

空间密度聚类是指对点集合进行空间位置的聚类,使用密度聚类方法DBSCAN,它能将具有足够高密度的区域划分为簇,并可以在带有噪声的空间数据中发现任意形状的聚类。
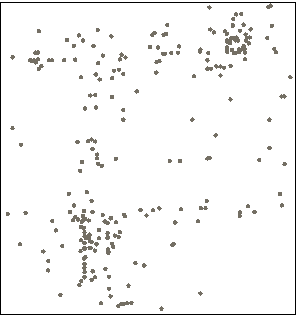
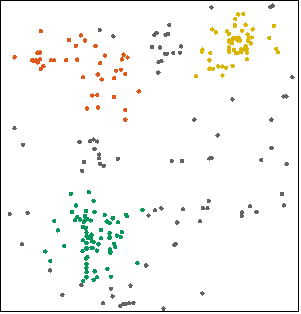
图一:点对象 图二:对点对象实现空间密度聚类的结果
创建密度聚类任务时,需要设置以下参数:
分析数据集:必填参数,需要进行密度聚类分析的数据集访问连接信息,需要包含数据类型,连接参数,数据集名字等信息。可以连接HBase数据,dsf数据,本地数据。
数据查询条件:可选参数,可以根据此查询条件筛选出指定数据进行相应分析,支持属性条件和空间查询, 如 SmID<100 and BBOX(the_geom, 120,30,121,31)。
聚类半径:必填参数。设置点密度聚类的半径,表示指定半径范围内,点的数目大于等于阈值时,则表示这些点为一个类别。输入时需要带单位,如1Kilometer,支持单位有Meter,Centimeter,Millimeter,Decimeter,Kilometer,Yard,Inch,Foot,Mile,Degree,Second,Minute,Radian,缺省单位为Meter。
聚类数目阈值:必填参数,用于显示和设置聚类为一簇的最少点个数,该值必须大于或等于2。阈值越大表示能聚类为一簇的条件越苛刻。判断是否是核心的依据,注意该值是包括本身在内的个数。
保存聚类类别的字段名:必填参数,用于统计聚类类别信息,最好设置为除cluster以外的字段名,否则会因与关键字冲突而自动变为NewField。
需要保留到结果数据集中的字段:可选参数,可选择将原数据集中的指定字段进行保留,默认情形下保留存有字段。
结果数据集:必填参数,输出分析结果数据集的信息,需要包含数据类型,连接参数,数据集名字等信息。
Spark上下文环境:可选参数,spark的运行环境,默认使用local模式,指使用本机的spark环境。另外还能设置集群环境,设置集群的ip和端口号。