类 DatasetVector
- java.lang.Object
-
- com.supermap.data.InternalHandle
-
- com.supermap.data.Dataset
-
- com.supermap.data.DatasetVector
-
public class DatasetVector extends Dataset
矢量数据集类。
用于对矢量数据集进行描述,并对之进行相应的管理和操作。对矢量数据集的操作主要包括数据查询、修改、删除、建立索引等。
用户在对矢量数据集进行操作之前,需要先打开该数据集,即调用打开数据集的方法——
Dataset.open()方法。
-
-
方法概要
所有方法 实例方法 具体方法 已过时的方法 限定符和类型 方法和说明 booleanaddAttachments(DatasetVector matchDataset)根据生成的附件匹配表批量添加附件。BooleanaddCollectionDataset(DatasetVector dtv)数据集集合添加一个子数据集。booleanaddRelationDataset(RelationDatasetInfo rdInfo)增加实体数据集的关系数据集booleanappend(Recordset recordset)用于将记录集(Recordset)追加到矢量数据集(DatasetVector)中。booleanappend(Recordset recordset, String tileName)用于将记录集(Recordset)按图幅名字追加到矢量数据集(DatasetVector)中,要求该矢量数据集的空间索引为图幅索引,追加后记录集中的所有记录将作为图幅索引的一幅。booleanappend(Recordset recordset, String[] sourceFields, String[] targetFields)将记录集中源字段数组对应的记录,按照目标字段数组对矢量数据集追加行。booleanappendFields(DatasetVector sourceDataset, String sourceLinkFieldName, String targetLinkFieldName, String[] sourceFields)从源数据集向目标数据集追加字段,并根据关联字段查询结果对字段进行赋值。booleanappendFields(DatasetVector sourceDataset, String sourceLinkFieldName, String targetLinkFieldName, String[] sourceFields, String[] targetFields)从源数据集向目标数据集追加字段,并根据关联字段查询结果对字段进行赋值。booleanbuildFieldIndex(String[] fieldName, String indexName)为数据集的非空间字段创建索引。booleanbuildSpatialIndex(SpatialIndexInfo spatialIndexInfo)根据指定的空间索引信息为矢量数据集创建空间索引。booleanbuildSpatialIndex(SpatialIndexType spatialIndexType)根据给定的空间索引类型来为矢量数据集创建空间索引。booleanbuildVectorPyramid(int[] levels, double[] tolerances, boolean[] preserveCollapseds, String[] filters, String geometryName, String[] fieldnames)创建矢量金字塔。booleancomputeAreaLength()紧缩面积长度是否成功Rectangle2DcomputeBounds()重新计算数据集的空间范围。booleancopyFieldsToPyramid(String[] fields)复制字段到矢量金字塔。booleancreateGridCodeFiled()创建空间网格编码文件,用于存储数据库中空间对象的网格编码信息。BooleanDeleteDatasetFromCollection(DatasourceConnectionInfo info, String datasetName)删除数据集合子数据集。booleandeleteRecords(int[] id)删除数据集中指定 ID 的记录。booleandeleteRecords(long[] id)通过 ID 数组删除数据集中的记录。booleandeleteRelationDataset(RelationDatasetInfo rdInfo)删除实体数据集的关系数据集booleandropFieldIndex(String indexName)根据索引名指定字段,删除该字段的索引。booleandropGridCodeFiled()返回空间网格编码文件。booleandropSpatialIndex()删除空间索引。booleandropVectorPyramid()删除矢量金字塔。booleandropVectorPyramid(String geometryName)删除指定几何字段创建的矢量金字塔。DatasetVectorgenerateAttachmentMatchTable(String folderPath, String fieldName, String matchDatasetName, String fileFilter)通过过滤条件筛选出符合条件的文件,与源数据集生成匹配关系。Map<Integer,Feature>getAllFeatures()返回矢量数据集中的所有特征要素集。String[]getAssociatedRelationshipNames()获取当前数据集参与的关系数据集名称。StringgetAvailableFieldName(String name)根据传入参数生成一个合法的字段名。CharsetgetCharset()返回矢量数据集的字符集。DatasetVectorgetChildDataset()返回矢量数据集的子数据集。DatasetVector[]getChildDatasets()获取图幅索引的子数据集。intgetCollectionDatasetCount()获取数据集集合中子数据集的个数。ArrayList<CollectionDatasetInfo>getCollectionDatasetInfos()获取数据集集合中所有子数据集的信息。ContingenciesgetContingencies()获取矢量数据集的条件值集合,从数据库中重新读取条件值集合。DatasetIDTypegetDatasetIDType()获取数据集 ID 标识符类型。intgetFieldCount()返回矢量数据集中字段的数目。FieldGroupsgetFieldGroups()返回矢量数据集的字段组集合,从数据库中重新读取字段组集合。Map<String,String>getFieldIndexes()返回当前数据集属性表建的索引与建索引的字段的关系映射对象。FieldInfosgetFieldInfos()返回字段信息集合的对象。StringgetFieldNameBySign(FieldSign value)根据字段标识获取字段名。String[]getGeoFieldNames()获取数据集中用于存储对象几何信息的字段名称。booleangetHasM()返回数据集是否有M值booleangetHasZ()返回数据集是否有Z值StringgetIDFieldName()获取数据集的唯一ID字段名。int[]getIDsByGeoRelation(DatasetVector sourceDataset, SpatialRelationType spatialRelationType, boolean isBorderInside, boolean isShowProgress)从另一数据集中获取与当前数据集的对象满足一定空间关系的对象的 ID。int[]getIDsByGeoRelation(Geometry[] sourceGeometries, SpatialRelationType spatialRelationType, boolean isBorderInside, boolean isShowProgress)从给定的几何对象集合中获取与当前数据集的对象满足一定空间关系的对象的 ID。int[]getIDsByGeoRelation(Recordset sourceRecordset, SpatialRelationType spatialRelationType, boolean isBorderInside, boolean isShowProgress)从另一记录集中获取与当前数据集的对象满足一定空间关系的对象的 ID。doublegetMaxZ()获取模型数据集最大值。doublegetMinZ()获取模型数据集最小值。DatasetgetParentDataset()返回矢量数据集的父数据集。intgetRecordCount()返回矢量数据集中全部记录的数目。RecordsetgetRecordset(boolean isEmptyRecordset, CursorType cursorType)根据给定的参数来返回空的记录集或者返回包括所有记录的记录集对象。ArrayList<RelationDatasetInfo>getRelationDatasets()获取实体数据集的关系数据集RelationshipRulesgetRelationshipRules()获取关系数据集的规则。RelationshipSettinggetRelationshipSetting()获取关系数据集的配置信息。booleangetRenameDuplicateMaterials()返回是否重命名重复材质。SpatialIndexTypegetSpatialIndexType()返回当前的空间索引类型。DatasetTypeGetSubCollectionDatasetType()获取数据集集合中子数据集的数据集类型。SubtypesgetSubtypes()获取子类。StringgetSubtypesFieldName()获取子类的关联字段名称。TextDatasetExtensiongetTextDatasetExtension()获取文本数据集作为复合关系中目标数据集时的扩展信息。TolerancegetTolerance()返回矢量数据集的容限,单位与数据集的单位相同。VectorPyramidConfigInfogetVectorPyramidConfigInfo()获取创建矢量金字塔的配置参数信息。booleanhasPyramid()判断是否存在矢量金字塔。booleanhasPyramid(String geometryName)判断指定几何字段是否创建了矢量金字塔。booleanisAssociatedWithRelationship()判断数据集是否被加入了关系数据集。booleanisAvailableFieldName(String fieldName)用于判断属性数据表中字段名是否合法。booleanisCreateGridCodeFiled()返回是否已创建空间网格编码。booleanisFileCache()返回是否使用文件形式的缓存。booleanisSimpliFy()获取postgis是否设置抽析booleanisSpatialIndexDirty()返回矢量数据集中空间索引是否需要重建。booleanisSpatialIndexTypeSupported(SpatialIndexType spatialIndexType)判断当前数据集是否支持指定的类型的空间索引。booleanisSQLQuery()判断数据集是否为用户通过过滤条件生成的临时数据集。Recordsetquery(Geometry geometry, double bufferDistance, CursorType cursorType)用于查询数据集中落在指定空间对象的缓冲区内的记录。Recordsetquery(Geometry geometry, double bufferDistance, String attributeFilter, CursorType cursorType)用于查询数据集中落在指定空间对象的缓冲区内,并且满足一定条件的记录。Recordsetquery(int[] id, CursorType cursorType)根据 ID 进行查询。Recordsetquery(int[] id, String idFieldName, CursorType cursorType)根据指定字段做ID查询,指定字段类型必须是整型。Recordsetquery(long[] id, CursorType cursorType)根据指定字段做ID查询,指定字段类型必须是长整型。Recordsetquery(long[] id, String idFieldName, CursorType cursorType)根据指定字段做ID查询,指定字段类型必须是长整型。Recordsetquery(QueryParameter queryParameter)通过设置查询条件对矢量数据集进行查询,该方法默认查询空间信息与属性信息。Recordsetquery(Rectangle2D bounds, CursorType cursorType)用于查询落在已知空间范围内的记录。