



Feature Description
Extracts samples with equal probability in geospatial context. Considers various sampling methods and schemes incorporating spatial attributes like spatial autocorrelation and heterogeneity, including six approaches: simple random sampling, system random sampling, spatial simple random sampling, stratum random sampling, spatial stratification random sampling, and sandwich random sampling.
Feature Entry
- Spatial Statistics Tab->Spatial Sampling and Statistical Inference->Random Sampling.
- Toolbox->Spatial Statistics->Spatial Sampling and Statistical Inference->Random Sampling.
Parameter Description
Random Sampling Type: Includes six methods - simple random sampling, system random sampling, spatial simple random sampling, stratum random sampling, spatial stratification random sampling, and sandwich random sampling. Choose appropriate model based on data characteristics.
Use Proportional Value: Two value types available - scaled value and proportional value
Sampling Resolution: For vector basemaps, specifies grid cell width used to create sampling space during grid-based sampling process.
Sampling Amplification Ratio: Percentage to multiply theoretical sample size for practical implementation. Compensates for potential sample unavailability or data loss. Default: 0.1
Spatial Correlation Coefficient: Calculate Moran's I via spatial autocorrelation function. (Required only for Spatial Simple Random Sampling)
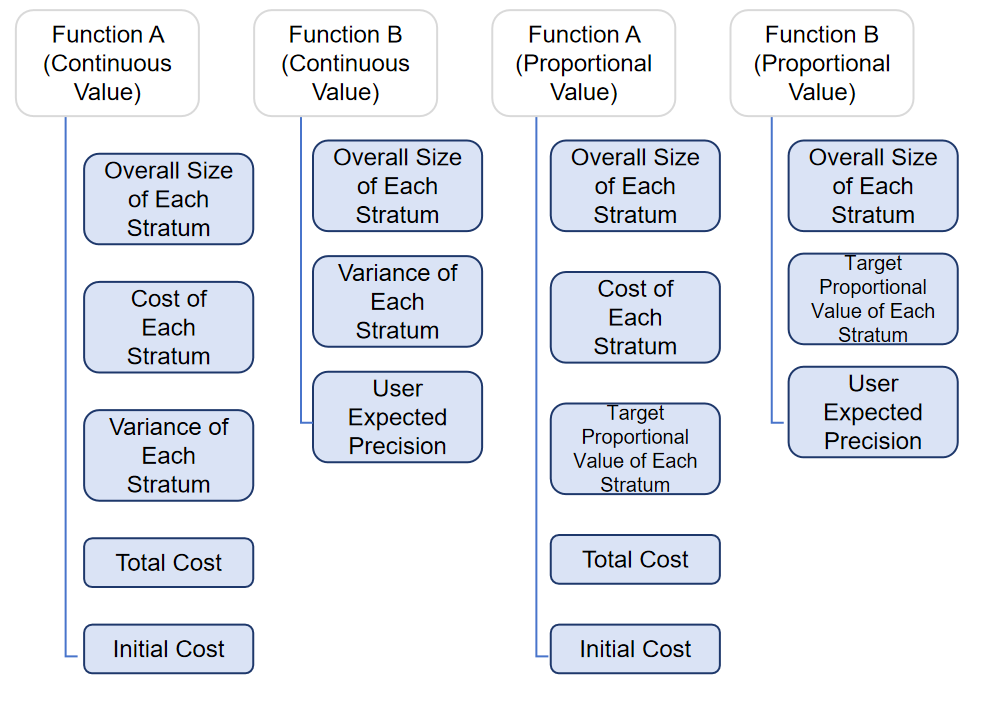
Sampling Calculation Function: Functions for sample size calculation vary by sampling model and input value type.
Parameter Explanations:
Population Variance: True variance from sampling space, typically obtained from historical surveys.
Expected Variance: Desired estimation variance for current sampling.
Total Cost: Budget for sampling (reference only, not used in calculations).
Initial Cost: Specified setup cost.
Stratum Variance Field: Designated variance field for each stratum.
Stratum Cost Field: Designated cost field for each stratum.
Absolute Error: Difference between estimate and true value, represented as variance of population estimates.
Relative Error: (Sample mean - target value)/target value.
Confidence Interval Parameter: Confidence level expressed as (1 - alpha/2)% under normal distribution assumption.
