



类 OverlayAnalyst
- java.lang.Object
-
- com.supermap.analyst.spatialanalyst.OverlayAnalyst
-
public class OverlayAnalyst extends java.lang.Object叠加分析类该类用于对输入的两个数据集或记录集之间进行各种叠加分析运算,如裁剪(clip)、擦除(erase)、合并(union)、同一(identity)、对称差(xOR)和更新(update)。
叠加分析是 GIS 中的一项非常重要的空间分析功能。是指在统一空间参考系统下,通过对两个数据集进行的一系列集合运算,产生新数据集的过程。叠加分析广泛应用于资源管理、城市建设评估、国土管理、农林牧业、统计等领域。因此,通过此叠加分析类可实现对空间数据的加工和分析,提取用户需要的新的空间几何信息,并且对数据的属性信息进行处理。
* 注意
- 进行叠加分析的两个数据集中,被称作输入数据集(在 SuperMap GIS 中称作第一数据集)的那个数据集,其类型可以是点、线、面等;另一个被称作叠加数据集(在 SuperMap GIS 中称作第二数据集),其类型一般是面类型。
- 应注意面数据集或记录集中本身应避免包含重叠区域,否则叠加分析结果可能出错。
- 叠加分析的数据必须为具有相同地理参考的数据,包括输入数据和结果数据。
- 在叠加分析的数据量很大的情况下,需对结果数据集创建空间索引,以提高数据的显示速度。
-
-
方法概要
所有方法 静态方法 具体方法 限定符和类型 方法和说明 static booleanclip(DatasetVector dataset, DatasetVector clipDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)对矢量数据集进行裁剪,将被裁减数据集(第一个数据集)中不在裁剪数据集(第二个数据集)内的对象裁剪并删除。static booleanclip(DatasetVector dataset, Geometry[] clipGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)对矢量数据集进行裁剪,将被裁减数据集中不在几何对象数组范围内的对象裁剪并删除。static booleanclip(Recordset recordset, Recordset clipRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)对记录集进行裁剪,将第一个记录集中不在第二个记录集内的对象裁剪并删除。static booleanclipCAD(DatasetVector dataset, Geometry clipRegion, DatasetVector resultDataset, boolean bClipInRegion, boolean bErase, double dTolerace)裁剪CAD.static booleanclipEx(DatasetVector dataset, Geometry clipRegion, DatasetVector resultDataset, boolean bClipInRegion, boolean bEraseFromSrc, double dTolerace)裁剪数据static booleanclipText(DatasetVector dataset, Geometry clipRegion, DatasetVector resultDataset, boolean bClipInRegion, boolean bErase, double dTolerace)裁剪文本数据集.static booleanerase(DatasetVector dataset, DatasetVector eraseDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对数据集进行擦除方式的叠加分析,将第一个数据集中包含在第二个数据集内的对象裁剪并删除。static booleanerase(DatasetVector dataset, Geometry[] eraseGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对数据集进行擦除方式的叠加分析,将被擦除的数据集中包含在几何对象数组内的对象裁剪并删除。static booleanerase(Recordset recordset, Recordset eraseRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对记录集进行擦除方式的叠加分析,将第一个记录集中包含在第二个记录集内的对象裁剪并删除。static booleanidentity(DatasetVector dataset, DatasetVector identityDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对数据集进行同一方式的叠加分析,结果数据集中保留被同一运算的数据集的全部对象和被同一运算的数据集与用来进行同一运算的数据集相交的对象。static booleanidentity(DatasetVector dataset, Geometry[] identityGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对数据集进行同一方式的叠加分析,结果数据集中保留被同一运算的数据集的全部对象和被同一运算的数据集与用来进行同一运算的几何对象数组相交的对象。static booleanidentity(Recordset recordset, Recordset identityRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对记录集进行同一方式的叠加分析,结果数据集中保留被统一运算的记录集的全部对象和被同一运算的记录集与用来进行同一运算的记录集相交的对象。static booleanintersect(DatasetVector dataset, DatasetVector intersectDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)进行相交方式的叠加分析,将被相交叠加分析的数据集不包含在用来相交叠加分析的数据集中的对象切割并删除。static booleanintersect(DatasetVector dataset, Geometry[] intersectGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)进行相交方式的叠加分析,将被相交叠加分析的数据集中不包含在用来相交叠加分析的面对象数组的对象切割并删除。static booleanintersect(Recordset recordset, Recordset intersectRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)进行相交方式的叠加分析,将被相交叠加分析的记录集中不包含在用来相交叠加分析的记录集中的对象切割并删除。static booleanunion(DatasetVector dataset, DatasetVector unionDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对两个面数据集进行合并方式的叠加分析,结果数据集中保存被合并叠加分析的数据集和用于合并叠加分析的数据集中的全部对象,并且对相交部分进行求交和分割运算。static booleanunion(DatasetVector dataset, Geometry[] unionGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)对面数据集用面对象数组进行合并方式的叠加分析,结果数据集中保存被合并叠加分析的数据集和用于合并叠加分析的面对象数组中的全部对象,并且对相交部分进行求交和分割运算。