Measures the spatial autocorrelation of distance between features. Z-scores reflect the intensity of spatial clustering, and statistically significant peak z-scores indicate distances where spatial processes promoting clustering are most pronounced. These peak distances are often appropriate values to use for tools with a Distance Band or Distance Radius parameter. When doing a similar hot spot analysis or density analysis, choose a suitable distance, very important thing. At this time, through the incremental space autocorrelation, the analysis gets a suitable distance.
Function Entrances
- Spatial Analysis > Spatial Statistical Analysis > Analyzing Mode > Incremental Spatial Autocorrelation. (iDesktop)
- Spatial Statistical Analysis > Analyzing Mode > Incremental Spatial Autocorrelation. (iDesktopX)
- Toolbox > Spatial Statistical Analysis > Analyzing Mode > Incremental Spatial Autocorrelation. (iDesktopX)
Main Parameters
- Source Dataset : sets up the vector data sets to be analyzed, supports points, lines, and regions three types of datasets.
- Assessment Field : Select the property field for the analysis variable. The value of this field should be multiple values, and if all of the properties of the object have a value of 1, then it cannot be solved. Only numeric fields are supported.
- Begin Distance : The initial distance of the Incremental Spatial Autocorrelation Analysis can be determined based on the aggregation of data. If the beginning distance is not given, the default value is the minimum distance. At that distance, each feature of the dataset has at least one adjacent feature. If you have a location exception in your dataset, this distance may not be the most appropriate start distance.
- Incremental Distance : The distance from each analysis of the Incremental Spatial Autocorrelation is analyzed by the starting distance plus the distance increment. If the Distance Increment is not given , the smaller one is used in the average nearest neighbor distance or (Md - B)/C (the Md is maximum threshold distance, B is beginning distance, C is the number of distance). Ensures that the algorithm has to perform the calculation of the number of according to a specified distance, to ensure maximum distance not too much so that some features to all the other features or almost all other features as its adjacent features.
- Incremental Distances Segments : The number of the Incremental Spatial Autocorrelation has been assigned to analyze the dataset. The numerical range is: 2 ~ 30.
- Measure Distance Method : Currently, only Euclidean distance calculation and Manhattanis distance calculation are supported, for more specific instructions about the two calculations, please refer to Basic Vocabulary of Spatial Statistical Analysis.
- Spatial Weights Matrix Standardization :When the distribution of features is likely to deviate due to sampling design or the aggregation scheme imposed, the use of the standardization is recommended. After selecting it, each weight is divided by the sum of the rows (the sum of the weights of all adjacent features). The normalized weights are usually used in combination with the fixed distance adjacent features and are almost always used for the adjacent features of the adjacent side. This can reduce the deviation caused by the different number of adjacent features. Spatial Weights Matrix Standardization takes ownership weights, making them between 0 and 1, creating relative (rather than absolute) weight solutions. Whenever you want to handle the region features that represent administrative boundaries, you might want to choose the “Spatial Weights Matrix Standardization” option.
Results Description
The output is a tabular dataset and drawn in the statistical graph window. It includes six fields: incremental distance, Moran’s index, expected value, variance, Z score, and P value. The z-score reflects the degree of spatial clustering. The statistically significant peak of the z score represents the obvious distance that facilitate clustering of the spatial process. The peak distance for the Z-score is usually a suitable value for the “Distance Range” or “Distance Radius” parameter.
Instance
Given Weibo login data of a city, to study the hot spots and aggregation situation of the spatial distribution of login points, we used the number of logins at each location as the evaluation field to conduct clustering research from both the space and the number of people and obtained results by hot spot analysis or kernel density analysis. . Corresponding results can be obtained through hot spot analysis or kernel density analysis. Before this, we should obtain the appropriate distance through the “incremental spatial autocorrelation” analysis. The results of the incremental spatial autocorrelation analysis are as follows:
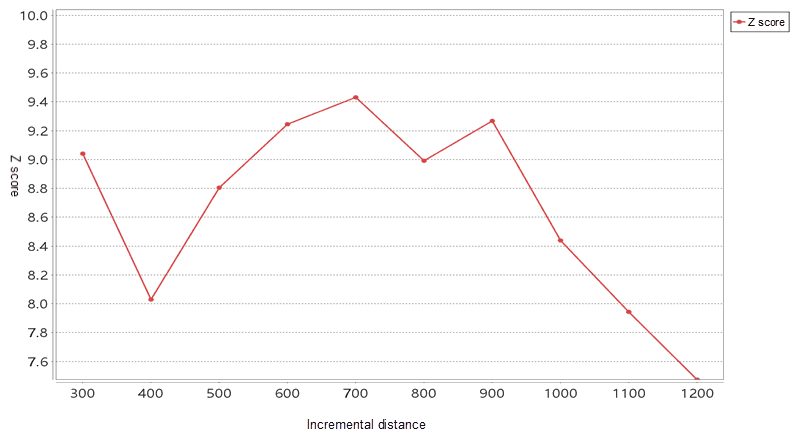
As shown in the figure above, when the distance increment is 700, the Z value is the largest, indicating that 700 is suitable as the distance radius for hot spot analysis of Weibo login data.