



Instructions for use
Data lineage refers to the relationship formed between data during its lifecycle of generation, processing, flow, and extinction, akin to a lineage in human society. It is a concept in data governance. In simple terms, it expresses where the data came from and what processing and analysis it has undergone. The knowledge graph provides a solution for the extraction, storage, querying, and visualization of data lineage.
SuperMap provides the capability to write the data lineage relationships from the execution process of GPA (Geospatial Process Automation) into a graph database. The constructed data graph can visually display the data processing flow and provides the ability to perform upward traceability and downward tracking on datasets.
- Performing upward traceability on a dataset in question allows you to obtain its production chain. When data quality issues arise, this can help interpret the source and identify the cause.
- Performing downward tracking on a dataset in question allows you to understand its subsequent impact.
Saving the GPA's data lineage to a graph database means using GPA tools, datasets, and their attributes as graph entities, and the data processing steps as graph relationships. As shown in the figure below, the input dataset is precipitation data, which undergoes an Update Column process to yield a new precipitation dataset. Here, the graph nodes are the input and output data, along with the GPA tool, and the relationships are "input" and "output".

Procedure
- Enable data lineage:
- GPA tab -> Data Lineage -> Save Data Lineage. Once enabled, the execution process will be written to the graph database.
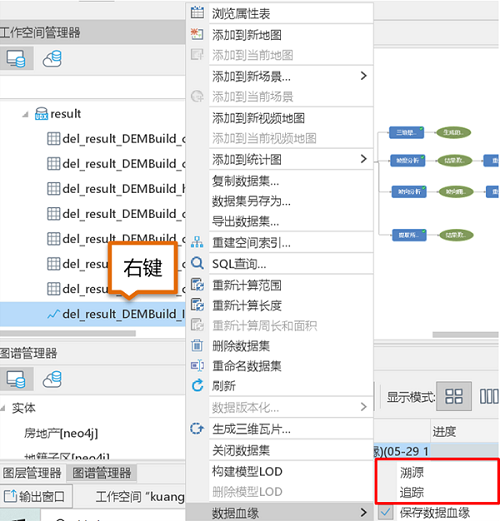
- Directly in the Workspace Manager, select a dataset -> right-click -> data lineage -> save data lineage.
- If Connect the Graph Database is not established after checking "save data lineage", you need to connect first before you can save and apply data lineage.
- Execute the GPA (Geospatial Process Automation) model.
- Query or explore the lineage of the executed result dataset:
- Knowledge Graph tab -> Graph Query, where you can use cypher query.
- Directly in the Workspace Manager, select a dataset -> right-click -> data lineage -> traceability / tracking.
- After opening the data lineage graph, you can click on the node properties of a data entity in the graph window. These properties include data address, record count, coordinates, extent, execution time, etc. Changes in data attributes along the chain can help explore how the data has changed.