static booleanunion(Recordset recordset, Recordset unionRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对两个面记录集进行合并方式的叠加分析,结果数据集中保存被合并叠加分析的记录集和用于合并叠加分析的记录集中的全部对象,并且对相交部分进行求交和分割运算。static booleanupdate(DatasetVector dataset, DatasetVector updateDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对两个面数据集进行更新方式的叠加分析,更新运算时用用于更新的数据集替换与被更新数据集重合的部分,是一个先擦除后粘贴的过程。static booleanupdate(DatasetVector dataset, Geometry[] updateGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)对面数据集用面对象数组进行更新方式的叠加分析,更新运算时用用于更新的面对象数组替换与被更新数据集的重合部分,是一个先擦除后粘贴的过程。static booleanupdate(Recordset recordset, Recordset updateRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)用于对两个面记录集进行更新方式的叠加分析,更新运算是用用于更新的记录集替换它与被更新记录集的重合部分,是一个先擦除后粘贴的过程。static booleanxOR(DatasetVector dataset, DatasetVector xORDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)对两个面数据集进行对称差运算。static booleanxOR(DatasetVector dataset, Geometry[] xorGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)对面数据集用面对象数组进行对称差分析运算,即交集取反运算。static booleanxOR(Recordset recordset, Recordset xORRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)对两个面记录集进行对称差分析运算。
-
-
-
方法详细资料
-
clip
public static boolean clip(DatasetVector dataset, DatasetVector clipDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对矢量数据集进行裁剪,将被裁减数据集(第一个数据集)中不在裁剪数据集(第二个数据集)内的对象裁剪并删除。 注意:- 裁剪数据集(第二数据集)的类型必须是面,被裁减的数据集(第一数据集)可以是点、线、面。
- 在被裁减的数据集中,只有落在裁剪数据集多边形内的对象才会被输出到结果数据集中。
- 裁剪数据集、被裁减数据集以及结果数据集的地理坐标系必须一致。
- clip 与 intersect 在空间处理上是一致的,不同在于对结果记录集属性的处理,clip 分析只是用来做裁剪,结果记录集与第一个记录集的属性表结构相同,此处叠加分析参数对象设置无效。而 intersect求交分析的结果则可以根据字段设置情况来保留两个记录集的字段。
- 所有叠加分析的结果都不考虑数据集的系统字段。
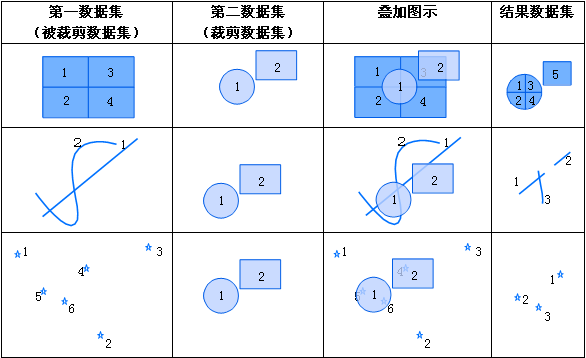
- 参数:
dataset- 被裁减的数据集,也称第一数据集。该数据集的类型可以是点、线和面。clipDataset- 用于裁剪的数据集,也称第二数据集。该数据集类型必须是面。resultDataset- 存放裁剪结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。此处该对象设置无效。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了如何对线矢量数据集进行裁剪。
public void overlayAnalystClip1() { // 返回被裁剪的矢量数据集和用于裁剪的矢量数据集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo(rootPath + "/SampleData/shanghai/shanghai.udb", "shanghai", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetCliped = (DatasetVector) targetDatasource. getDatasets().get("Road_L"); DatasetVector datasetClip = (DatasetVector) targetDatasource. getDatasets().get("Park_R"); // 创建一个线矢量数据集,用于存储裁剪分析返回的结果 String resultDatasetClipName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetClip"); DatasetVectorInfo datasetvectorInfoClip = new DatasetVectorInfo(); datasetvectorInfoClip.setType(DatasetType.LINE); datasetvectorInfoClip.setName(resultDatasetClipName); datasetvectorInfoClip.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetClip = targetDatasource.getDatasets().create( datasetvectorInfoClip); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamClip = new OverlayAnalystParameter(); overlayAnalystParamClip.setTolerance(0.0122055608); // 调用裁剪叠加分析方法实现裁剪分析 OverlayAnalyst.clip(datasetCliped, datasetClip, resultDatasetClip, overlayAnalystParamClip); // 释放工作空间占有的资源 workspace.dispose(); }
-
clip
public static boolean clip(Recordset recordset, Recordset clipRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对记录集进行裁剪,将第一个记录集中不在第二个记录集内的对象裁剪并删除。注意:
- 裁剪记录集(第二记录集)的类型必须是面,被裁减的记录集(第一记录集)可以是点、线、面。
- 在被裁减记录集中,只有落在裁剪记录集多边形内的对象才会被输出到结果数据集中。
- 裁剪记录集、被裁减记录集以及结果数据集的地理坐标系必须一致。
- clip 与 intersect 在空间处理上是一致的,不同在于对结果数据集属性的处理,clip 分析只是用来做裁剪,结果数据集与第一个数据集的属性表结构相同,此处叠加分析的参数对象设置无效。而Intersect求交分析的结果则可以根据字段设置情况来保留两个数据集的字段。
- 所有叠加分析的结果都不考虑记录集的系统字段。
对于裁剪的示意图,可参考另一重载方法
clip的介绍。- 参数:
recordset- 被裁减的记录集,也称为第一记录集。该记录集类型可以是点、线和面。clipRecordset- 用于裁剪的记录集,也称为第二记录集。该记录集类型必须是面类型。resultDataset- 存放裁剪结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。此处该对象设置无效。- 返回:
- 分析成功返回值为true,失败返回值为false.
