密度聚类可根据指定的密度聚类算法,将空间位置分布较为密集的点划分为一簇。密度聚类提供了三种聚类方式:密度聚类、层次密度聚类、顺序密度聚类。
 相关定义
相关定义
- MinPts :聚类最小点数。
- 聚类半径ε :在指定的聚类半径范围内,找到≥MinPts的点,则划分为一簇。
- 核心点 :在聚类半径范围内,能找到最小聚类点数个临近点,就称其为核心点。
- 边界点 :若点的聚类半径邻域内包含的点数目小于MinPts,但是它在其他核心点的邻域内,则该点为边界点。
- 噪点 :既不是核心点也不是边界点的点。
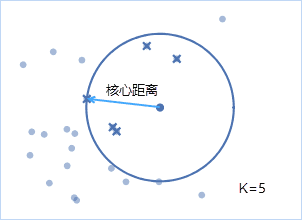
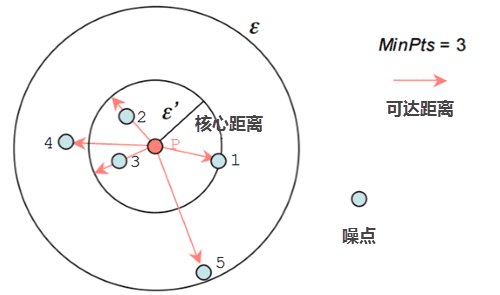
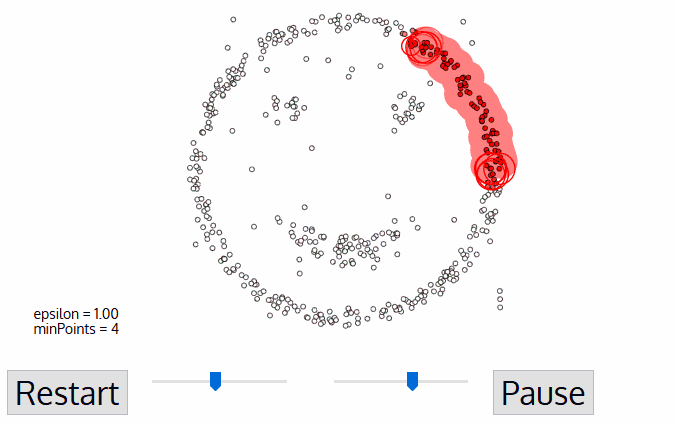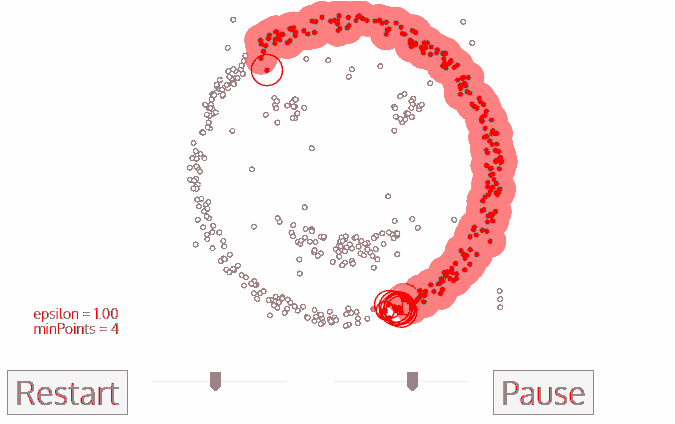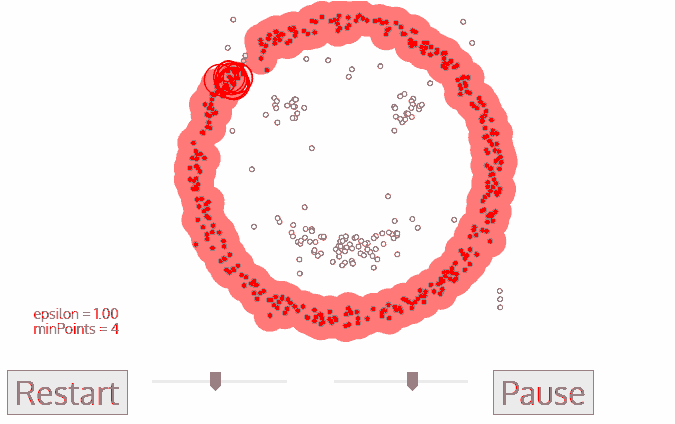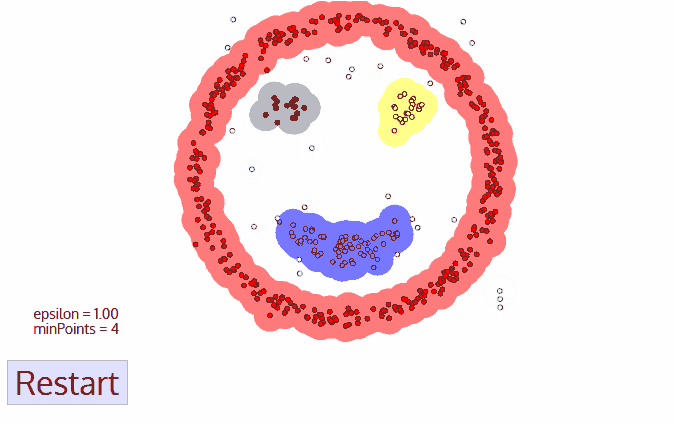
- 核心距离 :当前X点到其第k近的点的距离,k为指定的聚类最小点数,并表示为corek(x),若K=5,则核心距离如下图所示。
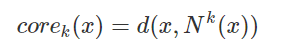
- 可达距离 :两点之间相互连通的距离与核心距离进行比较,如果两点距离小于核心距离,则核心距离作为两点的相互可达距离;如果两点距离大于核心距离,则两点距离为可达距离。
例如,下图中假设 minPts=3,聚类半径是 ε=d(P,5), P点 的核心距离是 d(P,1) , 点2到P点的距离小于核心距离,因此点2的可达距离是 核心距离 d(1,P) , 点3 的可达距离也是 核心距离 d(1,P) ,点4 到P点的距离大于核心距离,则点4的可达距离则是 d(4,P) 。
分析原理
1、密度聚类(DBSCAN)
密度聚类是基于对象空间分布密度的一种聚类算法,将足够密度的区域划分为一簇,它将类簇定义为高密度相连点的最大集合。该算法对噪声点不敏感,噪声点的多少不影响聚类结果,并且能发现任意形状的类簇。
DBSCAN算法原理 :根据给定的聚类半径(Eps)和聚类最小点数(MinPts)确定所有的核心对象,依次对每一个核心对象,找到由其密度可达的的样本生成聚类簇。
如果对经验值聚类的结果不满意,可以适当调整 Eps 和 MinPts 的值,经过多次迭代计算对比,选择最合适的参数值。如果 MinPts 不变,Eps 取得值过大,会导致大多数点都聚到同一个簇中,Eps 过小,会导致一个簇的分裂;如果 Eps 不变,MinPts 的值取得过大,会导致很多点将被标记为噪声点,MinPts 过小,会导致发现大量的核心点。
