SuperMap iServer distributed analysis supports using the Hadoop Yarn cluster, you can build it yourself by following the process below. This chapter describes how to set up a Hadoop Yarn cluster without Kerberos authentication.
Software requirements
To set up a Hadoop Yarn cluster environment, you need to configure the Java environment (JDK download address http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html#javasejdk, JDK 8 and above is recommended), SSH and hadoop.
The softwares used in this example are:
Hadoop installation package: hadoop-2.7.3.tar.gz stored in: /home/iserver
JDK installation package: jdk-8u131-linux-x64.tar.gz
Construction process
In this example, a Hadoop Yarn cluster with one master and one worker is built on two ubuntus (each has 12 g of memory). The steps are shown as follows:
- Prepare two virtual machines (master, worker) and configure JAVA_HOME in /etc/profile on each machine as follows:
export JAVA_HOME=/home/supermap/java/jdk1.8.0_131
export PATH=${JAVA_HOME}/bin:$PATH
Execute source /etc/profile to make the environment variables take effect.
- Configure login without password under master and worker users
Execute ssh-keygen -t rsa -P'' on master and worker respectively (-P indicates password, can be ignored, defaults to enter three times of "Enter" key). After executing the command, the private key file (id_rsa) and public key file (id_rsa.pub) will be generated in /home/hdfs/.ssh directory. Then execute the following command on the master and worker respectively:
ssh-copy-id -i /home/hdfs/.ssh/id_rsa.pub ip
When execute on master, wirite the ip of the worker node; and write the ip of the master node if executing on worker node. Then run ssh worker/master on the master and worker to verify if the configuration is successful.
- Configure Hadoop
Place a complete hadoop package in the master directory and configure it as follows:
Enter /home/supermap/hadoop-2.7.6/etc/hadoop directory:
-
- Open hadoop-env.sh file, add:
export JAVA_HOME=/home/supermap/java/jdk1.8.0_131
-
- Open yarn-env.sh file, add:
export JAVA_HOME=/home/supermap/java/jdk1.8.0_131
-
- Add the following configuration in yarn-site.xml. 192.168.112.131 is the ip of the master node.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.112.131</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.112.131:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.112.131:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.112.131:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.112.131:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.112.131:8088</value>
</property>
<!--<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
</configuration>
-
- Add the following configuration in core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.112.131:9000</value>
</property>
<!-- <property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/supermap/hadoop/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
-
- Add the following configuration in hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.112.131:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.112.131:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/supermap/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/supermap/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
-
- Add the following configuration in mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.112.131:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.112.131:19888</value>
</property>
</configuration>
-
- Configure the host name of the master node in the master file, for example: master; and configure the host name of the child node in the slaves file, for example: worker. After the master node is configured, run the following command to copy the configuration to the worker:
Scp –r /home/supermap/hadoop-2.7.6/etc/hadoop root@worker:/home/supermap/hadoop-2.7.6/etc/hadoop
In this way, the worker becomes a child of the yarn cluster, and the master and slaves files are also needed to be modified in the child nodes. Up to now, a simple yarn cluster has been set up.
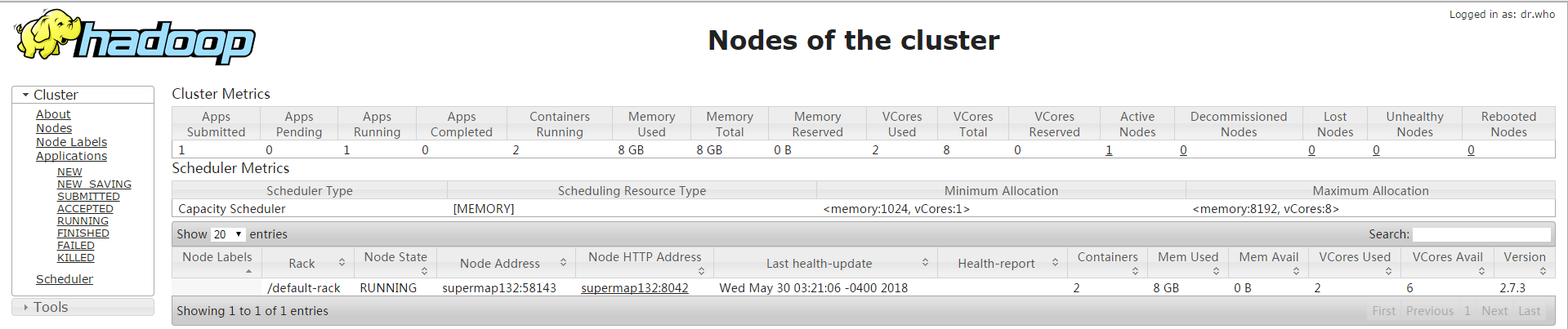
- After the building, enter /home/supermap/hadoop-2.7.6/bin/ on master node and execute ./hadoop namenode -format to perform format. After the format is successful, enter the sbin directory and execute ./start-all.sh to start yarn and hdfs at the same time. You can also start start-yarn.sh and start-dfs.sh to start yarn and hdfs respectively. After successful startup, access the web address of yarn: http://master:8088, the interface is as follows:
- To perform distirbuted analysis, you also need to configure UGO for each sub-node of the Hadoop Yarn cluster. For details, see: ugo configuration.