Recordsetquery(Rectangle2D bounds, String attributeFilter, CursorType cursorType)用于查询落在已知空间范围内,并且满足一定条件的记录。Recordsetquery(String attributeFilter, CursorType cursorType)利用查询条件查询数据。booleanreBuildSpatialIndex()在原有的空间索引的基础上进行重建,如果原来的空间索引被破坏,那么重建成功之后还可以继续使用。booleanregisterAttachment()将数据集注册为附件数据集。booleanregisterVersion()对数据集注册版本,数据集需注册版本,才能进入版本管理工作流程。booleanremoveAttachments(DatasetVector matchDataset)根据附件匹配表移除附件。booleanresample(ResampleInformation resampleInfo, boolean isShowProgress, boolean isSaveSmallGeometry)对矢量数据集进行重采样,支持线数据集、面数据集和网络数据集。booleanresample(ResampleInformation resampleInfo, boolean isShowProgress, boolean isSaveSmallGeometry, SteppedListener... listenrs)对矢量数据集进行重采样,支持线数据集、面数据集和网络数据集。voidsetCharset(Charset value)设置矢量数据集的字符集。booleansetContingencies(Contingencies contingencies)设置矢量数据集的条件值集合,将条件值集合保存到数据库中。booleansetFieldGroups(FieldGroups fieldGroups)设置矢量数据集的字段组集合,将字段组集合保存到数据库中。voidsetFileCache(boolean value)设置是否使用文件形式的缓存。voidsetGeoFieldName(String strGeoName)用户查询结果保存的数据集,如果存在多个geometry类型字段,可设置其中一个geometry类型字段,作为对象的空间几何进行地图展示,仅用于 Yukon 和 PostGIS 空间数据引擎。voidsetIDFieldName(String strUserID)对用户查询结果保存的数据集设置唯一ID字段,仅用于 Yukon 和 PostGIS 空间数据引擎。voidsetIsSimpliFy(boolean value)设置postgis是否抽析booleansetRecordCount(int value)返回矢量数据集数目是否设置成功booleansetRelationshipRules(RelationshipRules relationshipRules)设置关系数据集的规则。voidsetRenameDuplicateMaterials(boolean rename)设置是否重命名重复材质。booleansetSubtypes(Subtypes subtypes)设置子类。booleansetSubtypesFieldName(String fieldname)设置子类的关联字段名称。booleansetTextDatasetExtension(TextDatasetExtension textDatasetExtension)设置文本数据集作为复合关系中目标数据集时的扩展信息。voidsetTolerance(Tolerance tolerance)设置矢量数据集的容限,单位与数据集的单位相同。booleansmooth(int smoothness, boolean isShowProgress)对矢量数据集进行平滑,支持线数据集、面数据集和网络数据集。booleansmooth(int smoothness, boolean isSaveTopology, boolean isShowProgress)对矢量数据集进行平滑,支持线数据集、面数据集和网络数据集。doublestatistic(int fieldIndex, StatisticMode mode)对指定的字段按照给定的方式进行统计。doublestatistic(String fieldName, StatisticMode mode)通过字段名称指定字段,对指定的字段按照给定的方式进行统计。booleantruncate()清除矢量数据集中的所有记录。booleanunregisterAttachment()数据集取消注册附件。booleanunRegisterVersion()对数据集取消注册版本,数据集取消注册版本后,将退出版本管理工作流程。booleanupdateField(int fieldIndex, Object value, String attributeFilter)根据指定的需要更新的字段序号,用指定的用于更新的字段值更新符合 attributeFilter 条件的所有记录的字段值。booleanupdateField(int fieldIndex, String expression, String attributeFilter)根据指定的需要更新的字段序号,用指定的表达式计算结果更新符合查询条件的所有记录的字段值。booleanupdateField(int fieldIndex, String expression, String attributeFilter, JoinItems joinItems)根据指定的需要更新的字段序号,用指定的表达式计算结果更新符合查询条件的所有记录的字段值,需要更新的字段不能够为系统字段(SmUserID除外)。booleanupdateField(String fieldName, Object value, String attributeFilter)根据指定的需要更新的字段名称,用指定的用于更新的字段值更新符合 attributeFilter 条件的所有记录的字段值。booleanupdateField(String fieldName, String expression, String attributeFilter)根据指定的需要更新的字段名,用指定的表达式计算结果更新符合查询条件的所有记录的字段值。booleanupdateField(String fieldName, String expression, String attributeFilter, JoinItems joinItems)根据指定的需要更新的字段序号,用指定的表达式计算结果更新符合查询条件的所有记录的字段值,需要更新的字段不能够为系统字段(SmUserID除外)。booleanupdateFields(AttributeUpdateInfo info, boolean isShowProgress)booleanupdateFields(DatasetVector sourceDataset, SpatialRelationType spatialRelationType, String[] sourceFields, String[] targetFields, AttributeStatisticsType attributeStatisticsType, boolean isBorderInside, String errorName, boolean isShowProgress)已过时。使用updateFields(AttributeUpdateInfo info)DatasetVector.updateFields(AttributeUpdateInfo, boolean))} 方法替代。booleanupdateFields(Recordset sourceRecordset, SpatialRelationType spatialRelationType, String[] sourceFields, String[] targetFields, AttributeStatisticsType attributeStatisticsType, boolean isBorderInside, String errorName, boolean isShowProgress)已过时。使用updateFields(AttributeUpdateInfo info)DatasetVector.updateFields(AttributeUpdateInfo, boolean))} 方法替代。-
从类继承的方法 com.supermap.data.Dataset
addClosedListener, addClosingListener, addLockChangedListener, addSteppedListener, close, dispose, equals, getBounds, getDatasource, getDescription, getEncodeType, getExtInfo, getGeoStoreType, getGroup, getID, getLockState, getName, getPrivilegeTypes, getPrivilegeTypes, getPrjCoordSys, getSchema, getTableName, getTransState, getType, hasAttachment, hashCode, hasPrivilegeGrant, hasPrjCoordSys, isDisposed, isOpen, isReadOnly, isVersioned, open, refresh, removeClosedListener, removeClosingListener, removeLockChangedListener, removeSteppedListener, setBounds, setDescription, setExtInfo, setLockState, setPrivilegeTypes, setPrjCoordSys, setReadOnly, toString
-
-
-
-
方法详细资料
-
getCharset
public Charset getCharset()
返回矢量数据集的字符集。- 返回:
- 矢量数据集的字符集。
-
setCharset
public void setCharset(Charset value)
设置矢量数据集的字符集。- 参数:
value- 矢量数据集的字符集。
-
getChildDataset
public DatasetVector getChildDataset()
返回矢量数据集的子数据集。主要用于网络数据集。- 返回:
- 矢量数据集的子数据集。
-
getParentDataset
public Dataset getParentDataset()
返回矢量数据集的父数据集。主要用于网络数据集。- 返回:
- 矢量数据集的父数据集。
-
isSimpliFy
public boolean isSimpliFy()
获取postgis是否设置抽析- 返回:
-
setIsSimpliFy
public void setIsSimpliFy(boolean value)
设置postgis是否抽析- 参数:
value-
-
isFileCache
public boolean isFileCache()
返回是否使用文件形式的缓存。文件形式的缓存可以提高浏览速度。
注意:文件形式的缓存只对 Oracle 数据源下已创建图幅索引的矢量数据集有效。
- 返回:
- 是否使用文件形式的缓存。使用文件形式的缓存返回 true;否则返回 false。
-
setFileCache
public void setFileCache(boolean value)
设置是否使用文件形式的缓存。文件形式的缓存可以提高浏览速度,只针对数据库型数据源有效。
- 参数:
value- 是否使用文件形式的缓存。
-
getRecordCount
public int getRecordCount()
返回矢量数据集中全部记录的数目。- 返回:
- 矢量数据集中全部记录的数目。
-
setRecordCount
public boolean setRecordCount(int value)
返回矢量数据集数目是否设置成功- 参数:
value-- 返回:
-
getTolerance
public Tolerance getTolerance()
返回矢量数据集的容限,单位与数据集的单位相同。- 返回:
- 矢量数据集对象的悬线容限。
-
setTolerance
public void setTolerance(Tolerance tolerance)
设置矢量数据集的容限,单位与数据集的单位相同。- 参数:
tolerance- 矢量数据集对象的悬线(Dangle)容限,单位与数据集的单位相同。
-
getFieldCount
public int getFieldCount()
返回矢量数据集中字段的数目。- 返回:
- 矢量数据集中字段的数目。
-
getFieldInfos
public FieldInfos getFieldInfos()
返回字段信息集合的对象。即数据集属性表中所有字段的信息。通过此方法得到的
FieldInfos对象不可执行clear()和exchange()方法。- 返回:
- 字段信息集合的对象。
-
getRecordset
public Recordset getRecordset(boolean isEmptyRecordset, CursorType cursorType)