应用场景 :密度聚类(DBSCAN)适用于聚类距离明确的情况使用,例如:进行事故多发地段的排查时,相关文件明确规定了 2km 范围内发生 3 起交通事故(一年内),则该地段定义为事故多发路段,这种情况可使用 密度聚类(DBSCAN) 的算法进行分析,将聚类半径设置为 2000m,聚类最小点数设置为3.
2、层次密度聚类(HDBSCAN)
层次密度聚类是根据指定的聚类最小点数,将不同密度的聚类点与稀疏噪点分离。层次聚类会以最佳方式创建最稳定聚类的聚类级别,该聚类会尽可能多的合并聚类点而不加入噪点。
HDBSCAN 算法原理:层次密度聚类(HDBSCAN)是对DBSCAN算法的改进,引入了层次聚类的思想,对于EPS选择不当而早场聚类结果不佳的请求进行了纠正,降低了结果对参数的敏感度;同时,HDBSCAN不需要对输入的每个数据点进行检测,只需要对部分点进行判断即可。HDBSCAN 算法的详细原理,请参见 How HDBSCAN Works页面。
分析步骤:根据指定的MinPts,先计算点的核心距离以及相互可达距离,并构建最小生成树,通过联合查找将最小生成树进行连接合并,然后根据以下两个条件对最小生成树进行拆分,最终得到稳定性较好的聚类簇。
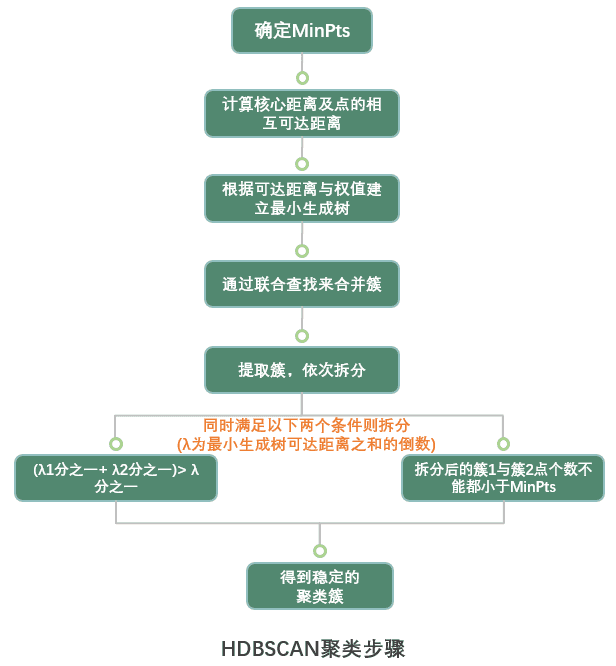
按照以下条件提取簇:
- 将一个最小生成树拆成两个簇,两个簇的可达距离之和分别为:λ1 和 λ2,若λ1 分之一加上 λ2分之一,大于原来的簇的可达距离之和λ分之一,则将该簇从此处打断划分为两个簇,依次重复。
- 若原始的簇划分为两个簇之后,每个簇的点个数都小于指定的 MinPts,则不再进行簇拆分。

- 顺序密度聚类(OPTICS) :改善了 DBSCAN 的不足,使得聚类结果不会过于依赖 Eps 和 MinPts,结合相邻要素之间的紧密度,将不同密度的聚类点与噪点相分离,顺序密度聚类在优化检测到的聚类方面最灵活,但其属于计算密集型,尤其是当搜索距离较大时。
应用场景
- 根据某连锁餐饮用户的位置信息,通过密度聚类分析,为连锁餐饮机构提供新店选址。
- 城市地下供水网络,伴随着管道破裂和爆裂等潜在问题,可将爆管点数据进行密度聚类分析,在爆管点密集区域设置抢修站,便于施工人员快速赶到进行施工。
- 根据密度聚类,排查城市的通事故多发路段,例如:2000m范围内或道路桥、涵洞的全程,一年之中发生3次重大以上交通事故的路段,。