- Example:
- 以下代码示范了如何对线记录集进行裁剪。
public void overlayAnalystClip2() { // 返回被裁剪的记录集和用于裁剪的记录集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo(rootPath + "/SampleData/shanghai/shanghai.udb", "shanghai", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetRoad = (DatasetVector) targetDatasource. getDatasets().get("Road_L"); QueryParameter queryParamCliped = new QueryParameter(); queryParamCliped.setAttributeFilter("ClassID=430110"); queryParamCliped.setHasGeometry(true); Recordset queryResultCliped = datasetRoad.query(queryParamCliped); DatasetVector datasetPark = (DatasetVector) targetDatasource. getDatasets().get("Park_R"); QueryParameter queryParamClip = new QueryParameter(); queryParamClip.setAttributeFilter("ClassID=370100"); queryParamClip.setHasGeometry(true); Recordset queryResultClip = datasetPark.query(queryParamClip); // 创建一个线矢量数据集,用于存储裁剪分析返回的结果 String resultDatasetClipName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetClip"); DatasetVectorInfo datasetvectorInfoClip = new DatasetVectorInfo(); datasetvectorInfoClip.setType(DatasetType.LINE); datasetvectorInfoClip.setName(resultDatasetClipName); datasetvectorInfoClip.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetClip = targetDatasource.getDatasets().create( datasetvectorInfoClip); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamClip = new OverlayAnalystParameter(); overlayAnalystParamClip.setTolerance(0.0000015); // 调用裁剪叠加分析方法实现裁剪分析 OverlayAnalyst.clip(queryResultCliped, queryResultClip, resultDatasetClip, overlayAnalystParamClip); // 释放工作空间占有的资源 workspace.dispose(); }
-
clip
public static boolean clip(DatasetVector dataset, Geometry[] clipGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对矢量数据集进行裁剪,将被裁减数据集中不在几何对象数组范围内的对象裁剪并删除。- 裁剪几何对象的类型必须是面,被裁减的数据集可以是点、线、面。
- 在被裁减数据集中,只有落在裁剪几何对象内的对象才会被输出到结果数据集中。
- 用于裁剪的几何对象数组、被裁减的数据集以及结果数据集的地理坐标系必须一致。
- clip 与 intersect 在空间处理上是一致的,不同在于对结果数据集属性的处理,clip 分析只是用来做裁剪,结果数据集与第一个数据集的属性表结构相同,此处叠加分析的参数设置无效。而intersect求交分析的结果则可以根据字段设置情况来保留两个数据集的字段。
- 所有叠加分析的结果都不考虑数据集的系统字段。
对于裁剪的示意图,可参考另一重载方法
clip的介绍。- 参数:
dataset- 被裁减的数据集。该数据集类型可以是点、线和面。clipGeometries- 用于裁剪的几何对象数组,并且该数组中的几何对象必须是面几何对象。resultDataset- 存放裁剪结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。此处该对象设置无效。- 返回:
- 分析成功返回true,失败返回false。
-
erase
public static boolean erase(DatasetVector dataset, DatasetVector eraseDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对数据集进行擦除方式的叠加分析,将第一个数据集中包含在第二个数据集内的对象裁剪并删除。注意:
- 擦除数据集(第二数据集)的类型必须是面,被擦除的数据集(第一数据集)可以是点、线、面数据集。
- 擦除数据集中的多边形集合定义了擦除区域,被擦除数据集中凡是落在这些多边形区域内的特征都将被去除。而落在多边形区域外的特征要素都将被输出到结果数据集中,与clip运算相反。
- 擦除数据集、被擦除数据集以及结果数据集的地理坐标系必须一致。
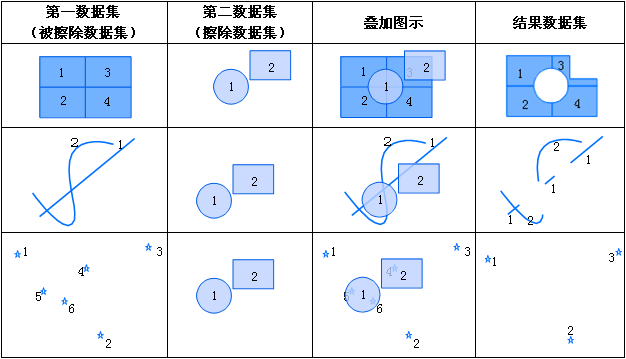
- 参数:
dataset- 被擦除的数据集,也称第一数据集。该数据集类型为点、线和面类型。eraseDataset- 用于擦除的数据集,也称第二数据集。该数据集类型必须是面数据集类型。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
-
erase
public static boolean erase(Recordset recordset, Recordset eraseRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对记录集进行擦除方式的叠加分析,将第一个记录集中包含在第二个记录集内的对象裁剪并删除。有关擦除的详细说明,请参见另一重载方法
erase的介绍。注意:用于擦除的记录集、被擦除的记录集以及结果数据集的地理坐标系必须一致。
- 参数:
recordset- 被擦除的记录集 ,也称第一记录集。该记录集为点、线和面类型。eraseRecordset- 用于擦除的记录集,也称第二记录集。该记录集类型必须是面类型。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
-
erase
public static boolean erase(DatasetVector dataset, Geometry[] eraseGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对数据集进行擦除方式的叠加分析,将被擦除的数据集中包含在几何对象数组内的对象裁剪并删除。有关擦除的详细信息,请参见另一重载方法
erase的介绍。注意:用于擦除的几何对象数组、被擦除的数据集以及结果数据集的地理坐标系必须一致。
- 参数:
dataset- 被擦除的数据集,该数据集类型为点、线和面类型。eraseGeometries- 用于擦除的几何对象数组,并且该数组中的几何对象必须是面几何对象。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回true,失败返回false。
-
identity
public static boolean identity(DatasetVector dataset, DatasetVector identityDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对数据集进行同一方式的叠加分析,结果数据集中保留被同一运算的数据集的全部对象和被同一运算的数据集与用来进行同一运算的数据集相交的对象。注意:
- 同一运算就是第一数据集与第二数据集先求交,然后求交的结果再与第一数据集求并的一个运算。其中,第二数据集的类型必须是面,第一数据集的类型可以是点、线、面数据集。如果第一个数据集为点数据集,则新生成的数据集中保留第一个数据集的所有对象;如果第一个数据集为线数据集,则新生成的数据集中保留第一个数据集的所有对象,但是把第二个数据集相交的对象在相交的地方打断;如果第一个数据集为面数据集,则结果数据集保留以第一数据集为控制边界之内的所有多边形,并且把与第二个数据集相交的对象在相交的地方分割成多个对象。
- identity 运算与 union 运算有相似之处,所不同之处在于 union 运算保留了两个数据集的所有部分,而 identity 运算是把第一个数据集中与第二个数据集不相交的部分进行保留。identity 运算的结果属性表来自于两个数据集的属性表。