根据给定的参数来返回空的记录集或者返回包括所有记录的记录集对象。- 参数:
isEmptyRecordset- 给定的判断是否返回空的记录集参数。为 true 时返回空记录集。为 false 时返回包含所有记录的记录集合对象。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读。详细信息请参见CursorType类型。- 返回:
- isEmptyRecordset 参数为 true 时返回空的记录集;false 时返回包含所有记录的记录集。
- 另请参阅:
DatasetVector.append(Recordset)- 示范代码:
- 请参见
DatasetVector.append()方法的示例。
-
append
public boolean append(Recordset recordset)
用于将记录集(Recordset)追加到矢量数据集(DatasetVector)中。追加时,记录集与矢量数据集中字段名相同的字段直接追加,矢量数据集中没有而记录集中有的字段将跳过不处理。执行完追加后 recordset 会指向最后一条记录的后面,即 isEOF 方法为 true。
- 参数:
recordset- 添加的记录集对象。- 返回:
- 添加成功返回 true,否则返回 false。
- 示范代码:
- 以下代码示范如何将记录集追加到矢量数据集中。
public void appendTest() { // 前提条件:已打开一个工作空间 workspace 对象,工作空间中存在一个数据源 datasource 对象,数据源中包含两个矢量数据集“World”和“Ocean”。 // 获取两个矢量数据集 DatasetVector datasetVector = (DatasetVector) datasource.getDatasets().get("World"); DatasetVector datasetVector1 = (DatasetVector) datasource.getDatasets().get("Ocean"); // 返回名为“Ocean”的数据集的所有记录,将其追加到名为“World”的数据集中 Recordset recordset = datasetVector1.getRecordset(false,CursorType.DYNAMIC); if (datasetVector.append(recordset)) { System.out.println("追加数据集成功"); } // 释放资源 recordset.dispose(); datasetVector.close(); datasetVector1.close(); }
-
append
public boolean append(Recordset recordset, String tileName)
用于将记录集(Recordset)按图幅名字追加到矢量数据集(DatasetVector)中,要求该矢量数据集的空间索引为图幅索引,追加后记录集中的所有记录将作为图幅索引的一幅。追加时,记录集与矢量数据集中字段名相同的字段直接追加,矢量数据集中没有而记录集中有的字段将跳过不处理。该方法一般用于标准图幅数据入库过程。执行完追加后 recordset 会指向最后一条记录的后面,即 isEOF 方法为 true。
注:目前,仅有
ORACLEPLUS引擎,支持矢量数据集按图幅追加数据。- 参数:
recordset- 添加的记录集对象。tileName- 新增的图幅名称标记。- 返回:
- 添加成功返回 true,否则返回 false。
-
append
public boolean append(Recordset recordset, String[] sourceFields, String[] targetFields)
将记录集中源字段数组对应的记录,按照目标字段数组对矢量数据集追加行。例如:将记录集中的b和c字段追加到矢量数据集的a和b字段中,其中,b和c字段组成源字段数组,a和b字段组成目标字段数组,调用该方法,将记录集的b和c的字段值逐行写到矢量数据集a和b字段下。
使用该方法有以下几点注意事项:
1.系统字段不能作为目标字段,可以作为源字段。
2.目标字段数组中的所有字段必须在目标数据集中存在,如果目标字段数组中指定了矢量数据集中不存在的字段,则追加失败。
3.源字段数组中指定了记录集中不存在的字段,追加失败。
4.目标矢量数据集中未被指定的字段,所追加记录值按默认值赋值。
目标字段和源字段的字段类型有以下注意:
1.当目标字段的字段类型为整型时,源字段的字段类型的整型字节数要小于或等于目标字段的整型字节数,即当目标字段的类型为Long型时,源字段的字段类型可以为int或Long;
2.当目标字段的字段类型为浮点型时,源字段的字段类型的精度必须小于或等于目标字段的类型精度,即当目标字段的类型为double型时,源字段的类型可以为float或double;
3.当目标字段的字段类型为字符或文本型时,源字段的字段的类型可以为二进制类型以外的所有类型;
4.当目标字段类型为日期型和二进制字段,源字段的字段类型要和其一致。
- 参数:
recordset- 源记录集对象。sourceFields- 源字段数组,对应的是源记录集中的字段。targetFields- 目标字段数组,对应的是矢量数据集中的字段。- 返回:
- 追加成功返回 true,否则返回 false。
- 示范代码:
- 以下代码示范如何向目标矢量数据集根据指定的记录集中的字段追加行。
public void appendDemo() { // 前提条件:已打开一个工作空间 workspace 对象,工作空间中存在一个数据源 datasource 对象,数据源中包含两个矢量数据集“Capital”和“Point”。 // 获取两个矢量数据集 DatasetVector tarDataset = (DatasetVector) datasource.getDatasets().get("Point"); DatasetVector srcDataset = (DatasetVector) datasource.getDatasets().get("Capital"); // 获取源记录集 Recordset srcRecordset = srcDataset.getRecordset(false,CursorType.STATIC); // 源字段数组,数组中的字段必须在源记录集中存在 String[] srcFieldsNames = new String[] {"NAME", "DESCRIPTION", "URBAN_POP"}; // 目标字段数组,数组中的字段必须在目标数据集中存在 String[] tagFieldsNames = new String[] {"CAPITAL", "COUNTRY", "CAP_POP"}; if (tarDataset.append(srcRecordset, srcFieldsNames, tagFieldsNames)) { System.out.println("追加成功"); } // 释放资源 srcRecordset.dispose(); srcDataset.close(); tarDataset.close(); }
-
deleteRecords
public boolean deleteRecords(int[] id)
删除数据集中指定 ID 的记录。- 参数:
id- ID 数组。- 返回:
- 删除成功返回 true,否则返回 false。
-
deleteRecords
public boolean deleteRecords(long[] id)
通过 ID 数组删除数据集中的记录。- 参数:
id- 待删除记录的 ID 数组。- 返回:
- 删除成功返回 true,否则返回 false。
-
isAvailableFieldName
public boolean isAvailableFieldName(String fieldName)
用于判断属性数据表中字段名是否合法。字段名称是由数字,字母和下划线来组成,但不能以数字和下划线开头。当用户新建字段时,不能以 sm 作为前缀,因为 sm 为前缀的字段都是 SuperMap 系统字段,smUserID 除外。另外,字段的名称长度不能超过30个字符,并且字段的名称不区分大小写。名称用于唯一标识该字段,所以字段不可重名。- 参数:
fieldName- 字段的名称。- 返回:
- 字段名合法返回 true,否则返回 false。
-
getAvailableFieldName
public String getAvailableFieldName(String name)
根据传入参数生成一个合法的字段名。- 参数:
name- 输入的字段名称。- 返回:
- 一个合法的字段名。
-
query
public Recordset query(String attributeFilter, CursorType cursorType)
利用查询条件查询数据。该方法默认查询空间数据与属性数据。对于 UDB 引擎,当用户传入字符串型时间字段并用此时间值构造查询条件时,需遵循以下规则:将时间值格式化到 ”to_data()” 字符串的括号中,例如,时间值 "2008-5-12 14:28:00",写为 "to_date(2008-5-12 14:28:00)",注意括号中时间值无需引号。
注意:
- Oracle和SQLserver中不支持查询条件是两个二进制字段类型相等的情况。
- 参数:
attributeFilter- 查询条件,相当于 SQL 语句中的 Where 子句。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读属性。详细信息请参见CursorType类型。- 返回:
- 查询得到的记录集。
- 示范代码:
- 以下代码示范了对于 UDBX 引擎如何根据字符串型时间字段构造查询条件。
public void queryTest(){ // 前提条件:已打开一个工作空间 workspace 对象,工作空间中存在一个数据源 datasource 对象,数据源中包含矢量数据集"Link"。 // 获取矢量数据集 DatasetVector vector = (DatasetVector) datasource.getDatasets().get("Link"); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); //构造一个时间对象 Date dateOld=new Date(110,0,10,11,12,13); //构造一个当前时间的对象 Date dateNow = new Date(); //格式化成字符串 String dtStrOld = format.format(dateOld); String dtStrNow = format.format(dateNow); //用两个时间字符串构造查询条件 String filter = "TimeField between '" + dtStrOld + "' and '" + dtStrNow + "'"; //将查询条件传入到Query方法,查询记录集 Recordset recordset = vector.query(filter,CursorType.STATIC); }
-
query
public Recordset query(Geometry geometry, double bufferDistance, CursorType cursorType)
用于查询数据集中落在指定空间对象的缓冲区内的记录。- 参数:
geometry- 用于查询的空间对象。bufferDistance- 缓冲区的半径。单位与被查询数据集的单位一致。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读属性。详细信息请参见CursorType类型。- 返回:
- 查询的记录集。
-
query
public Recordset query(Geometry geometry, double bufferDistance, String attributeFilter, CursorType cursorType)
用于查询数据集中落在指定空间对象的缓冲区内,并且满足一定条件的记录。注意:
- Oracle和SQLserver中不支持查询条件是两个二进制字段类型相等的情况。
- 参数:
geometry- 用于查询的空间对象。bufferDistance- 缓冲区的半径。单位与被查询数据集的单位一致。attributeFilter- 查询条件,通常是一个 SQL 语句。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读。详细信息请参见CursorType类型。- 返回:
- 查询的记录集。
-
query
public Recordset query(Rectangle2D bounds, CursorType cursorType)
用于查询落在已知空间范围内的记录。- 参数:
bounds- 已知的空间范围。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读。详细信息请参见CursorType类型。- 返回:
- 查询的记录集。
-
query
public Recordset query(Rectangle2D bounds, String attributeFilter, CursorType cursorType)
