教程
常见问题解答
-
Oracle数据库与SuperMap iDesktop连接不上,如何解决?
答:出现上述情况,请在Oracle中创建并使用新的数据库。具体步骤如下:
(1)在iManager页面点击数据库->Oracle->名称(您的数据库名称)->oracle->命令行进入Oracle命令行;
(2)在目录 u01/app/oracle/oradata 下创建“supermapshapefile”文件夹,执行(如果您已有文件夹,请跳过该步骤):
mkdir -p /u01/app/oracle/oradata/supermapshapefile(3)赋予数据库权限,执行:
chown oracle /u01/app/oracle/oradata/supermapshapefile(4)进入Oracle,执行:
sqlplus / as sysdba(5)输入Oracle用户密码,用户密码请在iManager页面点击数据库->Oracle->名称(您的数据库名称)->账户查看;
(6)创建空间表,大小为200M(可根据实际情况设置),执行:
create tablespace supermaptbs datafile '/u01/app/oracle/oradata/supermapshapefile/data.dbf' size 200M;(7)创建数据库新用户,账号:supermapuser(可自由设置),密码:supermap123(可自由设置),执行:
create user supermapuser identified by supermap123 default tablespace supermaptbs;(8)给新用户赋予权限,执行:
grant connect,resource to supermapuser; grant dba to supermapuser; -
在重新部署/调整规格后,又立马进行重新部署/调整规格操作,导致分配许可失败,如何解决?
答:在重新部署/调整规格后,请确保本次操作对应的容器在许可中心中分配许可成功后,再进行下一次的重新部署/调整规格操作。
-
查看实时监控统计图时,图表中没有数据或数据生成的时间与实际时间不符,如何解决?
答:查看实时监控统计图时,请确保您的本地机器与Kubernetes节点机器设置的时间一致。
-
如何使用https协议?
答:iManager支持使用https服务协议,请执行以下步骤:
(1)进入iManager安装目录(即执行iManager启动命令的目录)并找到values.yml文件,在当前目录下输入命令打开配置:
sudo vi values.yml(2)将变量“deploy_imanager_service_protocol”的值改为“https”。
(3)保存设置,并重启iManager:
sudo ./startup.sh -
如何替换iManager for K8s自带的安全证书?
答:请参照以下步骤替换访问入口域名使用的安全证书:
(1)在安装Kubernetes Master节点机器中执行以下命令,找到安全证书挂载目录(下面命令中的
<namespace>为iManager所在的命令空间,默认为supermap。如有改动,请替换为您的命名空间名称):kubectl -n <namespace> describe pvc pvc-imanager-dashboard-ui | grep Volume: | awk -F ' ' '{print $2}' | xargs kubectl describe pv(2)将您的安全证书文件存放至步骤(1)查到的挂载目录中;
注意:
安全证书文件包括证书和私钥,需要将证书文件重命名为certificate.crt,将私钥文件重命名为private.key。(3)登录iManager,在基础服务中找到imanager-dashboard-ui服务并重新部署。
-
配置镜像拉取Secret时,如何在命名空间下创建与Secret同名资源?
答:如果您配置的是私有仓库,在配置Secret后,需在Kubernetes中iManager所在命名空间下创建与Secret同名的资源。如果开启服务网格(Istio),需在istio-system命名空间下创建Secret同名资源。如果开启metrics server服务,需在kube-system命名空间下创建Secret同名资源。请在Kubernetes Master机器中,输入如下命令创建Secret同名资源:
kubectl create secret docker-registry <image-pull-secret> --docker-server=<"172.16.17.11:5002"> --docker-username=<admin> --docker-password=<adminpassword> -n <supermap>注意:
- 输入的内容中,带有尖括号”<>“的需根据您的实际环境替换(替换后去掉尖括号)。
<image-pull-secret>为您的Secret名称;<"172.16.17.11:5002">为您的镜像仓库地址;<admin>为镜像仓库用户名;<adminpassword>为镜像仓库密码;<supermap>为iManager所在命名空间(在istio-system或kube-system下创建Secret同名资源时,<supermap>替换为“istio-system”或“kube-system”)。 - 如果命名空间istio-system不存在,在Kubernetes Master节点机器输入“kubectl create ns istio-system”命令进行创建。
- 输入的内容中,带有尖括号”<>“的需根据您的实际环境替换(替换后去掉尖括号)。
-
修改iManager的配置文件values.yaml后,重启iManager出现报错“Error: UPGRADE FAILED: cannot patch “pv-nfs-grafana” with kind StorageClass: StorageClass.storage.k8s.io “pv-nfs-grafana” is invalid …”, 怎么办?
答:该错误产生的原因是K8s patch操作不支持对存储类的提供者进行更新。此报错不影响产品正常使用,可忽略。
-
Kubernetes证书到期了,如何更新?
答:Kubernetes证书有效期为1年,过期后需更新证书。请参照以下步骤更新Kubernetes证书:
(1)在安装Kubernetes的Master节点机器,进入etc/kubernetes/pki目录,创建备份目录:
cd /etc/kubernetes/pki/ mkdir -p ~/tmp/BACKUP_etc_kubernetes_pki/etcd/(2)备份原有的证书:
mv apiserver.crt apiserver-etcd-client.key apiserver-kubelet-client.crt front-proxy-ca.crt front-proxy-client.crt front-proxy-client.key front-proxy-ca.key apiserver-kubelet-client.key apiserver.key apiserver-etcd-client.crt ~/tmp/BACKUP_etc_kubernetes_pki/. mv etcd/healthcheck-client.* etcd/peer.* etcd/server.* ~/tmp/BACKUP_etc_kubernetes_pki/etcd/(3)重新生成新的证书:
kubeadm init phase certs all(4)进入etc/kubernetes目录,创建备份配置文件目录,备份原有的配置文件:
cd /etc/kubernetes/ mkdir -p ~/tmp/BACKUP_etc_kubernetes mv admin.conf controller-manager.conf kubelet.conf scheduler.conf ~/tmp/BACKUP_etc_kubernetes/.(5)重新生成配置文件:
kubeadm init phase kubeconfig all(6)重启Kubernetes Master节点:
reboot(7)复制并替换原来的文件:
mkdir -p ~/tmp/BACKUP_home_.kube cp -r ~/.kube/* ~/tmp/BACKUP_home_.kube/. cp -i /etc/kubernetes/admin.conf $HOME/.kube/config(8)查看更新证书后Kubernetes集群信息(使用
kubectl cluster-info命令):kubectl cluster-info -
内置HBase环境如何使用本地存储?
答:经测试,挂载NFS会影响Hbase的读写性能,可以通过以下方式进行优化:
(1)修改配置(values.yaml)文件中deploy_disable_hbase_nfs_volume的值为true
deploy_disable_hbase_nfs_volume: true(2)根据编排创建PV:参考 hbase-datanode-local-volume.yaml 文件,根据实际情况进行修改:
apiVersion: v1 kind: PersistentVolume metadata: labels: type: icloud-native name: icloud-native-hbase-datanode-volume-0 #修改点1 spec: storageClassName: local-volume-storage-class capacity: storage: 10Ti accessModes: - ReadWriteMany local: path: /opt/imanager-data/datanode-data #修改点2 persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node1 # 修改点3需要修改的内容涉及上图中标记处的3个地方:
- 修改点1:这里指定PV的名称,只要不重复即可。
- 修改点2:这里是实际要存储HBase数据的路径,要提前创建好目录。如果想在一个节点上创建多个PV请修改成不同的目录,并提前创建好目录。
使用以下命令在对应节点上创建目录(路径换成自己设置的具体地址):
mkdir -p /opt/imanager-data/datanode-data- 修改点3:这里填写Kubernetes的节点名称(前提是相应的节点能参与调度)
(3)修改后通过编排创建PV(在Kubernetes master节点执行以下命令):
kubectl apply -f hbase-datanode-local-volume.yaml备注:
- HBase环境中的dataNode有几个副本就要创建几个PV,默认需要3个;如果自己伸缩了,请创建对应数目的PV;
- PV可以创建在任意Kubernetes节点上(通过
修改点3指定),推荐均匀分布在不同的节点上; - PV既可以在开启/伸缩HBase之前创建,也可以在开启/伸缩HBase之后创建。
-
系统运行过程中出现系统没有响应,检查系统日志后发现错误“echo 0 > /proc/sys/kernel/hungtasktimeout_secs” disables this message.”,如何解决?
答: 这是因为在系统运行过程中负载飙升,文件系统脏数据缓存无法在指定时间内写入磁盘,导致系统挂起。这种情况一般在内存较大时出现,解决办法如下:
(1)编辑 /etc/sysctl.conf 文件。设置脏数据处理时间以及写入超时时间:
# 脏数据到达系统百分比开始处理 vm.dirty_background_ratio=5 # 脏数据到达系统百分比时,不得不处理 vm.dirty_ratio=10 # 脏数据写入超时时间,默认 120s,0 表示不限制 kernel.hung_task_timeout_secs=0(2)强制重启。系统挂起情况下,重启机器可能失败,因此需要强制重启:
reboot -n -f -
在Kubernetes服务器集群中,某台服务器出现故障,导致该服务器上的服务不可用,如何应对?
答:如果您的Kubernetes集群由三台或三台以上的服务器组成(含Master节点服务器),当某Worker节点服务器出现故障时,在该服务器中运行的服务会自动迁移至其他Worker节点服务器,自动迁移时长根据您的环境有所不同,大概在20分钟左右。如果您的Kubernetes集群只有两台服务器,当Worker节点服务器出现故障后,请参考以下步骤手动恢复服务:
(1)在Master节点服务器中,查看服务器名称:
kubectl get nodes(2)修改Master节点服务器名称。使用如下命令修改:
hostnamectl set-hostname <newhostname>备注:
命令中的<newhostname>为您的Master节点服务器新名称,可自定义。(3)进入/etc/kubernetes/manifests目录:
cd /etc/kubernetes/manifests(4)编辑etcd.yaml文件,将文件中包含Master节点服务器旧名称的内容改为新设定的名称(共有两处,如下图)。执行以下命名进入文件编辑页面:
vi etcd.yaml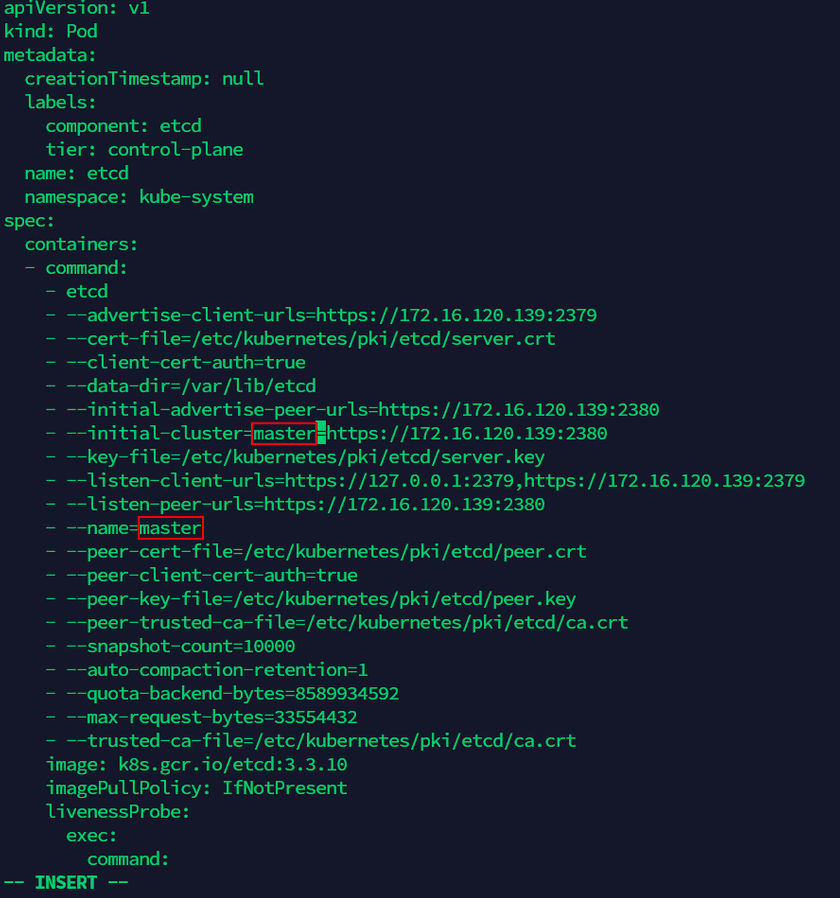
(5)导出Worker节点服务器的配置文件:
kubectl get node <old-nodeName> -o yaml > node.yaml备注:
命令中的<old-nodeName>为您的Worker节点服务器的名称,可通过步骤(1)中的命令查看。(6)修改node.yaml文件,将文件中包含Worker节点服务器名称的内容改为Master节点服务器的新名称,并在
labels中加入编排node-role.kubernetes.io/master: ""(共有四处名称需要更改,在红线处加入编排,如下图):vi node.yaml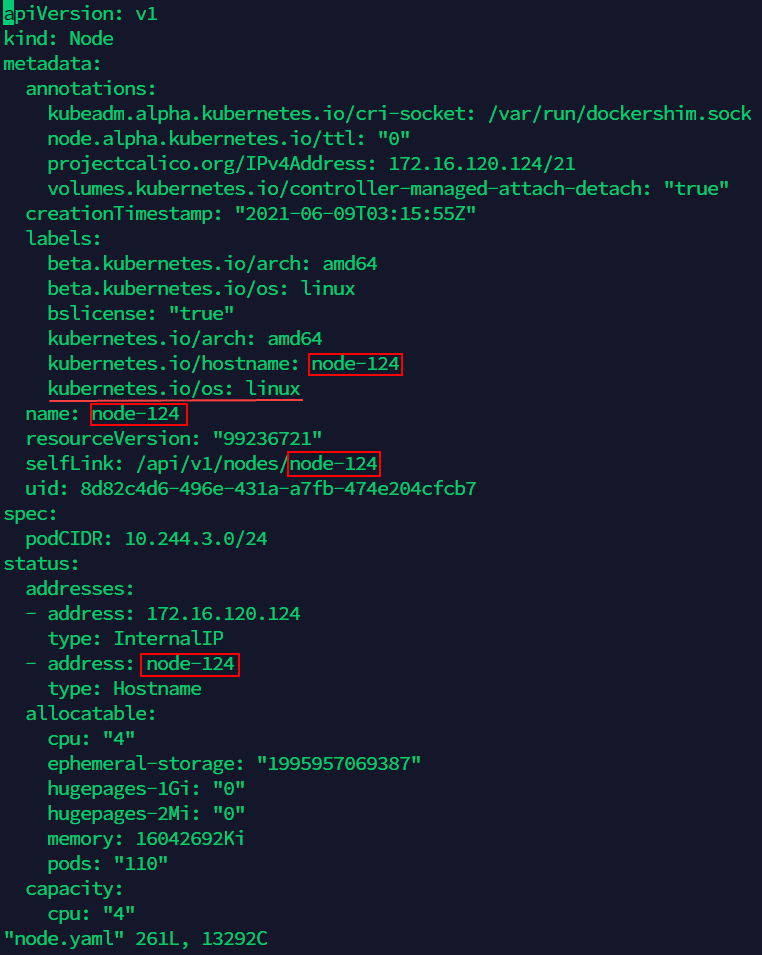
(7)修改kube-system命名空间下的kubeadm-config ConfigMap,将其中的Master节点服务器的旧名称改为新名称(有一处需要更改,如下图):
kubectl -n kube-system edit configmap kubeadm-config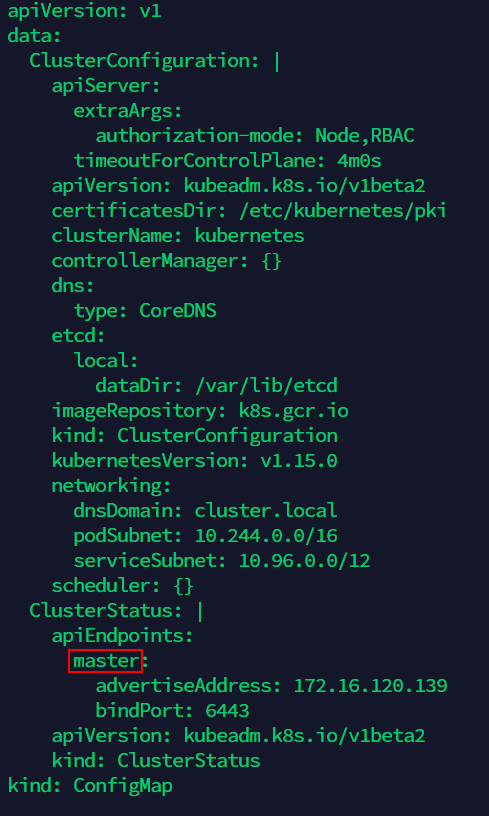
(8)为服务器生成新证书,替换旧证书。执行如下操作:
cd /etc/kubernetes/pki/ mkdir -p ~/tmp/BACKUP_etc_kubernetes_pki/etcd/ mv apiserver.crt apiserver-etcd-client.key apiserver-kubelet-client.crt front-proxy-ca.crt front-proxy-client.crt front-proxy-client.key front-proxy-ca.key apiserver-kubelet-client.key apiserver.key apiserver-etcd-client.crt ~/tmp/BACKUP_etc_kubernetes_pki/. mv etcd/healthcheck-client.* etcd/peer.* etcd/server.* ~/tmp/BACKUP_etc_kubernetes_pki/etcd/ kubeadm init phase certs all cd /etc/kubernetes mkdir -p ~/tmp/BACKUP_etc_kubernetes mv admin.conf controller-manager.conf kubelet.conf scheduler.conf ~/tmp/BACKUP_etc_kubernetes/. kubeadm init phase kubeconfig all mkdir -p ~/tmp/BACKUP_home_.kube cp -r ~/.kube/* ~/tmp/BACKUP_home_.kube/. cp -i /etc/kubernetes/admin.conf $HOME/.kube/config(9)应用步骤(6)中修改过的Worker节点服务器配置文件:
kubectl apply -f node.yaml(10)移除原Worker节点服务器:
kubectl delete node <old-nodeName>(11)重启kubelet和docker服务:
systemctl daemon-reload && systemctl restart kubelet && systemctl restart doker -
在Kubernetes环境下安装部署iManager时,执行“./startup.sh”命令如果出现报错:The connection to the server localhost:8080 was refused - did you specify the right host or port? Error: Kubernetes cluster unreachable,如何解决?
答:有两种解决方案可解决上述问题,请在以下方法中任选一种:
切换为root用户解决方案
切换至root用户后,重新执行以下命令:
sudo ./startup.sh增加kubectl使用权限解决方案
在服务器任一目录下,执行以下命令:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.kubeconf $HOME/.kube/config sudo chown userName:userName $HOME/.kube/config备注:
命令中的<userName>为您的实际用户名,请替换。 -
在某站点服务列表中,点击服务名称进入详情页面后点击容器列表中的“日志”,存在错误“error”的信息,而在站点管理页面点击该服务操作栏中的“日志”,kibana页面却没有显示含“error”的日志信息,应如何解决?
答:需更改服务守护进程DaemonSet “fluentd-es”镜像的挂载目录,有两种方式可解决上述问题,请任选一种:
Kubernetes的dashboard界面内更改
(1)访问
http://<ip>:31234进入kubernetes的dashboard界面。<ip>是iManager所在机器的ip;(2)命名空间选择
supermap,左边栏点击工作负载Workloads的Daemon Sets;(3)选择“fluentd-es”进行编辑,找到所有的默认挂载目录“/var/lib/docker/containers”处,如下图所示。分别修改为“/data/docker/containers”,或自定义docker存储路径;
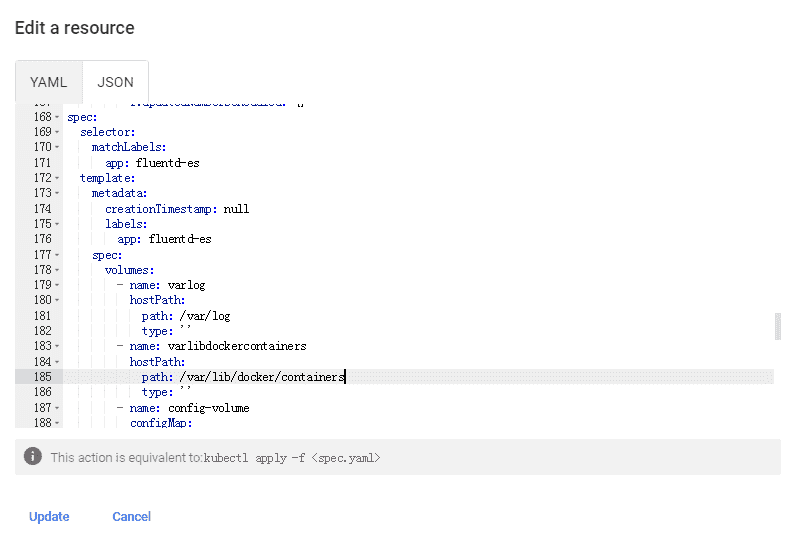
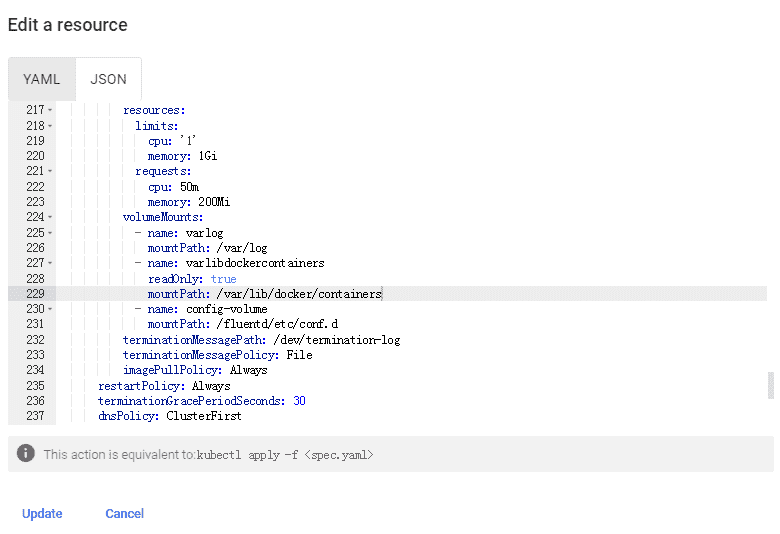
(4)点击更新按钮,完成更改。
使用命令行更改
(1)在Master节点服务器中,执行以下命令:
kubectl -n supermap edit daemonset fluentd-es(2)找到所有的默认挂载目录“/var/lib/docker/containers”处,分别修改为“/data/docker/containers”,或自定义docker存储路径;
(3)命令行输入“:wq”保存并退出,完成更改。
注意:
完成更改后请稍作等待,即可通过站点管理页面的“日志”功能正常查看日志信息。
-
在站点管理页面下方统计图处,未能正常显示出CPU使用率等各服务资源的具体统计图信息,而显示为“No data points”。点击需监控容器的服务名称后,在页面下方查看该容器的统计图出现同样问题。经排查发现docker默认存储路径不是“/var/lib/docker”,而导致该问题的出现,应如何解决?
答:docker默认存储路径非“/var/lib/docker”所致无法正常显示监控统计图,是由于kubelet中内置的Docker容器性能分析工具cAdvisor无法获取到容器信息。请参考以下步骤解决上述问题:
(1)编辑kubelet的启动文件,执行以下命令:
vim /usr/lib/systemd/system/kubelet.service(2)在ExecStart参数处增加“—docker-root”的配置,设为排查时发现的docker实际存储路径,如下图所示,实际路径为“/data/docker”。
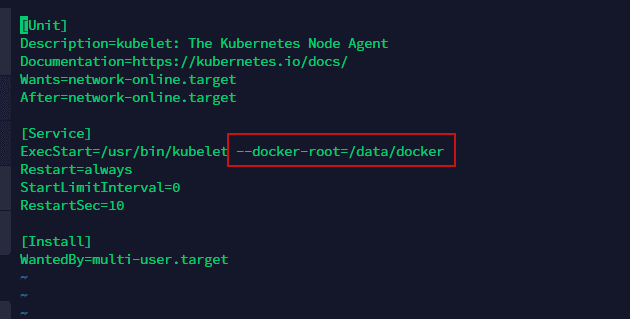
(3)命令行输入“:wq”保存并退出,完成修改。
(4)重启kubelet使配置生效,执行以下命令:
systemctl daemon-reload systemctl restart kubelet
注:
排查docker默认存储路径时,可通过/etc/docker/daemon.json文件的graph值查看。
-
如果GIS云套件站点的服务节点(gisapplication)在接收多并发请求时发生崩溃,出现异常导致服务访问失败,应如何解决?
答:系统默认服务节点(gisapplication)可接收200个并发请求,当请求数量超过200个并且该服务响应时间耗时较长,接收超出默认数量的请求时则会使得该服务节点崩溃。当上述问题出现后,请参考以下步骤手动添加环境变量解决:
(1)在iManager界面的GIS云套件站点服务列表中,对发生崩溃的“gisapp-*”服务节点执行编辑操作。
(2)定位至环境变量处,如下图所示。
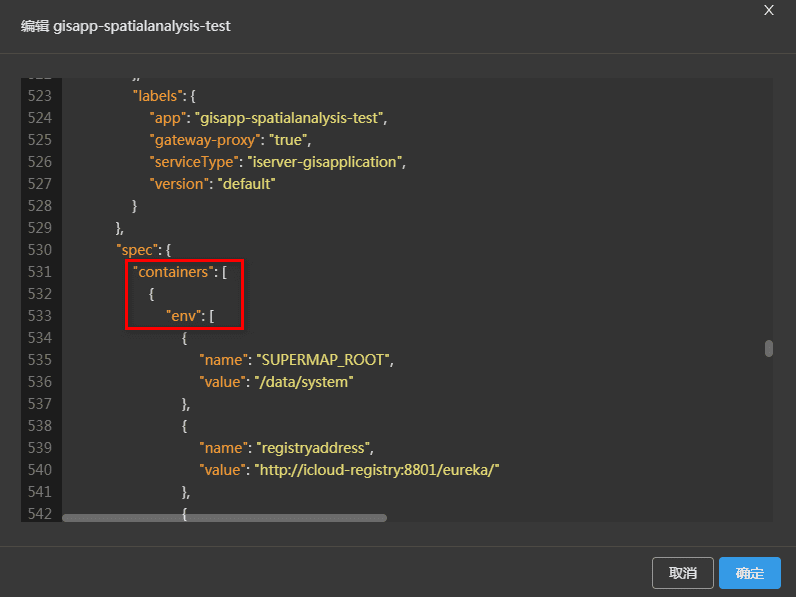
(3)添加名为“icn_ext_param_server_tomcat_threads_max”的环境变量,并根据所需接收请求数设值。如下图设置,则支持接收1000个并发请求。
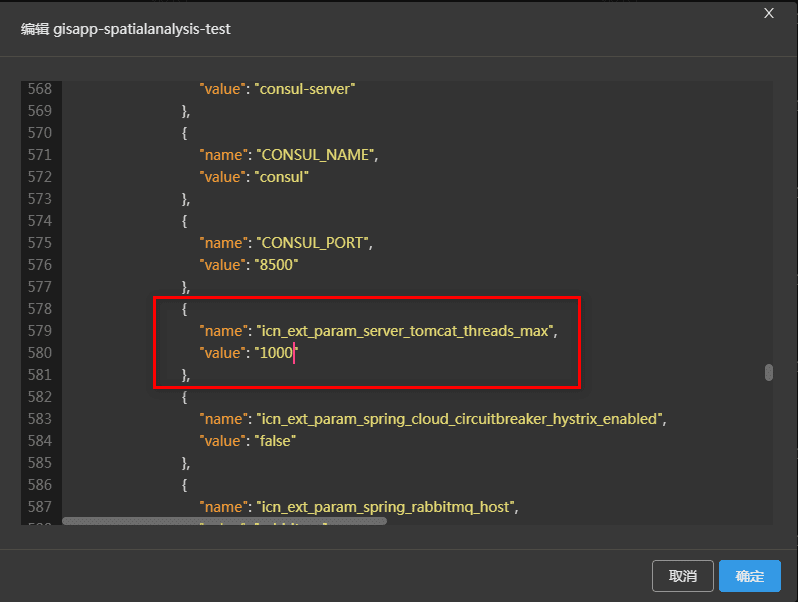
(4)点击确定,待重启后生效。
注意:
增加请求数后,需通过调整规格适当增加该服务节点的CUP与内存大小,以确保服务运行稳定。
-
如何重置管理员账户密码?
答:在iManager安装目录下有名为reset-password.sh的文件,用来重置管理员账户,请按以下步骤重置管理员账户密码:
(1)进入iManager安装目录(即执行iManager安装命令的目录);
(2)执行reset-password.sh脚本文件进行重置:
chmod +x reset-password.sh && ./reset-password.sh