- 用于进行同一运算的数据集、被同一运算的数据集以及结果数据集的地理坐标系必须一致。

- 参数:
dataset- 被同一运算的数据集,可以是点、线、面类型。identityDataset- 用来进行同一运算的数据集,必须为面类型。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 对两个面数据集进行同一方式的叠加分析。
public void overlayAnalystIdentity1() { // 返回被同一运算的矢量数据集与用于同一运算的矢量数据集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetIdentitied = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); DatasetVector datasetIdentity = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); // 创建一个面矢量数据集,用于存储同一运算返回的结果 String resultDatasetIdentityName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetIdentity"); DatasetVectorInfo datasetvectorInfoIdentity = new DatasetVectorInfo(); datasetvectorInfoIdentity.setType(DatasetType.REGION); datasetvectorInfoIdentity.setName(resultDatasetIdentityName); datasetvectorInfoIdentity.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetIdentity = targetDatasource.getDatasets(). create(datasetvectorInfoIdentity); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamIdentity = new OverlayAnalystParameter(); overlayAnalystParamIdentity.setOperationRetainedFields(new String[] { "ClassID"}); overlayAnalystParamIdentity.setSourceRetainedFields(new String[] { "Name"}); overlayAnalystParamIdentity.setTolerance(0.0089078724); // 调用同一运算方法实现同一运算 OverlayAnalyst.identity(datasetIdentitied, datasetIdentity, resultDatasetIdentity, overlayAnalystParamIdentity); // 释放工作空间占有的资源 workspace.dispose(); }
-
identity
public static boolean identity(Recordset recordset, Recordset identityRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对记录集进行同一方式的叠加分析,结果数据集中保留被统一运算的记录集的全部对象和被同一运算的记录集与用来进行同一运算的记录集相交的对象。有关同一运算的详细介绍,请参见另一重载方法
identity的介绍。注意,用于进行同一运算的记录集、被同一运算的记录集以及结果数据集的地理坐标系必须一致。
- 参数:
recordset- 被同一运算的记录集,也成为第一记录集,可以是点、线、面类型。identityRecordset- 用来进行同一运算的记录集,也成为第二记录集,必须为面类型。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面记录集进行同一方式的叠加分析。
public void overlayAnalystIdentity2() { // 返回被同一运算的记录集与用于同一运算的记录集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetIdentitied = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); Recordset queryResultIdentitied = datasetIdentitied.getRecordset(false, CursorType.DYNAMIC); DatasetVector datasetIdentity = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); QueryParameter queryParamIdentity = new QueryParameter(); queryParamIdentity.setAttributeFilter("ClassID = 32023"); queryParamIdentity.setHasGeometry(true); Recordset queryResultIdentity = datasetIdentity.query( queryParamIdentity); // 创建一个面矢量数据集,用于存储同一运算返回的结果 String resultDatasetIdentityName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetIdentity"); DatasetVectorInfo datasetvectorInfoIdentity = new DatasetVectorInfo(); datasetvectorInfoIdentity.setType(DatasetType.REGION); datasetvectorInfoIdentity.setName(resultDatasetIdentityName); datasetvectorInfoIdentity.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetIdentity = targetDatasource.getDatasets(). create(datasetvectorInfoIdentity); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamIdentity = new OverlayAnalystParameter(); overlayAnalystParamIdentity.setOperationRetainedFields(new String[] { "ClassID"}); overlayAnalystParamIdentity.setSourceRetainedFields(new String[] { "Name"}); overlayAnalystParamIdentity.setTolerance(0.0089078724); // 调用同一运算方法实现同一运算 OverlayAnalyst.identity(queryResultIdentitied, queryResultIdentity, resultDatasetIdentity, overlayAnalystParamIdentity); // 释放工作空间占有的资源 workspace.dispose(); }
-
identity
public static boolean identity(DatasetVector dataset, Geometry[] identityGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对数据集进行同一方式的叠加分析,结果数据集中保留被同一运算的数据集的全部对象和被同一运算的数据集与用来进行同一运算的几何对象数组相交的对象。有关同一运算的详细介绍,请参见另一重载方法
identity的介绍。注意,用于进行同一运算的几何对象数组、被同一运算的数据集以及结果数据集的地理坐标系必须一致。
- 参数:
dataset- 被同一运算的数据集,可以是点、线、面类型。identityGeometries- 用来进行同一运算的几何对象数组,该数组中的几何对象必须是面几何对象。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回true,否则返回false。
-
intersect
public static boolean intersect(DatasetVector dataset, DatasetVector intersectDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
进行相交方式的叠加分析,将被相交叠加分析的数据集不包含在用来相交叠加分析的数据集中的对象切割并删除。即两个数据集中重叠的部分将被输出到结果数据集中,其余部分将被排除。注意:
- 被相交叠加分析的数据集可以是点类型、线类型和面类型,用来相交叠加分析的数据集必须为面类型。第一数据集的特征对象(点、线和面)在与第二数据集中的多边形相交处被分裂(点对象除外),分裂结果被输出到结果数据集中。