用于查询落在已知空间范围内,并且满足一定条件的记录。注意:
- Oracle和SQLserver中不支持查询条件是两个二进制字段类型相等的情况。
- 参数:
bounds- 已知的空间范围。attributeFilter- 查询过滤条件,相当于 SQL 语句中的 Where 子句部分。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读。详细信息请参见CursorType类型。- 返回:
- 查询的记录集。
-
query
public Recordset query(int[] id, CursorType cursorType)
根据 ID 进行查询。- 参数:
id- 指定的 ID 数组。注意:当引擎类型为ARCSDE_ORACLE时,ID 数量不允许超过200。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读。详细信息请参见CursorType类型。- 返回:
- 成功返回查询的记录集,失败返回空值。
-
query
public Recordset query(long[] id, CursorType cursorType)
根据指定字段做ID查询,指定字段类型必须是长整型。- 参数:
id- 指定的 ID 数组。注意:当引擎类型为ARCSDE_ORACLE时,ID 数量不允许超过200。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读属性。详细信息请参见CursorType类型。- 返回:
- 成功返回查询的记录集,失败返回空值。
-
query
public Recordset query(int[] id, String idFieldName, CursorType cursorType)
根据指定字段做ID查询,指定字段类型必须是整型。- 参数:
id- 指定 ID 数组。注意:当引擎类型为ARCSDE_ORACLE时,ID 数量不允许超过200。idFieldName- 定的字段名称。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读属性。详细信息请参见CursorType类型。- 返回:
- 成功返回查询的记录集,失败返回空值。
-
query
public Recordset query(long[] id, String idFieldName, CursorType cursorType)
根据指定字段做ID查询,指定字段类型必须是长整型。- 参数:
id- 指定 ID 数组。注意:当引擎类型为ARCSDE_ORACLE时,ID 数量不允许超过200。idFieldName- 定的字段名称。cursorType- 指定的游标类型,以便用户控制查询出来的记录集的属性。当游标类型为动态时,记录集可以被修改,当游标类型为静态时,记录集为只读属性。详细信息请参见CursorType类型。- 返回:
- 成功返回查询的记录集,失败返回空值。
-
query
public Recordset query(QueryParameter queryParameter)
通过设置查询条件对矢量数据集进行查询,该方法默认查询空间信息与属性信息。注意:
- 当搜索数据集/记录集(
QueryParameter.setSpatialQueryObject)中存在对象重叠的情况时,空间查询的结果可能不正确,建议采用遍历搜索数据集/记录集,逐个使用单对象查询的方式进行空间查询。 - 当被搜索CAD数据集/记录集中存在复合对象时,只支持相交和包含(包含只支持二维对象作为查询对象)查询。
- Oracle和SQLserver中不支持查询条件是两个二进制字段类型相等的情况。
- 当空间查询容限为0时,默认容限请查看
setDefault。 - 空间查询(
query)支持调用setGroupBy()方法设置分组条件字段,但需满足以下条件,其它情况下空间查询调用 QueryParameter.setGroupBy() 方法无效。
- 参数:
queryParameter- 定义的查询条件。- 返回:
- 查询的记录集。
- 另请参阅:
DatasetVector.statistic(String,StatisticMode)- 示范代码:
- 请参见
DatasetVector.statistic()方法的示例。
- 当搜索数据集/记录集(
-
buildFieldIndex
public boolean buildFieldIndex(String[] fieldName, String indexName)
为数据集的非空间字段创建索引。创建成功返回 true,否则返回 false。非空间字段名称,指除了系统字段之外需要建立索引的用户字段名。- 参数:
fieldName- 非空间字段名称。indexName- 索引名称。- 返回:
- 创建成功返回 true,否则返回 false。
-
getSpatialIndexType
public SpatialIndexType getSpatialIndexType()
返回当前的空间索引类型。- 返回:
- 当前的空间索引类型。
- 另请参阅:
DatasetVector.buildSpatialIndex(SpatialIndexType)- 示范代码:
- 请参见
DatasetVector.buildSpatialIndex()方法的示例。
-
isSpatialIndexDirty
public boolean isSpatialIndexDirty()
返回矢量数据集中空间索引是否需要重建。 在修改数据过程后,脏数据(通常为新增数据)超过一定数据量时,需要重建空间索引。注意:
- 对于空间数据库(PostGIS、OracleSpatial、UDBX等),使用该方法均返回 false,因为这些空间数据库会自动更新空间索引,不需要手动重建。
- 对于非空间数据库(PostgreSQL、Oracle、SQLServer等),使用该方法将根据脏数据的情况判断是否需要手动重建空间索引。
- 返回:
- 需要重建索引,返回 true;否则返回 false。
- 另请参阅:
DatasetVector.buildSpatialIndex(SpatialIndexType)- 示范代码:
- 请参见
DatasetVector.buildSpatialIndex()方法的示例。
-
isSpatialIndexTypeSupported
public boolean isSpatialIndexTypeSupported(SpatialIndexType spatialIndexType)
判断当前数据集是否支持指定的类型的空间索引。- 参数:
spatialIndexType- 指定的空间索引的类型。- 返回:
- 如果支持指定的空间索引类型,返回值为 true,否则为 false。
- 另请参阅:
DatasetVector.buildSpatialIndex(SpatialIndexType)- 示范代码:
- 请参见
DatasetVector.buildSpatialIndex()方法的示例。
-
buildSpatialIndex
public boolean buildSpatialIndex(SpatialIndexInfo spatialIndexInfo)
根据指定的空间索引信息为矢量数据集创建空间索引。注意:
- 数据库型数据源中的点数据集不支持四叉树(QTree)索引和R树索引(RTree);
- CAD数据集不支持动态索引(Dynamic);
- 路由数据集不支持图幅索引(TILE);
- 属性数据集、模型数据集不支持任何类型的空间索引;
- 对于数据库类型的数据源,数据库记录要大于1000条时才可以建空间索引。
- 参数:
spatialIndexInfo- 指定的空间索引信息对象。- 返回:
- 创建索引成功返回 true,否则返回 false。
- 抛出:
UnsupportedOperationException- 本操作需要在数据集关闭状态时进行,如当前数据集仍然打开。
-
buildSpatialIndex
public boolean buildSpatialIndex(SpatialIndexType spatialIndexType)
根据给定的空间索引类型来为矢量数据集创建空间索引。有关空间索引类型请参见SpatialIndexType枚举类型说明。注意:
- 数据库型数据源中的点数据集不支持四叉树(QTree)索引和R树索引(RTree);
- CAD数据集不支持动态索引(Dynamic);
- 路由数据集不支持图幅索引(TILE);
- 属性数据集、模型数据集不支持任何类型的空间索引;
- 对于数据库类型的数据源,数据库记录要大于1000条时才可以建空间索引。
本操作需要在数据集关闭状态时进行,如当前数据集仍然打开,则重建空间索引失败。
- 参数:
spatialIndexType- 指定的需要创建空间索引的类型。- 返回:
- 创建索引成功返回 true,否则返回 false。
- 示范代码:
- 以下代码示范判断某数据集的空间索引是否需要重建,如果需要重建,建立一个 R 树索引,如果不需重建,则判断现有数据集是否支持多级网格索引。
public void buildSpatialIndexTest() { // 前提条件:已打开一个工作空间 workspace 对象,工作空间中存在一个数据源 datasource 对象,数据源中包含矢量数据集"World"。 // 获取矢量数据集 DatasetVector datasetVector = (DatasetVector) datasource.getDatasets().get("World"); // 判断此数据集的空间索引是否需要重建,如果需要重建,建立一个 R 树索引,如果不需重建,则判断现有数据集是否支持多级网格索引 if (datasetVector.isSpatialIndexDirty()) { // 删除已存在的索引 datasetVector.dropSpatialIndex(); // 关闭数据集 datasetVector.close(); // 重建 R 树索引 if (datasetVector.buildSpatialIndex(SpatialIndexType.RTREE)) { SpatialIndexType spatialindextype = datasetVector.getSpatialIndexType(); System.out.println("新建空间索引的类型为:" + spatialindextype); } } else { // 如果不需要重建,判断现有数据集是否支持多级网格索引 if (datasetVector.isSpatialIndexTypeSupported(SpatialIndexType.MULTI_LEVEL_GRID)) { System.out.println("该数据集支持多级网格索引"); } else { System.out.println("该数据集不支持多级网格索引"); } } }
-
reBuildSpatialIndex
public boolean reBuildSpatialIndex()
在原有的空间索引的基础上进行重建,如果原来的空间索引被破坏,那么重建成功之后还可以继续使用。- 返回:
- 重建索引成功返回 true,否则返回 false。
-
statistic
public double statistic(String fieldName, StatisticMode mode)
通过字段名称指定字段,对指定的字段按照给定的方式进行统计。当前版本提供了6种统计方式。统计字段的最大值,最小值,平均值,总和,标准差,以及方差。
当前版本支持的统计字段类型为布尔,字节,双精度,单精度,16位整型,32位整型。
- 参数:
fieldName- 统计使用的字段或字段运算表达式,如 SmID/100 等。mode- 统计方式。- 返回:
- 统计结果。
- 示范代码:
- 以下代码示范如何对数据集中的字段进行统计操作及查询操作。
public void statisticTest() { // 前提条件:已打开一个工作空间 workspace 对象,工作空间中存在一个数据源 datasource 对象,数据源中包含矢量数据集"World",数据集中包含字段 Pop_1994,代表1994年的人口数目。 // 获取矢量数据集 DatasetVector datasetVector = (DatasetVector) datasource.getDatasets().get("World"); // 计算1994年人口的平均值,构建查询条件,即人口数大于一百万,查询条件遵循 SQL 语法 double average = datasetVector.statistic("Pop_1994",StatisticMode.AVERAGE); System.out.println("1994年人口的平均值为:" + average); QueryParameter queryParameter = new QueryParameter(); queryParameter.setAttributeFilter("Pop_1994 >"+average); queryParameter.setHasGeometry(true); // 根据查询条件执行查询操作,返回查询结果记录集 Recordset queryRecordset = datasetVector.query(queryParameter); // 释放资源 queryRecordset.dispose(); datasetVector.close(); }