- 对动植物分布地点进行聚类分析,获取对种群固有结构的认识。
- 异常检测:在数据清洗中,可以排除掉一些典型有问题的数据;也可用来发现异常用户,例如反盗刷、反爬虫。
功能入口
- 空间统计分析 选项卡 -> 聚类分布 -> 密度聚类 。(iDesktopX)
- 工具箱 -> 空间统计分析 -> 聚类分布 -> 密度聚类 。(iDesktopX)
主要参数
三种聚类方式的参数设置要求与结果不同,如下表所述:
| 聚类方式 | 密度聚类 | 层次密度聚类 | 顺序密度聚类 |
|---|---|---|---|
| 参数要求 | 聚类半径 点数据阀值 |
点数据阀值 | 聚类半径 点数据阀值 紧密度 |
| 结果字段 | 源数据ID(SourceID) 聚类类别(ClusterID) |
源数据ID(SourceID) 聚类类别(ClusterID) 聚类概率(Prob) 异常值(Outlier) 聚类代表(Exemplar) 聚类稳定性(Stability) |
源数据ID(SourceID) 聚类类别(ClusterID) 点顺序(ReachOrder) 可达距离(ReachDist) |
- 源数据 :设置待进行密度聚类分析的点数据集。
-
聚类方法 :提供三个聚类方法,下面分别对这三种方法和相关参数进行说明:
- 密度聚类 :根据指定的聚类半径,来查找紧密的聚类点和稀疏的噪声点,选择该聚类方式,需要设置聚类半径和点数据阀值两个参数。
- 层次密度聚类 :根据可变的距离及聚类点数目阀值,将不同密度的聚类点与稀疏噪点分离。选择该聚类方式,只需设置点数据阀值。
- 顺序密度聚类 :根据相邻要素之间的距离和紧密度,将不同密度的聚类点与噪点相分离,选择该聚类方式,需设置聚类半径、点数据阀值、紧密度三个参数。
-
聚类半径 :不同的聚类方法聚类半径的含义不同:
- 对于 密度聚类 (DBSCAN),必须在聚类半径范围内找到≥点数目阀值的点,才会将次划分为一个簇。如果点对象与聚类中最近点的距离大于此距离,则不会将该对象划分到该聚类中。
- 对于 顺序密度聚类 (OPTICS),聚类半径为最大可达距离的,它是指从一个点到其还未通过搜索访问过的最邻近点的距离。顺序密度聚类会查找指定聚类半径范围内的所有邻近距离,并将每个距离与核心距离进行比较,如果任意距离小于核心距离,则将为该要素分配核心距离作为其可达距离;如果所有距离都大于核心距离,则将最小的距离分配为可达距离。
例如,下图中假设 minPts=3,聚类半径是ε。那么 P点 的核心距离是 d(1,P) , 点2 的可达距离是 d(1,P) , 点3 的可达距离也是 d(1,P) , 点4 的可达距离则是 d(4,P) 。
