

您可以将网络中共享的或本地文件目录中的 csv 文件、udb 数据集文件及子文件夹,以及本地文件目录中的 TIFF、GeoTIFF 栅格数据用于分布式分析。其中,将本地文件目录中存储的栅格数据(如 TIFF、GeoTIFF )注册到 iServer 后,可分布式入库到 HDFS 分布式存储库以及本地文件系统存储中。
您还可以将网络中共享的或本地文件目录中的 udb 数据集文件及子文件夹用于机器学习服务。
1. 注册文件共享目录
登录 iServer 服务管理器,依次点击数据->数据注册,进入注册数据存储页面(http://{ip}:{port}/iserver/admin-ui/data/dataRegistration),点击注册数据存储按钮,并配置以下参数:
- 存储 ID:自定义存储 ID 名称,为数据库创建的唯一标识
- 数据存储类型:选择大数据文件共享
- 文件共享类型:选择共享目录
- 共享目录:输入共享目录地址,例如:D:\folder
点击注册数据存储按钮即完成注册。
在配置共享目录时,您可进行以下操作:
根据您决定使用的 Spark 集群节点数 :
- 如果 Spark 集群中只有一个 Worker 节点,则数据可以直接放到 Worker 节点所在机器的某个文件路径中,如:/home/supermap/data
- 如果有多个 Spark Worker 节点,您可以先为数据所在的目录设置网络共享,在 Worker 节点所在的计算机上将该共享目录映射到本地磁盘。需要注意的是,每台计算机都需要进行映射,且设置的盘符需一致。iServer 管理员注册文件目录时,“共享目录”项填入映射后的目录。
提示:多个 Spark Worker 节点时,为避免映射盘符冲突,不要将数据所在的计算机作为 Spark Worker 节点。
根据您注册的文件类型 :
1.如果注册的 udb 文件、csv文件、TIFF、GeoTIFF 栅格数据,则直接填写该文件所在的目录路径,如:/home/supermap/data
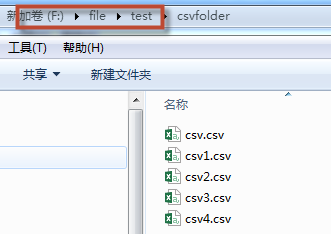
2.如果注册的是带有 csv 文件的文件目录,则需填写csv文件所在的目录的上一级目录。以下图为例,填写的路径为F:\file\test,其中,csv文件的字段、属性等格式必须相同。(仅支持已只读的方式打开csv文件目录)
注意事项:如果您注册的是 csv 数据文件,需要经过验证,才可用于分布式分析服务。详见:csv 数据文件验证
2. 机器学习服务
配置步骤如下:
- 登录 iServer 服务管理器,依次点击数据->数据注册;
- 进入数据注册页面,点击注册数据存储;
- 创建存储ID、依次选择大数据目录共享、共享目录;
- 如果注册的是 udb 文件,则直接填写该文件所在的目录路径,如:/home/supermap/data