-
statistic
public double statistic(int fieldIndex, StatisticMode mode)对指定的字段按照给定的方式进行统计。当前版本提供了6种统计方式。统计字段的最大值,最小值,平均值,总和,标准差,以及方差。
当前版本支持的统计字段类型为布尔,字节,双精度,单精度,16位整型,32位整型。
- 参数:
fieldIndex- 要统计的字段索引值。mode- 统计方式。- 返回:
- 统计结果。
-
updateField
public boolean updateField(String fieldName, Object value, String attributeFilter)
根据指定的需要更新的字段名称,用指定的用于更新的字段值更新符合 attributeFilter 条件的所有记录的字段值。需要更新的字段不能够为系统字段,也就是说待更新字段不可以为 sm 开头的字段(smUserID 除外)。- 参数:
fieldName- 需要更新的字段名。value- 指定用于更新的字段值。attributeFilter- 要更新记录的查询条件,如果 attributeFilter 为空字符串,则更新表中所有的记录。- 返回:
- 更新字段成功返回 true,否则返回 false。
-
updateField
public boolean updateField(int fieldIndex, Object value, String attributeFilter)根据指定的需要更新的字段序号,用指定的用于更新的字段值更新符合 attributeFilter 条件的所有记录的字段值。需要更新的字段不能够为系统字段,也就是说待更新字段不可以为 sm 开头的字段(smUserID 除外)。- 参数:
fieldIndex- 需要更新的字段序号。value- 指定用于更新的字段值。attributeFilter- 要更新记录的查询条件,如果 attributeFilter 为空字符串,则更新表中所有的记录。- 返回:
- 更新字段成功返回 true,否则返回 false。
-
updateField
public boolean updateField(String fieldName, String expression, String attributeFilter)
根据指定的需要更新的字段名,用指定的表达式计算结果更新符合查询条件的所有记录的字段值。需要更新的字段不能够为系统字段,也就是说不可以为 sm 开头的字段(smUserID 除外)。- 参数:
fieldName- 需要更新的字段名。expression- 指定的表达式,表达式可以是字段的运算或函数的运算。例如:"SMID" 、"abs(SMID)"、"SMID+1"、 " '字符串'"。attributeFilter- 要更新记录的查询条件,如果 attributeFilter 为空字符串,则更新表中所有的记录。- 返回:
- 更新字段成功返回 true,否则返回 false。
- 示范代码:
- 以下代码示范如何对数据集中的字段进行更新操作。
public void updateFieldTest() { // 前提条件:已打开一个工作空间 workspace 对象,工作空间中存在一个数据源 datasource 对象,数据源中包含矢量数据集"World",数据集中包含字段 Pop_1994,代表1994年的人口数目。 // 获取矢量数据集 DatasetVector datasetVector = (DatasetVector) datasource.getDatasets().get("World"); // 将字段 Pop_1994 中大于一百万的数值统一更新为“1000000” datasetVector.updateField("Pop_1994", "1000000", "Pop_1994 >= 1000000"); // 关闭数据集 datasetVector.close(); }
-
updateField
public boolean updateField(int fieldIndex, String expression, String attributeFilter)根据指定的需要更新的字段序号,用指定的表达式计算结果更新符合查询条件的所有记录的字段值。需要更新的字段不能够为系统字段,也就是说不可以为 sm 开头的字段(smUserID 除外)。- 参数:
fieldIndex- 需要更新的字段序号。expression- 指定的表达式。attributeFilter- 要更新记录的查询条件,如果 attributeFilter 为空字符串,则更新表中所有的记录。- 返回:
- 更新字段成功返回 true,否则返回 false。
-
updateField
public boolean updateField(String fieldName, String expression, String attributeFilter, JoinItems joinItems)
根据指定的需要更新的字段序号,用指定的表达式计算结果更新符合查询条件的所有记录的字段值,需要更新的字段不能够为系统字段(SmUserID除外)。- 参数:
fieldName- 需要更新的字段名字。expression- 指定的表达式,表达式遵守sql语句中值的规则。(1)数值型:直接传入数值,比如1、2.1等。
(2)日期型:不同引擎格式不同,udb/udbx引擎to_date("2022/02/05 10:10:05"),postgres/pgis/yukon引擎使用时区写法'2022-02-05 10:10:05+8', oracle/oraclespatial引擎 to_date('2022-01-10 10:10:20','yyyy-mm-dd hh24:mi:ss'),mysql引擎 '2022-02-05 10:10:05', DM引擎to_date('2022-01-10 10:10:20','yyyy-mm-dd hh24:mi:ss')。
(3)字符串类型:加上单引号和要更新的值,传入‘a’,表示字段值更新为a。如果值含有单引号,则使用两个单引号''进行转义。
(4)其他字段的组合,比如字段a和字段b的和,则传入a+b。
(5)表达式支持使用数据库函数,但是不支持聚合函数,比如PostgreSQL函数删除左侧空格函数ltrim(' abc')。注:不同数据库支持数据库函数情况不同,使用时参考当前数据库是否该函数
attributeFilter- 要更新记录的查询条件,sql语句中的where子句,如果 attibuteFilter为空字符串,则更新表中所有的记录。joinItems- 关联更新相关信息,详见JoinItems,设置joinItems。- 返回:
- 更新字段成功返回true,否则返回 false。
-
updateField
public boolean updateField(int fieldIndex, String expression, String attributeFilter, JoinItems joinItems)根据指定的需要更新的字段序号,用指定的表达式计算结果更新符合查询条件的所有记录的字段值,需要更新的字段不能够为系统字段(SmUserID除外)。- 参数:
fieldIndex- 需要更新的字段序号。expression- 指定的表达式,表达式遵守sql语句中值的规则。(1)数值型:直接传入数值,比如1、2.1等。
(2)日期型:不同引擎格式不同,udb/udbx引擎to_date("2022/02/05 10:10:05"),postgres/pgis/yukon引擎使用时区写法'2022-02-05 10:10:05+8', oracle/oraclespatial引擎 to_date('2022-01-10 10:10:20','yyyy-mm-dd hh24:mi:ss'),mysql引擎 '2022-02-05 10:10:05', DM引擎to_date('2022-01-10 10:10:20','yyyy-mm-dd hh24:mi:ss')。
(3)字符串类型:加上单引号和要更新的值,传入‘a’,表示字段值更新为a。如果值含有单引号,则使用两个单引号''进行转义。
(4)其他字段的组合,比如字段a和字段b的和,则传入a+b。
(5)表达式支持使用数据库函数,但是不支持聚合函数,比如PostgreSQL函数删除左侧空格函数ltrim(' abc')。注:不同数据库支持数据库函数情况不同,使用时参考当前数据库是否该函数。
attributeFilter- 要更新记录的查询条件,sql语句中的where子句,如果 attibuteFilter为空字符串,则更新表中所有的记录。joinItems- 关联更新相关信息,详见JoinItems,设置joinItems。- 返回:
- 更新字段成功返回true,否则返回 false。
-
computeBounds
public Rectangle2D computeBounds()
重新计算数据集的空间范围。- 返回:
- 数据集的空间范围。
-
dropFieldIndex
public boolean dropFieldIndex(String indexName)
根据索引名指定字段,删除该字段的索引。- 参数:
indexName- 索引名。- 返回:
- 删除成功返回true,否则返回false。
-
dropSpatialIndex
public boolean dropSpatialIndex()
删除空间索引。- 返回:
- 删除成功返回 true,否则返回 false。
- 另请参阅:
DatasetVector.buildSpatialIndex(SpatialIndexType)- 示范代码:
- 请参见
DatasetVector.buildSpatialIndex()方法的示例。
-
getAllFeatures
public Map<Integer,Feature> getAllFeatures()
返回矢量数据集中的所有特征要素集。Map 的第一个参数代表几何对象的 ID 号(即 SmID 字段的值),第二个参数是特征要素(
Feature})的引用。- 返回:
- 所有的特征要素集。
- 示范代码:
- 请参见
Recordset.getAllFeatures()方法的示例。
-
updateFields
@Deprecated public boolean updateFields(DatasetVector sourceDataset, SpatialRelationType spatialRelationType, String[] sourceFields, String[] targetFields, AttributeStatisticsType attributeStatisticsType, boolean isBorderInside, String errorName, boolean isShowProgress)
已过时。 使用updateFields(AttributeUpdateInfo info)DatasetVector.updateFields(AttributeUpdateInfo, boolean))} 方法替代。根据空间关系更新数据集中对象的属性。注意:
- 提供属性的数据集中用于更新的字段集合(对应方法中的 sourceFields 参数)中的字段必须与被更新的字段集合(对应方法中的 targetFields 参数)中的字段一一对应,若两个字段集合中的个数不匹配,则更新失败,方法返回 false;如果字段类型不匹配,方法将执行强制转换,若转换失败,则放弃对该字段的更新。
- 如果属性字段取值方式(对应方法中的 attributeStatisticsType 参数)为 VALUE、MINID 和 MAXID,不支持 Text、WText 和 DateTime 三种字段类型。
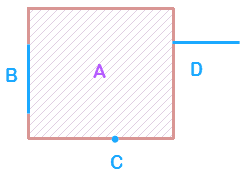
- 对于边界处理方式(对应方法中 isBorderInside 参数)的理解,如下图所示,点 C 位于面 A 的边线上,线 D 与面 A 只相交于其一个端点,如果 isBorderInside 为 true,则认为点 C 与 面 A、线 D 与面 A 为相交关系,此时若指定的空间关系为相交,那么点 C 和 线 D 的属性将被面 A 更新。需要强调的是,线 B 与 面 A 并非只相交于线的端点,因此,当空间关系为相交时,无论 isBorderInside 为 true 还是 false,线 B 的属性都将被 面 A 更新。
- 参数:
sourceDataset- 指定的提供属性的数据集。spatialRelationType- 指定的空间关系。sourceFields- 指定的提供属性的数据集中用于更新的字段集合。targetFields- 指定的被更新的字段集合。attributeStatisticsType- 指定的属性字段的取值方式。isBorderInside- 指定边界处理方式,即位于面边线上的点是否被面包含,或线只有端点与面相交时是否与面相交。errorName- 指定的记录满足空间关系的提供属性的数据集中对象个数的字段。该字段必须为整型。isShowProgress- 指定是否显示进度条。- 返回:
- 一个布尔值,表示是否更新属性成功,如果成功返回 true,否则返回 false。
-
updateFields