Initial Iteration Sample Size: Starting sample size for t-distribution calculation in iterative process. Default: 1 (recommend not to modify).
Pre-sampling Mean: Preliminary survey mean value.
Pre-sampling Variance: Variance from preliminary survey.
Pre-sampling Sample Size: Number of samples in preliminary survey.
Coefficient of Variation: Ratio of standard deviation to mean (C.V), enables comparison across different units.
Sampling Amplification Ratio: Percentage to multiply theoretical sample size for practical implementation.
Population Proportion: Percentage representing survey target value.
Unknown Cost: Specifies whether cost information is unknown.
Stratum Variance Field: Designated variance field for each stratum.
- Source Dataset: Specifies the dataset and datasource for random sampling.
- Sampling Extent/Stratum Data: Defines sampling extent or stratum dataset with its datasource. Stratum data refers to hierarchical division of study area based on expert knowledge, historical data, and auxiliary information, aiming to minimize intra-stratum variance and maximize inter-stratum variance (significant spatial heterogeneity). Strata can be geographic or attribute-based, not requiring spatial continuity.
- Reporting Unit Data: Specifies reporting unit dataset and datasource for sandwich random sampling. Reporting units are top-level units in the "sandwich" model, which can be administrative units, natural units, grid cells, or any user-defined spatial units. Final results provide estimates for each reporting unit. (Required only for Sandwich Random Sampling)
- Parameters: Configuration varies by random sampling type.
- Unchecked: Uses scaled values with units (e.g., temperature in °C, precipitation in mm).
