



Feature Description
merging objects in a line dataset, a surface dataset and a text dataset which meet certain conditions into an object。This function is applicable to line datasets, 2D region datasets, 3D line datasets, and text datasets. Text dataset dissolve only supports the Group processing method by default.
The following conditions must be met for dataset dissolve:
- The values of a certain field between data objects are the same.
- Line objects must have coincident endpoints to be dissolved.
- Region objects must intersect or be adjacent (share a common edge).
The dataset dissolve function includes three processing methods: dissolve, group, and group after dissolving.
- Fusion:
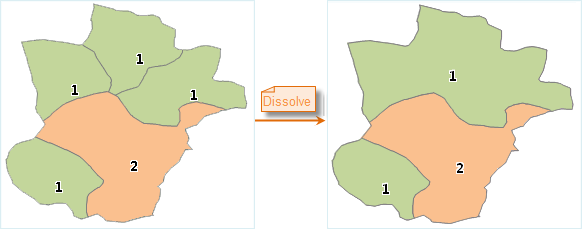
Dissolve objects numbered 1 As shown in the results above, dissolve merges multiple sub-objects into a single simple object. Areas numbered 1 are dissolved, but non-adjacent objects are not dissolved.
- Group:
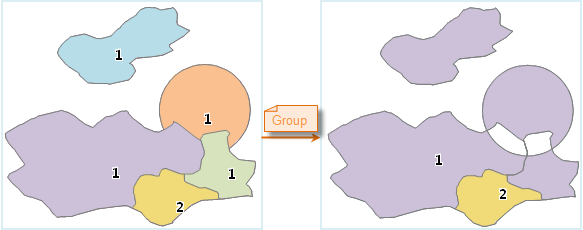
Objects numbered 1 are grouped into a compound As shown in the results above, group combines multiple sub-objects into a compound object, where the intersecting parts of the objects are processed using an XOR operation.
-
Group after Dissolving:

Objects with the same number are first dissolved and then grouped into a compound Objects with the same property field value and that intersect or are tangent are first dissolved into a simple object. If, after dissolving, there remain non-adjacent objects with the same merged field value, they are further grouped into a complex object.
Function Entrance
- Data Tab -> Data Processing Group -> Vector -> Fusion。
- Toolbox -> Data Processing -> Vector -> Fusion。
Parameter description
- Source Dataset:Displays all line and region datasets under the selected datasource. Select the dataset to be dissolved.
- Dissolve Mode :The system provides three dissolve modes.
- Fusion:Merge objects with the same property field value and that intersect or are within the fusion tolerance range into a single object.
- Group:Group objects with the same property field value into a single object, removing the overlapping parts.
- Group after Dissolving:Objects with the same property field value and that intersect or are tangent are first dissolved into a simple object. If, after dissolving, there remain non-adjacent objects with the same merged field value, they are further grouped into a complex object.
- Fusion tolerance:If the distance between two or more nodes after dissolving is within this tolerance range, they will be merged into one node. The default value is one millionth of the dataset's boundary range (the maximum tolerance is 100 times the default tolerance), and the unit is the original unit of the dataset.
 Note:
Note:When dissolving text datasets, only the Group method is supported, and the fusion tolerance cannot be set (meaningless).
- Filter Expression: Only objects meeting this condition will participate in the dissolve operation.
- Process objects which have no field values:Check this box to include objects with empty merged field values in the dissolve operation.
- Merged Field: Fields in the dataset with the same field value. Data is dissolved or grouped based on the value of this field.
- Statistic Field: Perform field statistics on the dissolved objects (generate a new field to store the statistical value). The statistics type can be Max, Min, Sum, Average, First Object, Last Object, or Text Link.
- Max:Calculate the maximum value of the field for the dissolved/grouped objects. Only valid for numeric and time-type fields.
- Min:Calculate the minimum value of the field for the dissolved/grouped objects. Only valid for numeric and time-type fields.
- Sum:Calculate the sum of the field for the dissolved/grouped objects. Only valid for numeric fields.
- Average:Calculate the average value of the field for the dissolved/grouped objects. Only valid for numeric fields.
- First Object:Obtain the field value corresponding to the object with the smallest SmID within the dissolved/grouped objects.
- Last Object:Obtain the field value corresponding to the object with the largest SmID within the dissolved/grouped objects.
- Text Link:Obtain a string where the field values of the dissolved/grouped objects are connected by semicolons (;). Only valid for text fields. Application scenario: A highway dataset contains an administrative division field. During dissolve, the values of this field need to be connected with semicolons to show which administrative divisions the highway passes through.
Note:
When using this type, the merged field must be set, and the merged field values for text link objects need to be the same.
- Preserve the table structure of the source dataset:Check to preserve the table structure of the source dataset. When this parameter is checked, the table structure of the source dataset is preserved, meaning all other fields not selected as the merged field or statistic field are retained, and the field's values are empty.
- Result Data:Name and save the dissolve result dataset, and select the datasource where the dataset will be located.
Note:When the merged field values are the same, if the endpoints of three (or more) line segments coincide at a single point, the system will not perform the dissolve operation.
Related Topics