@Deprecated public boolean updateFields(Recordset sourceRecordset, SpatialRelationType spatialRelationType, String[] sourceFields, String[] targetFields, AttributeStatisticsType attributeStatisticsType, boolean isBorderInside, String errorName, boolean isShowProgress)
已过时。 使用updateFields(AttributeUpdateInfo info)DatasetVector.updateFields(AttributeUpdateInfo, boolean))} 方法替代。根据空间关系更新数据集中对象的属性。有关以下三个注意点请参见另一重载方法
DatasetVector.updateFields的介绍。- 用于更新的字段集合与被更新字段集合需要对应。
- 取值方式对字段类型的限制。
- 边界处理方式(对应方法中 isBorderInside 参数)的介绍。
- 参数:
sourceRecordset- 指定的提供属性的记录集。spatialRelationType- 指定的空间关系。sourceFields- 指定的提供属性的记录集中用于更新的字段集合。targetFields- 指定的被更新的字段集合。attributeStatisticsType- 指定的属性字段的取值方式。isBorderInside- 指定边界处理方式,即位于面边线上的点是否被面包含,或线只有端点与面相交时是否与面相交。errorName- 指定的记录满足空间关系的提供属性的记录集中对象个数的字段。该字段必须为整型。isShowProgress- 指定是否显示进度条。- 返回:
- 一个布尔值,表示是否更新属性成功,如果成功返回 true,否则返回 false。
-
updateFields
public boolean updateFields(AttributeUpdateInfo info, boolean isShowProgress)
-
getIDsByGeoRelation
public int[] getIDsByGeoRelation(DatasetVector sourceDataset, SpatialRelationType spatialRelationType, boolean isBorderInside, boolean isShowProgress)
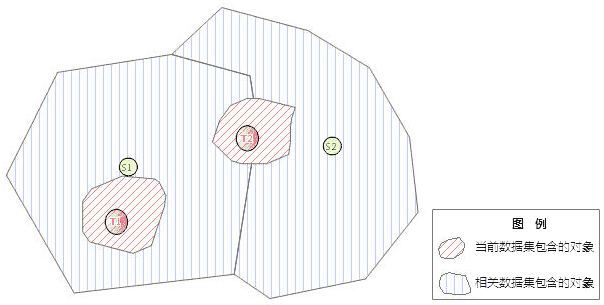
从另一数据集中获取与当前数据集的对象满足一定空间关系的对象的 ID。关于该方法返回的整型数组各元素的含义,请结合下图来理解。
在下图中,有两个数据集,当前数据集 T 和相关数据集 S,数据集 T 包含 T1 和 T2 两个对象,数据集 S 包含 S1 和 S2 两个对象,调用 getIDsByGeoRelation 方法来获取数据集 S 中与数据集 T 中的对象满足相关关系的对象的 ID,其返回值为[IDT1,1,IDS1,IDT2,2,IDS1,IDS2]。
故该方法返回的数组其结构可归纳为:[当前数据集中第一个对象的 SMID,相关数据集中与之满足空间关系的对象个数,相关数据集中与之满足空间关系的第一个对象的 SMID,第二个,...,当前数据集中第二个对象的 SMID,...,依此类推]。
注意,假设数据集 T 中的第 n 个对象,在数据集 S 中没有与之满足空间关系的对象,则数组中只记录该对象的 ID 和满足空间关系的对象数(即 0),即[...,IDTn,0,IDT(n+1),...]。
- 参数:
sourceDataset- 指定的与当前数据集相关的数据集。spatialRelationType- 指定的空间关系。isBorderInside- 指定边界处理方式,即位于面边线上的点是否被面包含,或线只有端点与面相交时是否与面相交。isShowProgress- 指定是否显示进度条。- 返回:
- 一个整型数组,数组元素的含义见方法的介绍。
-
getIDsByGeoRelation
public int[] getIDsByGeoRelation(Recordset sourceRecordset, SpatialRelationType spatialRelationType, boolean isBorderInside, boolean isShowProgress)
从另一记录集中获取与当前数据集的对象满足一定空间关系的对象的 ID。该方法返回的数组其结构可归纳为:[当前数据集中第一个对象的 SMID,相关记录集中与之满足空间关系的对象个数,相关记录集中与之满足空间关系的第一个对象的 SMID,第二个,...,当前数据集中第二个对象的 SMID,...,依此类推]。
更多介绍,请参阅另一重载方法
DatasetVector.getIDsByGeoRelation。- 参数:
sourceRecordset- 指定的与当前数据集相关的记录集。spatialRelationType- 指定的空间关系。isBorderInside- 指定边界处理方式,即位于面边线上的点是否被面包含,或线只有端点与面相交时是否与面相交。isShowProgress- 指定是否显示进度条。- 返回:
- 一个整型数组,数组元素的含义见方法的介绍。
-
getIDsByGeoRelation
public int[] getIDsByGeoRelation(Geometry[] sourceGeometries, SpatialRelationType spatialRelationType, boolean isBorderInside, boolean isShowProgress)
从给定的几何对象集合中获取与当前数据集的对象满足一定空间关系的对象的 ID。该方法返回的数组其结构可归纳为:[当前数据集中第一个对象的 SMID,相关几何对象数组中满足空间关系的对象个数,相关几何对象数组中满足空间关系的第一个对象的 ID,第二个,...,当前数据集中第二个对象的 SMID,...,依此类推]。
需要注意,相关几何对象数组中的对象必须具有不重复的 ID,该 ID 可通过
Geometry的getID方法返回,以及通过setID方法设置。如果相关的几何对象数组中的对象来自于记录集,并且没有手动修改对象的 ID,那么返回的是对象的 SMID。如果对象没有明确的来源,或者 ID 有重复,必须为它们重新设置不同的 ID。更多介绍,请参阅另一重载方法
DatasetVector.getIDsByGeoRelation。- 参数:
sourceGeometries- 指定的与当前数据集相关的几何对象数组。spatialRelationType- 指定的空间关系。isBorderInside- 指定边界处理方式,即位于面边线上的点是否被面包含,或线只有端点与面相交时是否与面相交。isShowProgress- 指定是否显示进度条。设置为 true,则显示进度条,否则不显示。- 返回:
- 一个整型数组,数组元素的含义见方法的介绍。
- 从以下版本开始:
- SuperMap iObjects Java 7.0.0
-
resample
public boolean resample(ResampleInformation resampleInfo, boolean isShowProgress, boolean isSaveSmallGeometry)
对矢量数据集进行重采样,支持线数据集、面数据集和网络数据集。矢量数据重采样是按照一定规则剔除一些节点,以达到对数据进行简化的目的(如下图所示),其结果可能由于使用不同的重采样方法而不同。SuperMap 提供了两种重采样方法,请参见枚举类型
ResampleType的介绍。
该方法可以对线数据集、面数据集和网络数据集进行重采样。对面数据集重采样时,实质是对面对象的边界进行重采样。对于多个面对象的公共边界,如果进行了拓扑预处理(可通过
setTopologyPreprocess方法来设置)只对其中一个多边形的该公共边界重采样一次,其他多边形的该公共边界会依据该多边形重采样的结果进行调整使之贴合,因此不会出现缝隙。注意:重采样容限过大时,可能影响数据正确性,如出现两多边形的公共边界处出现相交的情况。
- 参数:
resampleInfo- 指定的重采样信息设置。isShowProgress- 指定是否显示进度条。true 表示显示进度条,false 表示不显示。isSaveSmallGeometry- 指定是否保留小对象。小对象是指面积为0的对象,重采样过程有可能产生小对象。true 表示保留小对象,false 表示不保留。- 返回:
- 一个布尔值,表示是否重采样成功,如果成功返回 true,否则返回 false。
-
resample
public boolean resample(ResampleInformation resampleInfo, boolean isShowProgress, boolean isSaveSmallGeometry, SteppedListener... listenrs)
对矢量数据集进行重采样,支持线数据集、面数据集和网络数据集。矢量数据重采样是按照一定规则剔除一些节点,以达到对数据进行简化的目的(如下图所示),其结果可能由于使用不同的重采样方法而不同。SuperMap 提供了两种重采样方法,请参见枚举类型
ResampleType的介绍。该方法可以对线数据集、面数据集和网络数据集进行重采样。对面数据集重采样时,实质是对面对象的边界进行重采样。对于多个面对象的公共边界,如果进行了拓扑预处理(可通过
setTopologyPreprocess方法来设置)只对其中一个多边形的该公共边界重采样一次,其他多边形的该公共边界会依据该多边形重采样的结果进行调整使之贴合,因此不会出现缝隙。注意:重采样容限过大时,可能影响数据正确性,如出现两多边形的公共边界处出现相交的情况。
- 参数:
resampleInfo- 指定的重采样信息设置。isShowProgress- 指定是否显示进度条。true 表示显示进度条,false 表示不显示。isSaveSmallGeometry- 指定是否保留小对象。小对象是指面积为0的对象,重采样过程有可能产生小对象。true 表示保留小对象,false 表示不保留。- 返回:
- 一个布尔值,表示是否重采样成功,如果成功返回 true,否则返回 false。
-
smooth
public boolean smooth(int smoothness, boolean isShowProgress)对矢量数据集进行平滑,支持线数据集、面数据集和网络数据集。- 平滑的目的
- 平滑方法与平滑系数的设置
当折线或多边形的边界的线段过多时,就可能影响对原始特征的描述,不利用进一步的处理或分析,或显示和打印效果不够理想,因此需要对数据简化。简化的方法一般有重采样(
resample)和平滑。平滑是通过增加节点的方式使用曲线或直线段来代替原始折线的方法。需要注意,对折线进行平滑后,其长度通常会变短,折线上线段的方向也会发生明显改变,但两个端点的相对位置不会变化;面对象经过平滑后,其面积通常会变小。
该方法采用 B 样条法对矢量数据集进行平滑。有关 B 样条法的介绍可参见
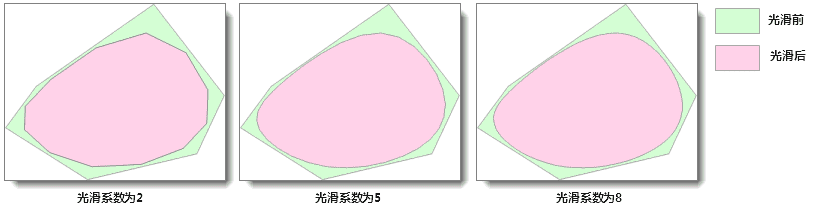
SmoothMethod类。平滑系数(方法中对应 smoothness 参数)影响着平滑的程度,平滑系数越大,结果数据越平滑。平滑系数的建议取值范围为[2,10]。该方法支持对线数据集、面数据集和网络数据集进行平滑。下面两幅图为平滑系数分别为2、5和8时对线和面平滑的效果。对线数据集设置不同平滑系数的平滑效果:

对面数据集设置不同平滑系数的平滑效果:
注意:该方法只支持对线数据集、面数据集和网络数据集进行平滑,设置为其他类型的矢量数据集会抛出异常。
- 参数:
smoothness- 指定的平滑系数。取大于等于 2 的值有效,该值越大,线对象或面对象边界的节点数越多,也就越平滑。建议取值范围为[2,10]。isShowProgress- 指定是否显示进度条。true 表示显示进度条,false 表示不显示。- 返回:
- 平滑成功返回 true,否则返回 false。
-
smooth
public boolean smooth(int smoothness, boolean isSaveTopology, boolean isShowProgress)对矢量数据集进行平滑,支持线数据集、面数据集和网络数据集。- 平滑的目的
- 平滑方法与平滑系数的设置
当折线或多边形的边界的线段过多时,就可能影响对原始特征的描述,不利用进一步的处理或分析,或显示和打印效果不够理想,因此需要对数据简化。简化的方法一般有重采样(
resample)和平滑。平滑是通过增加节点的方式使用曲线或直线段来代替原始折线的方法。需要注意,对折线进行平滑后,其长度通常会变短,折线上线段的方向也会发生明显改变,但两个端点的相对位置不会变化;面对象经过平滑后,其面积通常会变小。
该方法采用 B 样条法对矢量数据集进行平滑。有关 B 样条法的介绍可参见
SmoothMethod类。平滑系数(方法中对应 smoothness 参数)影响着平滑的程度,平滑系数越大,结果数据越平滑。平滑系数的建议取值范围为[2,10]。该方法支持对线数据集、面数据集和网络数据集进行平滑。下面两幅图为平滑系数分别为2、5和8时对线和面平滑的效果。对线数据集设置不同平滑系数的平滑效果:
对面数据集设置不同平滑系数的平滑效果:
注意:该方法只支持对线数据集、面数据集和网络数据集进行平滑,设置为其他类型的矢量数据集会抛出异常。