- 相交运算与裁剪运算得到的结果数据集的空间几何信息是相同的,但是裁剪运算不对属性表做任何处理,而求交运算可以让用户选择需要保留的属性字段。
- 用于相交叠加分析的数据集、被相交叠加分析的数据集以及结果数据集的地理坐标系必须一致。
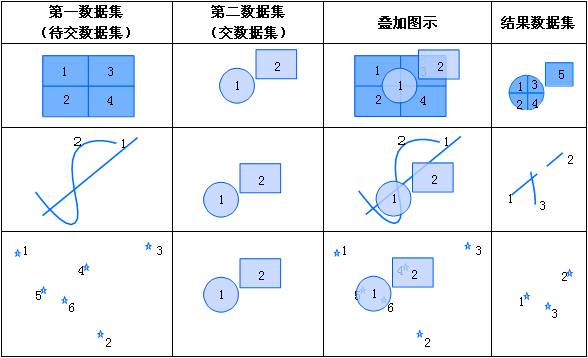
- 参数:
dataset- 被相交叠加分析的数据集,该数据集的类型可以是点、线、面数据集。intersectDataset- 用来相交叠加分析的数据集,该数据集必须是面数据集。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面数据集进行相交方式的叠加分析。
public void overlayAnalystIntersect1() { // 返回被相交的矢量数据集与用于相交的矢量数据集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetIntersected = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); DatasetVector datasetIntersect = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); // 创建一个面矢量数据集,用于存储相交分析返回的结果 String resultDatasetIntersectName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetIntersect"); DatasetVectorInfo datasetvectorInfoIntersect = new DatasetVectorInfo(); datasetvectorInfoIntersect.setType(DatasetType.REGION); datasetvectorInfoIntersect.setName(resultDatasetIntersectName); datasetvectorInfoIntersect.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetIntersect = targetDatasource.getDatasets(). create( datasetvectorInfoIntersect); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamIntersect = new OverlayAnalystParameter(); overlayAnalystParamIntersect.setOperationRetainedFields(new String[] { "ClassID"}); overlayAnalystParamIntersect.setSourceRetainedFields(new String[] { "Name"}); overlayAnalystParamIntersect.setTolerance(0.0000011074); // 调用相交叠加分析方法实相交分析 OverlayAnalyst.intersect(datasetIntersected, datasetIntersect, resultDatasetIntersect, overlayAnalystParamIntersect); // 释放工作空间占有的资源 workspace.dispose(); }
-
intersect
public static boolean intersect(Recordset recordset, Recordset intersectRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
进行相交方式的叠加分析,将被相交叠加分析的记录集中不包含在用来相交叠加分析的记录集中的对象切割并删除。有关相交运算的详细介绍,请参见另一重载方法
intersect的介绍。注意,用来相交叠加分析的记录集,被相交分析的记录集以及结果数据集的地理坐标系必须一致。
- 参数:
recordset- 被相交叠加分析的记录集,该类型可以是点、线、面类型。intersectRecordset- 用来相交叠加分析的记录集,必须是面。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,分析失败返回值为false。
- Example:
- 以下代码示范了对两个面记录集进行相交方式的叠加分析。
public void overlayAnalystIntersect2() { // 返回被相交的记录集与用于相交的记录集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetIntersected = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); Recordset queryResultIntersected = datasetIntersected.getRecordset(false, CursorType.DYNAMIC); DatasetVector datasetIntersect = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); QueryParameter queryParamIntersect = new QueryParameter(); queryParamIntersect.setAttributeFilter("ClassID = 32023"); queryParamIntersect.setHasGeometry(true); Recordset queryResultIntersect = datasetIntersect.query( queryParamIntersect); // 创建一个面矢量数据集,用于存储相交分析返回的结果 String resultDatasetIntersectName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetIntersect"); DatasetVectorInfo datasetvectorInfoIntersect = new DatasetVectorInfo(); datasetvectorInfoIntersect.setType(DatasetType.REGION); datasetvectorInfoIntersect.setName(resultDatasetIntersectName); datasetvectorInfoIntersect.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetIntersect = targetDatasource.getDatasets(). create( datasetvectorInfoIntersect); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamIntersect = new OverlayAnalystParameter(); overlayAnalystParamIntersect.setOperationRetainedFields(new String[] { "ClassID"}); overlayAnalystParamIntersect.setSourceRetainedFields(new String[] { "Name"}); overlayAnalystParamIntersect.setTolerance(0.0000011074); // 调用相交叠加分析方法实相交分析 OverlayAnalyst.intersect(queryResultIntersected, queryResultIntersect, resultDatasetIntersect, overlayAnalystParamIntersect); // 释放工作空间占有的资源 workspace.dispose(); }
-
intersect
public static boolean intersect(DatasetVector dataset, Geometry[] intersectGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)
进行相交方式的叠加分析,将被相交叠加分析的数据集中不包含在用来相交叠加分析的面对象数组的对象切割并删除。有关相交运算的详细介绍,请参见另一重载方法
intersect的介绍。注意,用于相交叠加分析的面对象数组、被相交分析的数据集以及结果数据集的地理坐标系必须一致。
- 参数:
dataset- 被相交叠加分析的数据集,该数据集的类型可以是点、线、面数据集。intersectGeometries- 用来相交叠加分析的面对象数组。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回true,失败返回false。
-
xOR
public static boolean xOR(DatasetVector dataset, DatasetVector xORDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对两个面数据集进行对称差运算。即交集取反运算。 - 用于对称差分析的数据集、被对称差分析的数据集以及结果数据集的地理坐标系必须一致。
对称差运算是两个数据集的异或运算。操作结果是,对于每一个面对象,去掉其与另一个数据集中的几何对象相交的部分,而保留剩下的部分。对称差运算的输出结果的属性表包含两个输入数据集的非系统属性字段。

-
-
- 参数:
dataset- 被对称差分析的原数据集,必须是面数据集。xORDataset- 用于对称差分析的数据集,必须是面数据集。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面数据集进行对称差分析运算。
public void overlayAnalystXOR1() { // 返回被对称差分析的数据集与用于对称差分析的数据集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetXORed = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); DatasetVector datasetXOR = (DatasetVector) targetDatasource.getDatasets(). get("ResidentialArea"); // 创建一个面矢量数据集,用于存储对称差分析返回的结果 String resultDatasetXORName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetXOR"); DatasetVectorInfo datasetvectorInfoXOR = new DatasetVectorInfo(); datasetvectorInfoXOR.setType(DatasetType.REGION); datasetvectorInfoXOR.setName(resultDatasetXORName); datasetvectorInfoXOR.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetXOR = targetDatasource.getDatasets().create( datasetvectorInfoXOR); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamXOR = new OverlayAnalystParameter(); overlayAnalystParamXOR.setTolerance(0.0089078724); // 调用对称差分析方法对称差分析 OverlayAnalyst.xOR(datasetXORed, datasetXOR, resultDatasetXOR, overlayAnalystParamXOR); //释放工作空间占有的资源 workspace.dispose(); }
-
xOR
public static boolean xOR(Recordset recordset, Recordset xORRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对两个面记录集进行对称差分析运算。有关对称差运算的详细介绍,请参见另一重载方法
xOR的介绍。注意,用于对称差分析的记录集、被对称差分析的记录集以及结果数据集的地理坐标系必须一致。
- 参数:
recordset- 被对称差分析的源记录集,必须是面。xORRecordset- 用于对称差分析的记录集,必须是面。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面数据集进行对称差分析运算。
public void overlayAnalystXOR2() { // 返回被对称差分析的记录集与用于对称差分析的记录集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetXORed = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); Recordset queryResultXORed = datasetXORed.getRecordset(false, CursorType.DYNAMIC); DatasetVector datasetXOR = (DatasetVector) targetDatasource.getDatasets(). get("ResidentialArea"); QueryParameter queryParamXOR = new QueryParameter(); queryParamXOR.setAttributeFilter("ClassID = 32023"); queryParamXOR.setHasGeometry(true); Recordset queryResultXOR = datasetXOR.query(queryParamXOR); // 创建一个面矢量数据集,用于存储对称差分析的结果 String resultDatasetXORName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetXOR"); DatasetVectorInfo datasetvectorInfoXOR = new DatasetVectorInfo(); datasetvectorInfoXOR.setType(DatasetType.REGION); datasetvectorInfoXOR.setName(resultDatasetXORName); datasetvectorInfoXOR.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetXOR = targetDatasource.getDatasets().create( datasetvectorInfoXOR); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamXOR = new OverlayAnalystParameter(); overlayAnalystParamXOR.setTolerance(0.0089078724); // 调用对称差分析方法实对称差分析 OverlayAnalyst.xOR(queryResultXORed, queryResultXOR, resultDatasetXOR, overlayAnalystParamXOR); // 释放工作空间占有的资源 workspace.dispose(); }
-
xOR
public static boolean xOR(DatasetVector dataset, Geometry[] xorGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对面数据集用面对象数组进行对称差分析运算,即交集取反运算。操作的结果是,对于面数据集中的每一个面对象,去掉其与面对象数组中的对象相交的部分,而保留剩下的部分。有关对称差运算的详细介绍,请参见另一重载方法
xOR的介绍。注意,用于对称差分析的面对象数组,对称差分析的源数据集以及结果数据集的地理坐标系必须一致。
- 参数:
dataset- 对称差分析的源数据集,必须是面数据集。xorGeometries- 用于对称差分析的面对象数组。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回true,否则返回false。
-
union
public static boolean union(DatasetVector dataset, DatasetVector unionDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对两个面数据集进行合并方式的叠加分析,结果数据集中保存被合并叠加分析的数据集和用于合并叠加分析的数据集中的全部对象,并且对相交部分进行求交和分割运算。注意:
- 合并是求两个数据集并的运算,合并后的图层保留两个数据集所有图层要素,只限于两个面数据集之间进行。
- 进行 union 运算后,两个面数据在相交处多边形被分割,且两个数据集的几何和属性信息都被输出到结果数据集中。
- 用于合并叠加分析的数据集、被合并叠加分析的数据集以及结果数据集的地理坐标系必须一致。

- 参数:
dataset- 被合并叠加分析的数据集,必须是面数据集类型。unionDataset- 用于合并叠加分析的数据集,必须是面数据集类型。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面数据集进行合并方式的叠加分析。