- 单位 :设置聚类半径的单位,提供单位有厘米、毫米、分米、米、千米、码、英里、英尺,默认值为米。
- 点数目阀值 :将点划分为聚类的最小对象数,若对象数少于指定的数目,则将其视为噪点。
- 紧密度 :用于确定聚类的紧密度,为 0 到 100 之间的整数,值越接近 100,则产生的密集聚类越多;值越接近 0,结果中的聚类簇越松散。可达距离越低,表示聚类越密集;可达距离越高,则聚类越稀疏。
结果输出
- Source_ID (源数据 ID):源数据点对象的 SmID 值。
- Cluster_ID (聚类类别):表示每个点对象所属的聚类,相同 Cluster_ID 的点对象则为同一个簇,-1 则表示噪点。
- Prob (聚类概率):指点属于其所属聚类类别的概率,Prob 值为1表示点属于该聚类的概率较高,若值为0表示点属于该聚类的概率低,可能是异常值。
- Outlier (异常值):指明要素可能是其自己聚类中的异常值,值为 1 表示该点是异常值的较大;值为 0 表示点不是异常值。
- Exemplar (聚类代表):值为 1 的点则为各个聚类中最为典型或最具代表性的点对象。
- Stability (聚类稳定性):为各个聚类类别的稳定性得分。
- ReachOrder (点顺序):为点数据的处理顺序。
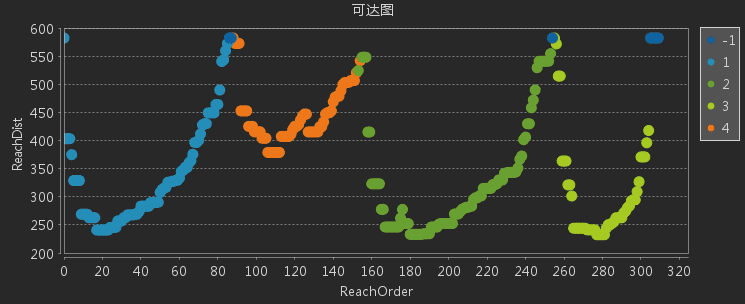
- ReachDist (可达距离):点到最邻近点的可达距离。可根据点处理顺序和可达距离创建可达图,个聚可达图可以评估聚类的紧密程度。可达距离越低,聚类越密集;可达距离越高,则聚类越稀疏,如下图,橘黄色聚类簇的可达距离较大,相比而言较稀疏。
实例
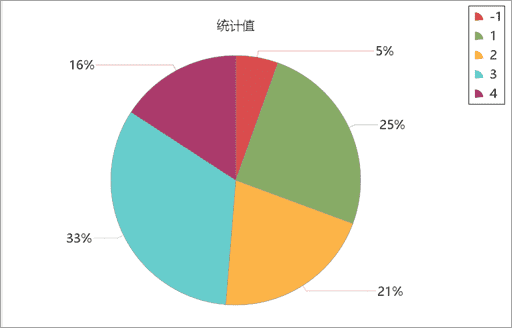
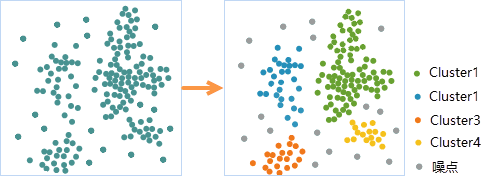
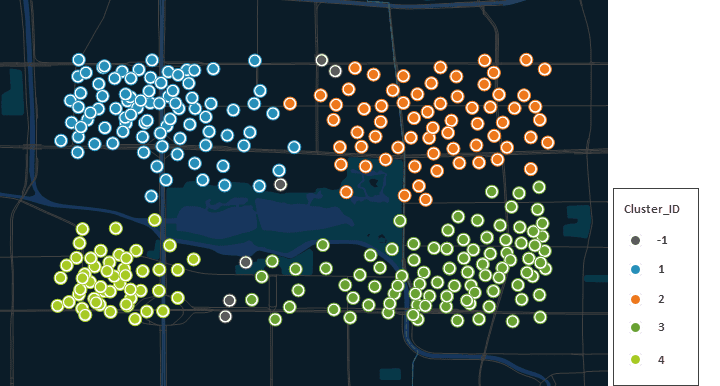
假如我们拿到了某区域某连锁餐饮店客户就餐出发点的数据,近期店里的客户较多,排号等候时间较长,为了更好的服务于客户,缩短排队时间,连锁店决定新增分店。通过密度聚类工具,可以分析客户的分布情况,在客户密集的分布区域增设分店。考虑到客户就餐距离的原因,使用顺序密度聚类的方法,对该数据进行分析,结果表明该区域餐饮店的客户可分为四个聚类,灰色(ClusterID = -1)为噪点,增设分店时,可在四个聚类区域内进行选址,如下图所示:
各个聚类类别具体占比如下图,其中 “ 3 ” 这个聚类占比最高。表明,在这四个聚类中,该聚类区域中客户的分布量最为密集。