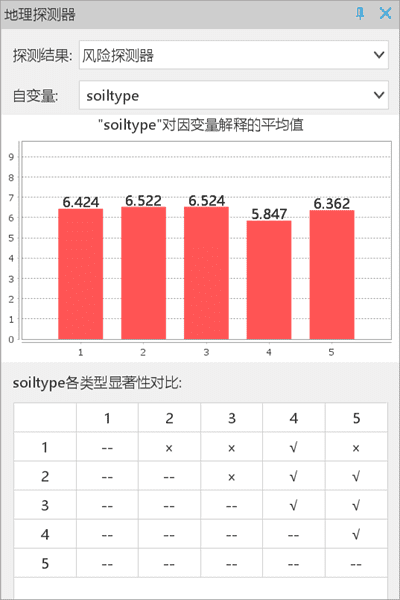
- 风险探测器:结果显示了对于单个风险因子而言的风险区探测的结果。以土壤类型( soiltype)为例,柱状图中 x 轴为 Unique Value,是环境因子各分层编号;y 轴为 Mean od explained variable,是在每种土壤类型区内的NTDs的平均发病率。
各类型显著性对比是,采用显著性水平为0.05的t检验,对比各类土壤类型(1-5)上的NTDs发病率是否显著大于另一土壤类型上的 NTDs 发病率,“√” 表示存在显著性,“×” 表示不显著。