- 参数:
smoothness- 指定的平滑系数。取大于等于 2 的值有效,该值越大,线对象或面对象边界的节点数越多,也就越平滑。建议取值范围为[2,10]。isSaveTopology- 是否保存拓扑关系。true 表示保存拓扑关系,false 表示不保存。isShowProgress- 指定是否显示进度条。true 表示显示进度条,false 表示不显示。- 返回:
- 一个布尔值,表示是否平滑成功,如果成功返回 true,否则返回 false。
-
appendFields
public boolean appendFields(DatasetVector sourceDataset, String sourceLinkFieldName, String targetLinkFieldName, String[] sourceFields, String[] targetFields)
从源数据集向目标数据集追加字段,并根据关联字段查询结果对字段进行赋值。- 参数:
sourceDataset- 源数据集。sourceLinkFieldName- 源数据集中的与目标数据集的关联字段。targetLinkFieldName- 目标数据集中的与源数据集的关联字段。sourceFields- 源数据集中被追加到目标数据集的字段名集合。targetFields- 追加字段在目标数据集中相对应的字段名集合。- 返回:
- 一个布尔值,表示追加字段是否成功,成功返回 true,否则返回 false。
注意
- 如果指定的源数据集中被追加到目标数据集的字段名集合的某字段在源数据集中不存在,则忽略此字段,只追加源数据集中存在的字段;
- 如果指定了追加字段在目标数据集中相对应的字段名集合,则按所指定的字段名在目标数据集中创建所追加的字段;当指定的字段名在目标数据集中已存在时,则自动加_x(1、2、3...)进行字段的创建;
- 如果在目标数据集中创建字段失败,则忽略此字段,继续追加其它字段;
- 必须指定源字段名集合,否则追加不成功;
- 使用重载接口
appendFields(DatasetVector, String, String, String[], Boolean),可以不必指定目标字段名集合; - 一旦指定目标字段名集合,则此集合中字段名必须与源字段名集合中的字段名一一对应。
- 示范代码:
- 请参见
appendFields(DatasetVector, String, String, String[], Boolean)方法的示例。
-
appendFields
public boolean appendFields(DatasetVector sourceDataset, String sourceLinkFieldName, String targetLinkFieldName, String[] sourceFields)
从源数据集向目标数据集追加字段,并根据关联字段查询结果对字段进行赋值。- 参数:
sourceDataset- 源数据集。sourceLinkFieldName- 源数据集中的与目标数据集的关联字段。targetLinkFieldName- 目标数据集中的与源数据集的关联字段。sourceFields- 源数据集中被追加到目标数据集的字段名集合。。- 返回:
- 一个布尔值,表示追加字段是否成功,成功返回 true,否则返回 false。
注意
- 如果指定的源数据集中被追加到目标数据集的字段名集合的某字段在源数据集中不存在,则忽略此字段,只追加源数据集中存在的字段;
- 如果指定了追加字段在目标数据集中相对应的字段名集合,则按所指定的字段名在目标数据集中创建所追加的字段;当指定的字段名在目标数据集中已存在时,则自动加_x(1、2、3...)进行字段的创建;
- 如果在目标数据集中创建字段失败,则忽略此字段,继续追加其它字段;
- 必须指定源字段名集合,否则追加不成功;
- 使用重载接口
appendFields(DatasetVector, String, String, String[]),可以不必指定目标字段名集合; - 一旦指定目标字段名集合,则此集合中字段名必须与源字段名集合中的字段名一一对应。
- 示范代码:
- 以下代码示范如何向目标数据集追加字段,并根据关联字段查询结果对字段进行赋值。
public void appendFieldsTest() { // 前提条件:已打开一个工作空间 workspace 对象,工作空间中存在一个数据源 datasource 对象,数据源中包含矢量数据集"World"和“Capital”。 // 获取矢量数据集 DatasetVector dataset_world = (DatasetVector) datasource.getDatasets().get("World"); DatasetVector dataset = (DatasetVector) datasource.getDatasets().get("Capital"); // 定义关联字段 String targetLinkFieldName = "Capital"; String sourceLinkFieldName = "Capital"; // 定义源数据集中被追加到目标数据集的字段名集合 String[] sourceFields = new String[] { "SMID", "SMAREA", "SMPERIMETER", "Country"}; //向目标数据集追加字段 dataset.appendFields(dataset_world, sourceLinkFieldName, targetLinkFieldName, sourceFields); }
-
getFieldIndexes
public Map<String,String> getFieldIndexes()
返回当前数据集属性表建的索引与建索引的字段的关系映射对象。- 返回:
- 当前数据集属性表建的索引与建索引的字段的关系映射对象,其中键值为索引值,映射值为索引所在字段。
-
truncate
public boolean truncate()
清除矢量数据集中的所有记录。- 返回:
- 清除记录是否成功,成功返回 true,失败返回 false。
-
getFieldNameBySign
public String getFieldNameBySign(FieldSign value)
根据字段标识获取字段名。- 参数:
value- 字段标识。- 返回:
- 字段名。
-
getChildDatasets
public DatasetVector[] getChildDatasets()
获取图幅索引的子数据集。- 返回:
- 图幅索引的子数据集数组。
-
DeleteDatasetFromCollection
public Boolean DeleteDatasetFromCollection(DatasourceConnectionInfo info, String datasetName)
删除数据集合子数据集。- 参数:
info-datasetName-- 返回:
-
addCollectionDataset
public Boolean addCollectionDataset(DatasetVector dtv)
数据集集合添加一个子数据集。- 参数:
dtv- 子矢量数据集。- 返回:
- 添加成功返回true,失败返回false。
-
getCollectionDatasetCount
public int getCollectionDatasetCount()
获取数据集集合中子数据集的个数。- 返回:
- 子数据集的个数。
-
getCollectionDatasetInfos
public ArrayList<CollectionDatasetInfo> getCollectionDatasetInfos()
获取数据集集合中所有子数据集的信息。- 返回:
- 子数据集信息链表。
-
GetSubCollectionDatasetType
public DatasetType GetSubCollectionDatasetType()
获取数据集集合中子数据集的数据集类型。- 返回:
- 子数据集的数据集类型。
-
getMaxZ
public double getMaxZ()
获取模型数据集最大值。- 返回:
-
getMinZ
public double getMinZ()
获取模型数据集最小值。- 返回:
-
computeAreaLength
public boolean computeAreaLength()
紧缩面积长度是否成功- 返回:
-
addRelationDataset
public boolean addRelationDataset(RelationDatasetInfo rdInfo)
增加实体数据集的关系数据集- 参数:
rdInfo-- 返回:
-
deleteRelationDataset
public boolean deleteRelationDataset(RelationDatasetInfo rdInfo)
删除实体数据集的关系数据集- 参数:
rdInfo-- 返回:
-
getRelationDatasets
public ArrayList<RelationDatasetInfo> getRelationDatasets()
获取实体数据集的关系数据集- 返回:
-
createGridCodeFiled
public boolean createGridCodeFiled()
创建空间网格编码文件,用于存储数据库中空间对象的网格编码信息。- 返回:
- 成功创建网格编码则返回 true, 否则返回 false。
-
isCreateGridCodeFiled
public boolean isCreateGridCodeFiled()
返回是否已创建空间网格编码。- 返回:
- 已创建空间网格编码返回 true;否则返回 false。
-
dropGridCodeFiled
public boolean dropGridCodeFiled()
返回空间网格编码文件。- 返回:
- 删除成功返回 true,否则返回 false。
-
getDatasetIDType
public DatasetIDType getDatasetIDType()
获取数据集 ID 标识符类型。- 返回:
- 成功返回标识符类型,失败返回空值。
-
registerVersion
public boolean registerVersion()
对数据集注册版本,数据集需注册版本,才能进入版本管理工作流程。- 返回:
- 注册成功返回 true,否则返回 false。
-
unRegisterVersion
public boolean unRegisterVersion()
对数据集取消注册版本,数据集取消注册版本后,将退出版本管理工作流程。- 返回:
- 注册成功返回 true,否则返回 false。
-
buildVectorPyramid
public boolean buildVectorPyramid(int[] levels, double[] tolerances, boolean[] preserveCollapseds, String[] filters, String geometryName, String[] fieldnames)创建矢量金字塔。- 参数:
levels- 金字塔层级数组,可设置多个层级tolerances- 分辨率,用户可设置金字塔分辨率,默认为金字塔层级对应的分辨率preserveCollapseds- 是否保留最小对象,保留设置为true,不保留设置为falsefilters- 过滤条件geometryName- 用于创建矢量金字塔的几何字段名称fieldnames- 矢量金字塔中保留的属性字段名称- 返回:
- 创建成功返回 true,否则返回 false。
-
dropVectorPyramid
public boolean dropVectorPyramid(String geometryName)
删除指定几何字段创建的矢量金字塔。- 参数:
geometryName-- 返回:
- 删除成功返回 true,否则返回 false。
-
dropVectorPyramid
public boolean dropVectorPyramid()
删除矢量金字塔。- 返回:
- 删除成功返回 true,否则返回 false。
-
hasPyramid
public boolean hasPyramid(String geometryName)
判断指定几何字段是否创建了矢量金字塔。- 返回:
- 存在矢量金字塔返回 true,不存在返回 false。
-
hasPyramid
public boolean hasPyramid()
判断是否存在矢量金字塔。- 返回:
- 存在矢量金字塔返回 true,不存在返回 false。
-
getVectorPyramidConfigInfo
public VectorPyramidConfigInfo getVectorPyramidConfigInfo()
获取创建矢量金字塔的配置参数信息。- 返回:
- 矢量金字塔的配置参数信息。
-
copyFieldsToPyramid
public boolean copyFieldsToPyramid(String[] fields)
复制字段到矢量金字塔。- 参数:
fields- 字段信息- 返回:
- 复制成功返回 true,否则返回 false。
-
isSQLQuery
public boolean isSQLQuery()
判断数据集是否为用户通过过滤条件生成的临时数据集。- 返回:
- 是临时数据集返回 true,不是返回 false。
-
setIDFieldName
public void setIDFieldName(String strUserID)
对用户查询结果保存的数据集设置唯一ID字段,仅用于 Yukon 和 PostGIS 空间数据引擎。- 参数:
strUserID- 自定义唯一ID的字段名。
-
setGeoFieldName
public void setGeoFieldName(String strGeoName)
用户查询结果保存的数据集,如果存在多个geometry类型字段,可设置其中一个geometry类型字段,作为对象的空间几何进行地图展示,仅用于 Yukon 和 PostGIS 空间数据引擎。- 参数:
strGeoName- geometry类型字段名 。
-
getIDFieldName
public String getIDFieldName()
获取数据集的唯一ID字段名。- 返回:
- 数据集的唯一ID字段名。
-
getGeoFieldNames
public String[] getGeoFieldNames()
获取数据集中用于存储对象几何信息的字段名称。- 返回:
- 数据集用于存储对象几何信息的字段名数组。
-
isAssociatedWithRelationship
public boolean isAssociatedWithRelationship()
判断数据集是否被加入了关系数据集。- 返回:
- 数据集已加入关系数据集返回 true,否则返回 false。
- 从以下版本开始:
- 12.0.0
-
getRelationshipSetting
public RelationshipSetting getRelationshipSetting()
获取关系数据集的配置信息。- 返回:
- 关系数据集的配置信息。
- 从以下版本开始:
- 12.0.0
-
getAssociatedRelationshipNames
public String[] getAssociatedRelationshipNames()
获取当前数据集参与的关系数据集名称。- 返回:
- 当前数据集参与的关系数据集名称数组
- 从以下版本开始:
- 12.0.0
-
getSubtypesFieldName
public String getSubtypesFieldName()
获取子类的关联字段名称。- 返回:
- 子类的关联字段名称。
-
setSubtypesFieldName
public boolean setSubtypesFieldName(String fieldname)
设置子类的关联字段名称。- 参数:
fieldname- 子类的关联字段名称。- 返回:
- 设置成功返回 true,否则返回 false。
-
setSubtypes
public boolean setSubtypes(Subtypes subtypes)
设置子类。- 参数:
subtypes- 子类对象。- 返回:
- 设置成功返回 true,否则返回 false。
- 另请参阅:
Subtypes
-
setRelationshipRules
public boolean setRelationshipRules(RelationshipRules relationshipRules)
设置关系数据集的规则。- 参数:
relationshipRules- 关系数据集规则- 返回:
- 设置成功返回 true,否则返回 false。
- 抛出:
IllegalStateException- 不支持的数据集类型。- 从以下版本开始:
- 12.0.0
- 另请参阅:
RelationshipRules
-
getRelationshipRules
public RelationshipRules getRelationshipRules()
获取关系数据集的规则。- 返回:
- 关系数据集规则管理器对象。
- 抛出:
IllegalStateException- 不支持的数据集类型。- 从以下版本开始:
- 12.0.0
- 另请参阅:
RelationshipRules
-
setRenameDuplicateMaterials
public void setRenameDuplicateMaterials(boolean rename)
设置是否重命名重复材质。例如,在进行数据集追加时,可设置是否对重复材质重命名。- 参数:
rename- 是否重命名重复材质。- 抛出:
IllegalStateException- 当前对象已被释放。- 从以下版本开始:
- 11.2.0。
-
getRenameDuplicateMaterials
public boolean getRenameDuplicateMaterials()
返回是否重命名重复材质。- 返回:
- 是否重命名重复材质。返回true,重命名重复材质;返回false,不重命名重复材质。
- 抛出:
IllegalStateException- 当前对象已被释放。- 从以下版本开始:
- 11.2.0。
-
registerAttachment
public boolean registerAttachment()
将数据集注册为附件数据集。注册为附件数据集后会创建对应的关系数据集。
- 返回:
- 注册成功返回 true,失败返回 false。
- 从以下版本开始:
- 12.0.0
-
unregisterAttachment
public boolean unregisterAttachment()
数据集取消注册附件。取消注册附件后对应的关系数据集会同步删除。
- 返回:
- 取消注册成功返回 true,失败返回 false。
- 从以下版本开始:
- 12.0.0
-
generateAttachmentMatchTable
public DatasetVector generateAttachmentMatchTable(String folderPath, String fieldName, String matchDatasetName, String fileFilter)
通过过滤条件筛选出符合条件的文件,与源数据集生成匹配关系。- 参数:
folderPath- 附件所在文件夹的绝对路径。fieldName- 源数据集字段,用于匹配文件名。例如 fieldName 字段的一个字段值为 supermap,则文件夹内以 supermap 命名的文件将和这个字段值所在行记录建立匹配关系。matchDatasetName- 附件匹配表名称。命名规范参考getName()。fileFilter- 文件过滤条件。可使用通配符(*)表示,多个过滤条件采用分号;隔开,例如(1)过滤条件输入 *.jpg;*.doc,将过滤出后缀名为jpg、doc的所有文件;(2)过滤条件输入 parcel*,将过滤出名称以 parcel 开头的所有文件。过滤出的文件再根据 fieldName 字段值和行记录一一匹配。- 返回:
- 一个存储数据集和附件匹配关系的数据集对象。
- 抛出:
IllegalStateException- 当前数据源为 null 或当前数据源对象已被释放。IllegalArgumentException- 源数据集尚未注册为附件,或字段值 fieldName 在源数据集中不存在或为系统字段,或输入的数据集名 matchDatasetName 不符合命名规范。- 从以下版本开始:
- 12.0.0
-
addAttachments
public boolean addAttachments(DatasetVector matchDataset)
根据生成的附件匹配表批量添加附件。- 参数:
matchDataset- 附件匹配表。由 Datasets.generateAttachmentMatchTable 生成。
- 返回:
- 返回添加附件是否成功,成功返回true,失败返回false。
失败情况:matchDataset 为空或对应附件匹配记录 smid 在当前数据集中不存在 。
- 抛出:
IllegalArgumentException- 当前匹配数据集对象为空或已被释放。- 从以下版本开始:
- 12.0.0
-
removeAttachments
public boolean removeAttachments(DatasetVector matchDataset)
根据附件匹配表移除附件。- 参数:
matchDataset- 附件匹配表由 Datasets.generateAttachmentMatchTable 生成。
- 返回:
- 返回移除附件是否成功,成功返回true,失败返回false。
失败情况:matchDataset 为空或对应附件匹配记录 smid 在当前数据集中不存在 。
- 抛出:
IllegalArgumentException- 当前匹配数据集对象为空或已被释放。- 从以下版本开始:
- 12.0.0
-
getHasM
public boolean getHasM()
返回数据集是否有M值- 返回:
- 是否有M值
- 从以下版本开始:
- 12.0.0
-
getHasZ
public boolean getHasZ()
返回数据集是否有Z值- 返回:
- 是否有Z值
- 从以下版本开始:
- 12.0.0
-
getFieldGroups
public FieldGroups getFieldGroups()
返回矢量数据集的字段组集合,从数据库中重新读取字段组集合。支持字段组的引擎:UDBX、PostGIS。
字段组是数据集中一个或者多个字段的集合,字段组集合包含若干个字段组,一个矢量数据集只有一个字段组集合。
矢量数据集字段组集合中的字段组名称不能重复,包含的字段不能完全一样。
每次通过此接口获取的都是数据集字段组集合的副本,副本修改完需要使用
DatasetVector.setFieldGroups(FieldGroups)保存后才生效- 返回:
- 矢量数据集的字段组集合。
- 从以下版本开始:
- 12.0.0
- 另请参阅:
FieldGroups
-
setFieldGroups
public boolean setFieldGroups(FieldGroups fieldGroups)
设置矢量数据集的字段组集合,将字段组集合保存到数据库中。支持字段组的引擎:UDBX、PostGIS。
设置字段组集合时,如果某个字段组被删除,那么该字段组包含的条件值也会被一起删除,最新的条件值集合需要重新从数据集中获取。
- 参数:
fieldGroups- 字段组集合。- 返回:
- 设置字段组集合是否成功,true表示设置成功,false表示设置失败。
- 从以下版本开始:
- 12.0.0
- 另请参阅:
FieldGroups
-
getContingencies
public Contingencies getContingencies()
获取矢量数据集的条件值集合,从数据库中重新读取条件值集合。支持条件值的引擎:UDBX、PostGIS。
条件值指对于某个字段组内字段值的约束,表示一种允许的字段值组合。一个矢量数据集只有一个条件值集合。
一个条件值必须属于一个字段组,一个字段组可以有0个,1个或者多个条件值。
每次通过此接口获取的都是数据集条件值集合的副本,副本修改完成后需要使用
DatasetVector.setContingencies(Contingencies)保存到数据集,否则修改不会生效。- 返回:
- 矢量数据集的条件值集合
Contingencies的副本。 - 从以下版本开始:
- 12.0.0
- 另请参阅:
Contingencies
-
setContingencies
public boolean setContingencies(Contingencies contingencies)
设置矢量数据集的条件值集合,将条件值集合保存到数据库中。支持条件值的引擎:UDBX、PostGIS。
条件值集合设置时,包含的条件值所属的字段组
FieldGroup必须要先设置给数据集,否则该条件值不会被数据集接受,参考Contingencies中的示例代码。- 参数:
contingencies- 条件值集合Contingencies。- 返回:
- 设置条件值集合是否成功,true表示设置成功,false表示设置失败。
- 从以下版本开始:
- 12.0.0
- 另请参阅:
Contingencies
-
getTextDatasetExtension
public TextDatasetExtension getTextDatasetExtension()
获取文本数据集作为复合关系中目标数据集时的扩展信息。前提条件:1、文本数据集;
2、该文本数据集加入了复合关系类中且作为目标数据集;
- 返回:
- 文本数据集作为复合关系中目标数据集时的扩展信息。
- 从以下版本开始:
- 12.0.1
-
setTextDatasetExtension
public boolean setTextDatasetExtension(TextDatasetExtension textDatasetExtension)
设置文本数据集作为复合关系中目标数据集时的扩展信息。前提条件:1、文本数据集;
2、该文本数据集加入了复合关系类中且作为目标数据集;
3、设置的扩展信息中关联字段在复合关系类源数据集中存在。
- 参数:
textDatasetExtension- 文本数据集的扩展信息。- 返回:
- 设置是否成功。
- 从以下版本开始:
- 12.0.1
-
-
Copyright © 2021–2025 SuperMap. All rights reserved.