public void overlayAnalystUnion1() { // 返回被合并的矢量数据集与用于合并的矢量数据集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo(rootPath + "/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetUnioned = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); DatasetVector datasetUnion = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); // 创建一个面矢量数据集,用于存储合并分析返回的结果 String resultDatasetUnionName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetUnion"); DatasetVectorInfo datasetvectorInfoUnion = new DatasetVectorInfo(); datasetvectorInfoUnion.setType(DatasetType.REGION); datasetvectorInfoUnion.setName(resultDatasetUnionName); datasetvectorInfoUnion.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetUnion = targetDatasource.getDatasets(). create(datasetvectorInfoUnion); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamUnion = new OverlayAnalystParameter(); overlayAnalystParamUnion.setOperationRetainedFields(new String[] { "Name"}); overlayAnalystParamUnion.setSourceRetainedFields(new String[] { "ClassID"}); overlayAnalystParamUnion.setTolerance(0.0000011074); // 调用合并叠加分析方法实合并分析 OverlayAnalyst.union(datasetUnioned, datasetUnion, resultDatasetUnion, overlayAnalystParamUnion); // 释放工作空间占有的资源 workspace.dispose(); }
-
union
public static boolean union(Recordset recordset, Recordset unionRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对两个面记录集进行合并方式的叠加分析,结果数据集中保存被合并叠加分析的记录集和用于合并叠加分析的记录集中的全部对象,并且对相交部分进行求交和分割运算。有关合并运算的详细介绍,请参见另一重载方法
union的介绍。注意,用于合并叠加分析的记录集、被合并叠加分析的记录集以及结果数据集的地理坐标系必须一致。
- 参数:
recordset- 被合并叠加分析的记录集,必须是面。unionRecordset- 用于合并叠加分析的记录集,必须是面。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面记录集进行合并方式的叠加分析。
public void overlayAnalystUnion2() { // 返回被合并的记录集与用于合并的记录集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetUnioned = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); QueryParameter queryParamUnioned = new QueryParameter(); queryParamUnioned.setAttributeFilter("ClassID = 32023"); queryParamUnioned.setHasGeometry(true); Recordset queryResultUnioned = datasetUnioned.query(queryParamUnioned); DatasetVector datasetUnion = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); Recordset queryResultUnion = datasetUnion.getRecordset(false, CursorType.DYNAMIC); // 创建一个面矢量数据集,用于存储合并分析返回的结果 String resultDatasetUnionName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetUnion"); DatasetVectorInfo datasetvectorInfoUnion = new DatasetVectorInfo(); datasetvectorInfoUnion.setType(DatasetType.REGION); datasetvectorInfoUnion.setName(resultDatasetUnionName); datasetvectorInfoUnion.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetUnion = targetDatasource.getDatasets(). create(datasetvectorInfoUnion); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamUnion = new OverlayAnalystParameter(); overlayAnalystParamUnion.setOperationRetainedFields(new String[] { "Name"}); overlayAnalystParamUnion.setSourceRetainedFields(new String[] { "ClassID"}); overlayAnalystParamUnion.setTolerance(0.0000011074); // 调用合并叠加分析方法实合并分析 OverlayAnalyst.union(queryResultUnioned, queryResultUnion, resultDatasetUnion, overlayAnalystParamUnion); // 释放工作空间占有的资源 workspace.dispose(); }
-
union
public static boolean union(DatasetVector dataset, Geometry[] unionGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对面数据集用面对象数组进行合并方式的叠加分析,结果数据集中保存被合并叠加分析的数据集和用于合并叠加分析的面对象数组中的全部对象,并且对相交部分进行求交和分割运算。有关合并运算的详细介绍,请参见另一重载方法
union的介绍。注意,用于合并叠加分析的面对象数组、被合并叠加分析的数据集以及结果数据集的地理坐标系必须一致。
- 参数:
dataset- 被合并叠加分析的数据集,必须是面数据集。unionGeometries- 用于合并叠加分析的面对象数组。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回true,失败返回fale。
-
update
public static boolean update(DatasetVector dataset, DatasetVector updateDataset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对两个面数据集进行更新方式的叠加分析,更新运算时用用于更新的数据集替换与被更新数据集重合的部分,是一个先擦除后粘贴的过程。用于更新叠加分析的数据集、被更新叠加分析的数据集以及结果数据集的地理坐标系必须一致。
第一数据集与第二数据集的类型都必须是面数据集。结果数据集中保留了更新数据集的几何形状和属性信息。

- 参数:
dataset- 被更新叠加分析的数据集,必须是面类型。updateDataset- 用于更新叠加分析的数据集,必须是面数据集。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面数据集进行更新方式的叠加分析。
public void overlayAnalystUpdate1() { // 返回被更新的矢量数据集与用于更新的矢量数据集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetUpdated = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); DatasetVector datasetUpdate = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); // 创建一个面矢量数据集,用于存储更新分析返回的结果 String resultDatasetUpdateName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetUpdate"); DatasetVectorInfo datasetvectorInfoUpdate = new DatasetVectorInfo(); datasetvectorInfoUpdate.setType(DatasetType.REGION); datasetvectorInfoUpdate.setName(resultDatasetUpdateName); datasetvectorInfoUpdate.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetUpdate = targetDatasource.getDatasets(). create(datasetvectorInfoUpdate); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamUpdate = new OverlayAnalystParameter(); overlayAnalystParamUpdate.setTolerance(0.0089078724); // 调用更新叠加分析方法实更新分析 OverlayAnalyst.update(datasetUpdated, datasetUpdate, resultDatasetUpdate, overlayAnalystParamUpdate); // 释放工作空间占有的资源 workspace.dispose(); }
-
update
public static boolean update(Recordset recordset, Recordset updateRecordset, DatasetVector resultDataset, OverlayAnalystParameter parameter)
用于对两个面记录集进行更新方式的叠加分析,更新运算是用用于更新的记录集替换它与被更新记录集的重合部分,是一个先擦除后粘贴的过程。有关更新运算的详细介绍,请参见另一重载方法
update的介绍。注意,用于更新叠加分析的记录集,被更新叠加分析的记录集以及结果数据集的地理坐标系必须一致。
- 参数:
recordset- 被更新叠加分析的记录集,必须是面类型。updateRecordset- 用于更新叠加分析的记录集,必须是面类型。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回值为true,失败返回值为false。
- Example:
- 以下代码示范了对两个面记录集进行更新方式的叠加分析。
public void overlayAnalystUpdate2() { // 返回被更新的记录集与用于更新的记录集 Workspace workspace = new Workspace(); String rootPath = android.os.Environment.getExternalStorageDirectory().getAbsolutePath(); DatasourceConnectionInfo datasourceConnectionInfo = new DatasourceConnectionInfo( rootPath + "/SampleData/changchun/changchun.udb", "changchun", ""); Datasource targetDatasource = workspace.getDatasources().open( datasourceConnectionInfo); DatasetVector datasetUpdated = (DatasetVector) targetDatasource. getDatasets().get("Frame_R"); Recordset queryResultUpdated = datasetUpdated.getRecordset(false, CursorType.DYNAMIC); DatasetVector datasetUpdate = (DatasetVector) targetDatasource. getDatasets().get("ResidentialArea"); QueryParameter queryParamUpdate = new QueryParameter(); queryParamUpdate.setAttributeFilter("ClassID = 32023"); queryParamUpdate.setHasGeometry(true); Recordset queryResultUpdate = datasetUpdate.query(queryParamUpdate); // 创建一个面矢量数据集,用于存储更新分析返回的结果 String resultDatasetUpdateName = targetDatasource.getDatasets(). getAvailableDatasetName( "resultDatasetUpdate"); DatasetVectorInfo datasetvectorInfoUpdate = new DatasetVectorInfo(); datasetvectorInfoUpdate.setType(DatasetType.REGION); datasetvectorInfoUpdate.setName(resultDatasetUpdateName); datasetvectorInfoUpdate.setEncodeType(EncodeType.NONE); DatasetVector resultDatasetUpdate = targetDatasource.getDatasets(). create(datasetvectorInfoUpdate); // 设置叠加分析参数 OverlayAnalystParameter overlayAnalystParamUpdate = new OverlayAnalystParameter(); overlayAnalystParamUpdate.setTolerance(0.0000013678); // 调用更新叠加分析方法实更新分析 OverlayAnalyst.update(queryResultUpdated, queryResultUpdate, resultDatasetUpdate, overlayAnalystParamUpdate); // 释放工作空间占有的资源 workspace.dispose(); }
-
update
public static boolean update(DatasetVector dataset, Geometry[] updateGeometries, DatasetVector resultDataset, OverlayAnalystParameter parameter)
对面数据集用面对象数组进行更新方式的叠加分析,更新运算时用用于更新的面对象数组替换与被更新数据集的重合部分,是一个先擦除后粘贴的过程。有关更新运算的详细介绍,请参见另一重载方法
update的介绍。注意,用于更新叠加分析的面对象数组、被更新叠加分析的数据集以及结果数据集的地理坐标系必须一致。
- 参数:
dataset- 被更新叠加分析的数据集,必须是面数据集。updateGeometries- 用于更新叠加分析的面对象数组。resultDataset- 存放分析结果的数据集。parameter- 叠加分析的参数对象,该对象用于设置分析时的保留字段等分析参数。- 返回:
- 分析成功返回true,失败返回false。
-
clipEx
public static boolean clipEx(DatasetVector dataset, Geometry clipRegion, DatasetVector resultDataset, boolean bClipInRegion, boolean bEraseFromSrc, double dTolerace)
裁剪数据- 参数:
dataset- 数据集clipRegion- 裁剪面resultDataset-bClipInRegion-bEraseFromSrc-dTolerace-- 返回:
-
clipCAD
public static boolean clipCAD(DatasetVector dataset, Geometry clipRegion, DatasetVector resultDataset, boolean bClipInRegion, boolean bErase, double dTolerace)
裁剪CAD.- 参数:
dataset- 被裁数据集clipRegion- 裁剪区域resultDataset- 裁剪结果数据集bClipInRegion- 是否在裁剪区域内,true表示裁剪区域内部bErase- 是否擦除dTolerace- 容限- 返回:
- 裁剪是否成功
-
clipText
public static boolean clipText(DatasetVector dataset, Geometry clipRegion, DatasetVector resultDataset, boolean bClipInRegion, boolean bErase, double dTolerace)
裁剪文本数据集.- 参数:
dataset- 被裁数据集clipRegion- 裁剪区域resultDataset- 裁剪结果数据集bClipInRegion- 是否在裁剪区域内,true表示裁剪区域内部bErase- 是否擦除dTolerace- 容限- 返回:
- 裁剪是否成功