- Checked: Uses dimensionless proportional values (e.g., crop yield ratio %, incidence rate %).
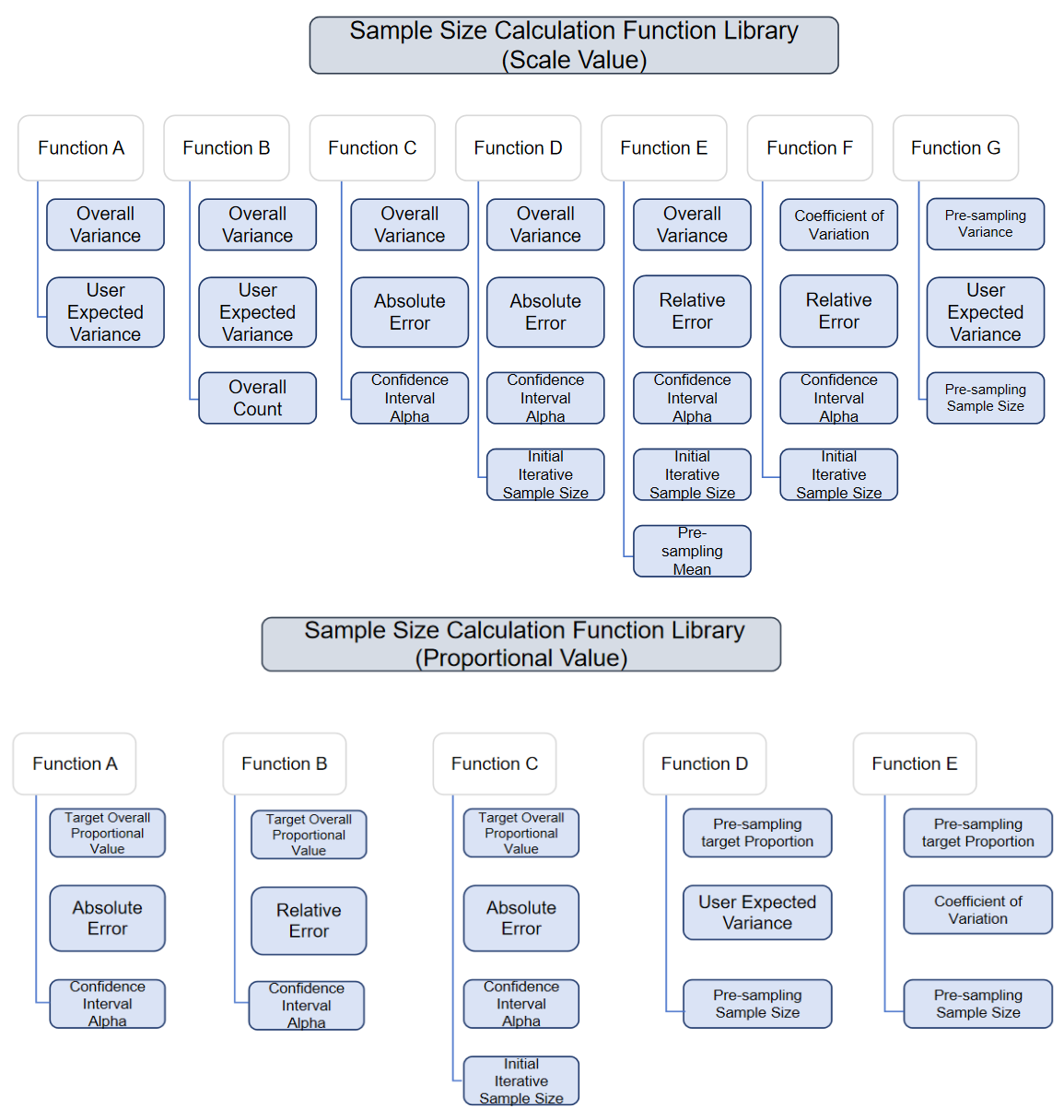
- For simple/system/spatial random sampling models, functions are shown below:
- For stratification/spatial stratification/sandwich sampling models, functions are shown below:
- Result Data: Specifies result dataset and datasource.
Application Case
To estimate total population of Heshun County (1998) through stratified sampling across 10 townships containing 326 villages, requiring population standard deviation ≤12626 (mean variance ≤1500 in software). Township-specific village counts and population standard deviations were estimated from historical data.
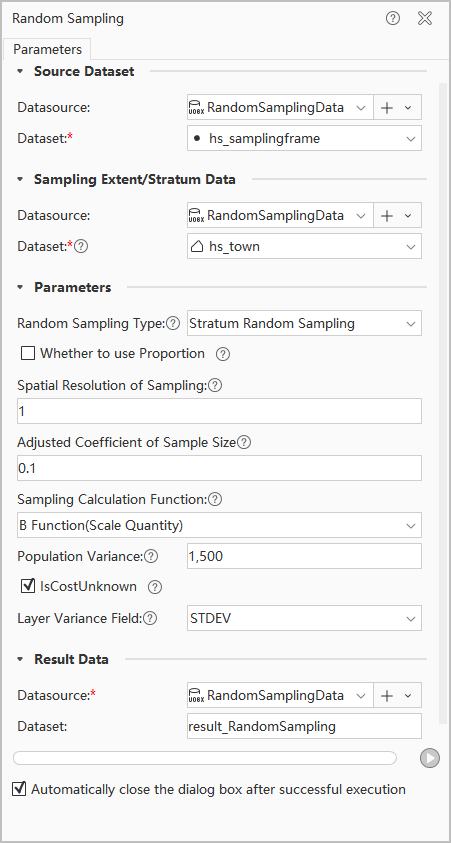
- Case Data: Download stratum random sampling case data including:
- hs_samplingframe: Village point dataset
- hs_town: Township administrative data as stratum data. Attributes: CODE (township ID), NAME (township name), NUM (village count), STDEV (historical population standard deviation)
- Parameters: Open RandomSamplingData.udbx, configure source data, stratum data, sampling type, calculation functions, and population variance as shown below. Click Execute to perform stratum random sampling.
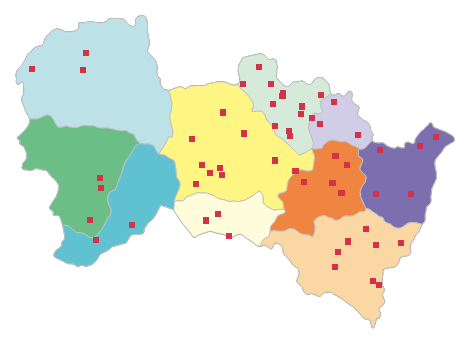
- Result Explanation: 55 sample villages selected. Attributes include Layered_ID (stratum ID) and Layered_PopulationSize (total villages in stratum). Spatial and attribute results:
- Post-processing: Manually input population data for sampled villages:
- Create field: Right-click result_RandomSampling dataset, select "Properties", create Value field (short) in Table panel.
- Input attributes: Enter population for each sample village. Processed data: