Tutorial
FAQ
-
How to solve the problem when the database in Oracle could not connect with SuperMap iDesktop?
Answer: Please create a new database in Oracle, and use the new one. Follow the steps below to create a new database:
(1) Click Database > Oracle > Name(The name of your database) > oracle > Command Pad on the iManager to enter Oracle comnmand pad.
(2) Create a folder named ‘supermapshapefile’ under the ‘u01/app/oracle/oradata’ directory(If you already have a folder, skip this step). Execute:
mkdir -p /u01/app/oracle/oradata/supermapshapefile(3) Change the folder owner to oracle. Execute:
chown oracle /u01/app/oracle/oradata/supermapshapefile(4) Enter Oracle. Execute:
sqlplus / as sysdba(5) Fill in the username and password of Oracle. You can view account information by clicking Database > Oracle > Name > Account on the iManager page.
(6) Create a tablespace, the size is 200M(you can set the size of tablespace according to your requirement). Execute:
create tablespace supermaptbs datafile '/u01/app/oracle/oradata/supermapshapefile/data.dbf' size 200M;(7) Create a new user of the tablespace. For example, username: supermapuser; password: supermap123. Execute:
create user supermapuser identified by supermap123 default tablespace supermaptbs;(8) Grant new user permission. Execute:
grant connect,resource to supermapuser; grant dba to supermapuser; -
If you redeploy or adjust spec immediately after deploying or adjusting spec, the license assign failed, how to solve the problem?
Answer: After redeploying or adjusting spec, please make sure the services have been assigned the license successfully, then do others operations like redeploy or adjust spec.
-
When viewing monitoring statistic charts, the charts do not display data or the time of data can not match the real time, how to solve the problem?
Answer: Please make sure the time settings of local machine and Kubernetes node machines are same.
-
How to use the https protocol?
Answer: iManager supports https protocol, please do the following operations to achieve https protocol:
(1) Go to the iManager installation directory(the directory in which you executed ./startup or ./start command to start iManager) and find out the file named values.yml, execute the following command:
sudo vi values.yml(2) Modify the value of “deploy_imanager_service_protocol” to “https” when you need to use iManager https protocol.
(3) Save the setting and restart iManager:
sudo ./startup.sh -
How to replace the security certificate in iManager for K8s?
Answer: There are two kinds of security certificates in iManager for K8s, one is for security center(Keycloak), another one is for access entrance. Please follow the steps below to replace two security certificates separately:
Replace the Security Certificate for Keycloak
(1) Executes the following command on Kubernetes Master machine to find the volume of the security certificate(
<namespace>in the command is the namespace of iManager, it is ‘supermap’ by default. Please replace to the actual namespace if you have any change):kubectl -n <namespace> describe pvc pvc-keycloak | grep Volume: | awk -F ' ' '{print $2}' | xargs kubectl describe pv(2) Stores your new security certificate to the volume in step (1);
Notes:
The security certificate includes certificate and private key, the certificate should be renamed to tls.crt, the private key should be renamed to tsl.key.(3) Logs in to iManager and redeploys the Keycloak service in Basic Services.
Replace the Security Certificate for Access Entrance
(1) Executes the following command on Kubernetes Master machine to find the volume of the security certificate(
<namespace>in the command is the namespace of iManager, it is ‘supermap’ by default. Please replace to the actual namespace if you have any change):kubectl -n <namespace> describe pvc pvc-imanager-dashboard-ui | grep Volume: | awk -F ' ' '{print $2}' | xargs kubectl describe pv(2) Stores your new security certificate to the volume in step (1);
Notes:
The security certificate includes certificate and private key, the certificate should be renamed to ‘certificate.crt’, the private key should be renamed to ‘private.key’.(3) Logs in to iManager and redeploys the imanager-dashboard-ui service in Basic Services.
-
How to create the resource with the same name as the Secret when configuring the image pull secret?
Answer: When configuring the Secret, you need to create a resource with the same name as the Secret in iManager namespace of Kubernetes. You also need to create a resource with the same name as the secret value in namespace ‘istio-system’ when enabling Service Mesh(Istio). And create a resource with the same name as the secret value in namespace ‘kube-system’ when enabling metrics server. Please enter the following command in Kubernetes Master machine to create the resource:
kubectl create secret docker-registry <image-pull-secret> --docker-server="<172.16.17.11:5002>" --docker-username=<admin> --docker-password=<adminpassword> -n <supermap>Notes:
- The contents in the command with symbol ”<>” need to be replaced according to your actual environment(Delete the symbol ”<>” after replacing).
<image-pull-secret>is the name of your Secret;<172.16.17.11:5002>is your registry address;<admin>is the namespace of your registry;<adminpassword>is the password of your namespace;<supermap>is the namespace of iManager(replace<supermap>to ‘istio-system’ or ‘kube-system’ when you create the resource in the namespace istio-system or kube-system). - If the namespace istio-system does not exist, execute ‘kubectl create ns istio-system’ in the machine of Kubernetes master node to create.
- The contents in the command with symbol ”<>” need to be replaced according to your actual environment(Delete the symbol ”<>” after replacing).
-
How to solve the error “Error: UPGRADE FAILED: cannot patch “pv-nfs-grafana” with kind StorageClass: StorageClass.storage.k8s.io “pv-nfs-grafana” is invalid …” when you restart iManager?
Answer: The error occurs because Kubernetes patch operation does not support to update the provider of storageClass. The error has no negative influence on iManager, please ignore the error.
-
How to refresh the certificate of Kubernetes?
Answer: The validity period of Kubernetes certificate is one year, you need to refresh the certificate when expired. Please follow the steps below to refresh the certificate of Kubernetes:
(1) Enter the /etc/kubernetes/pki directory of the master machine of Kubernetes, create a backup directory:
cd /etc/kubernetes/pki/ mkdir -p ~/tmp/BACKUP_etc_kubernetes_pki/etcd/(2) Backup the original certificate:
mv apiserver.crt apiserver-etcd-client.key apiserver-kubelet-client.crt front-proxy-ca.crt front-proxy-client.crt front-proxy-client.key front-proxy-ca.key apiserver-kubelet-client.key apiserver.key apiserver-etcd-client.crt ~/tmp/BACKUP_etc_kubernetes_pki/. mv etcd/healthcheck-client.* etcd/peer.* etcd/server.* ~/tmp/BACKUP_etc_kubernetes_pki/etcd/(3) Regenerate the new certificate:
kubeadm init phase certs all(4) Enter the /etc/kubernetes directory, create a backup directory of the configuration file:
cd /etc/kubernetes/ mkdir -p ~/tmp/BACKUP_etc_kubernetes mv admin.conf controller-manager.conf kubelet.conf scheduler.conf ~/tmp/BACKUP_etc_kubernetes/.(5) Regenerate the configuration file:
kubeadm init phase kubeconfig all(6) Restart the Kubernetes MasterNode:
reboot(7) Copy and overwrite the original file:
mkdir -p ~/tmp/BACKUP_home_.kube cp -r ~/.kube/* ~/tmp/BACKUP_home_.kube/. cp -i /etc/kubernetes/admin.conf $HOME/.kube/config(8) Check the Kubernetes cluster information after updating the certificate(use the command
kubectl cluster-info):kubectl cluster-info -
How to configure local storage for built-in HBase environment?
Answer: The NFS volume will impact the write/read ability of HBase, you can optimize the ability by the following way:
(1) Modify the value of
deploy_disable_hbase_nfs_volumetotruein the configuration(values.yaml).deploy_disable_hbase_nfs_volume: true(2) Please refer to the hbase-datanode-local-volume.yaml file, and modify the file according to the actual situation:
apiVersion: v1 kind: PersistentVolume metadata: labels: type: icloud-native name: icloud-native-hbase-datanode-volume-0 #Point 1 spec: storageClassName: local-volume-storage-class capacity: storage: 10Ti accessModes: - ReadWriteMany local: path: /opt/imanager-data/datanode-data #Point 2 persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node1 #Point 3The places need to be modified are marked by ’#’ on the above:
- Point 1: Specify the name of the PV.
- Point 2: The actual path to store the HBase data, please create the directory first. If you want to create multiple PVs on one node, please create multiple directories and modify the paths to the different directories.
Use the command below to create directory on the node(replace the path by your actual setting):
mkdir -p /opt/imanager-data/datanode-data- Point 3: Fill in the name of the node of Kubernetes(the node should be available to scheduling).
(3) Execute the command on the Kubernetes master node after modifying:
kubectl apply -f hbase-datanode-local-volume.yamlNotes:
- The number of PVs should be the same as the number of dataNodes in HBase environment, the default is 3. If you scaled the node, please created the the same number of PVs.
- The PV could be created on any node of Kubernetes(specified by #Third), recommended to create on different nodes.
- The PV could be created before opening/scaling the HBase, or after opening/scaling the HBase.
-
How to solve the problem that the system is hanging, and the log of system has the error “echo 0 > /proc/sys/kernel/hungtasktimeout_secs” disables this message.”?
Answer: The reason of system hangs is the rising loading when system is running, the dirty data of files system can not be written into the disk in the stipulated time. Please refer to the following steps to solve the problem:
(1) Edit the file ‘sysctl.conf’ in ‘/etc’ derectory. Set the method of processing dirty data and the timeout of writting dirty data:
# When the system dirty data reach to the ratio, the system start to process vm.dirty_background_ratio=5 # When the system dirty data reach to the ratio, the system must process vm.dirty_ratio=10 # The timeout of writing dirty data, the value is 120 second by default, 0 mean no limit kernel.hung_task_timeout_secs=0(2) Force restart, execute the command:
reboot -n -f -
How to solve the problem that a worker node server breakdown in Kubernetes cluster?
Answer: If your Kubernetes cluster is made up by three or more than three servers(include Master node server), when a worker node server breakdown, the services which are running in the worker node server will emmigrate to other worker node servers automatically. If your Kubernetes cluster is made up by two servers, when the worker node server breakdown, please follow the steps below to recover services:
(1) Check the servers name in Master node server:
kubectl get nodes(2) Change the name of Master node server:
hostnamectl set-hostname <newhostname>Notes:
<newhostname>in the command is the new name of Master node server, the new name supports customization.(3) Enter the directory /etc/kubernetes/manifests:
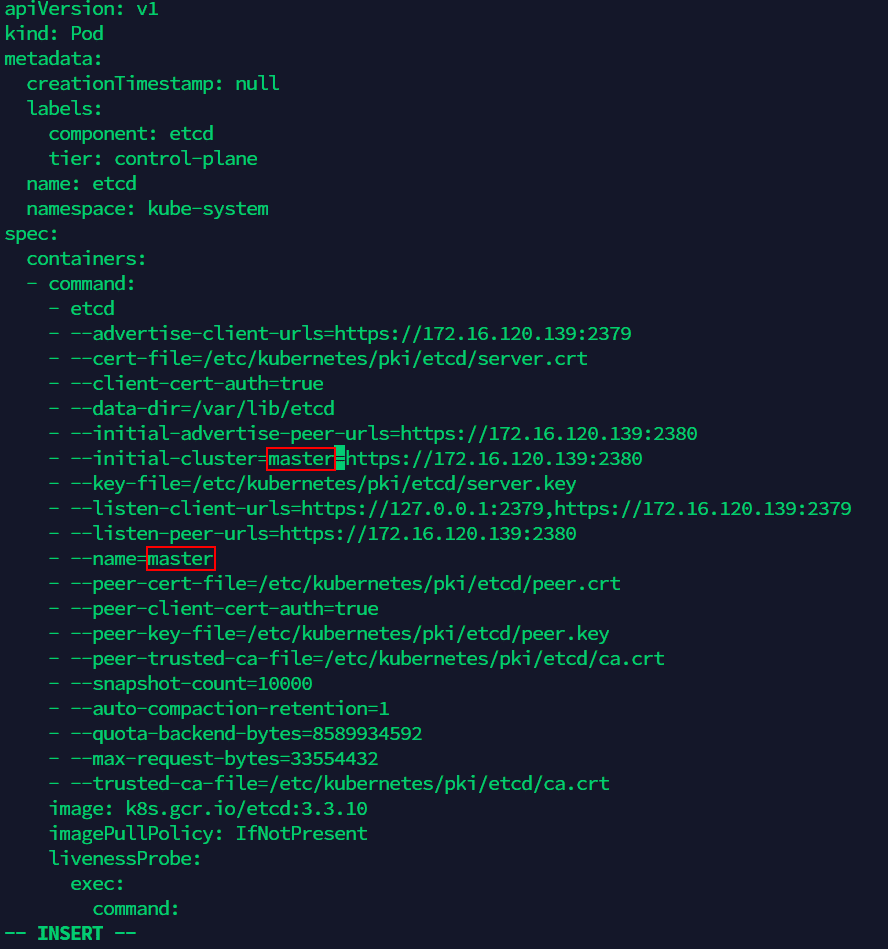
cd /etc/kubernetes/manifests(4) Edit the file ‘etcd.yaml’, modify the old name of Master node server in the file to the new name(as the screenshot below, there are two places to modify). Execute the command to edit ‘etcd.yaml’ file:
vi etcd.yaml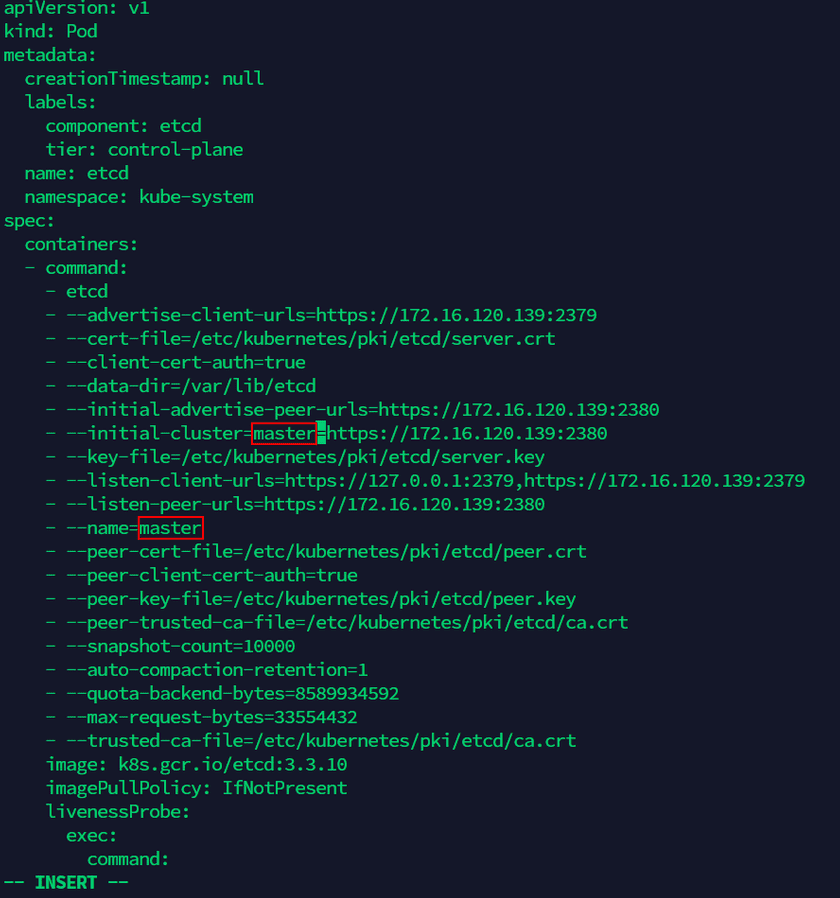
(5) Export the YAML file of Worker node server:
kubectl get node <old-nodeName> -o yaml > node.yamlNotes:
<old-nodeName>in the commmand is the name of the Worker node server, you can check the name by the command in sttep (1).(6) Edit ‘node.yaml’ file, modify the name of Worker node server in the file to the new name of Master node server, and add the content
node-role.kubernetes.io/master: ""inlabels(as the screenshot below: there are four places to modify, and add the content under the red line):vi node.yaml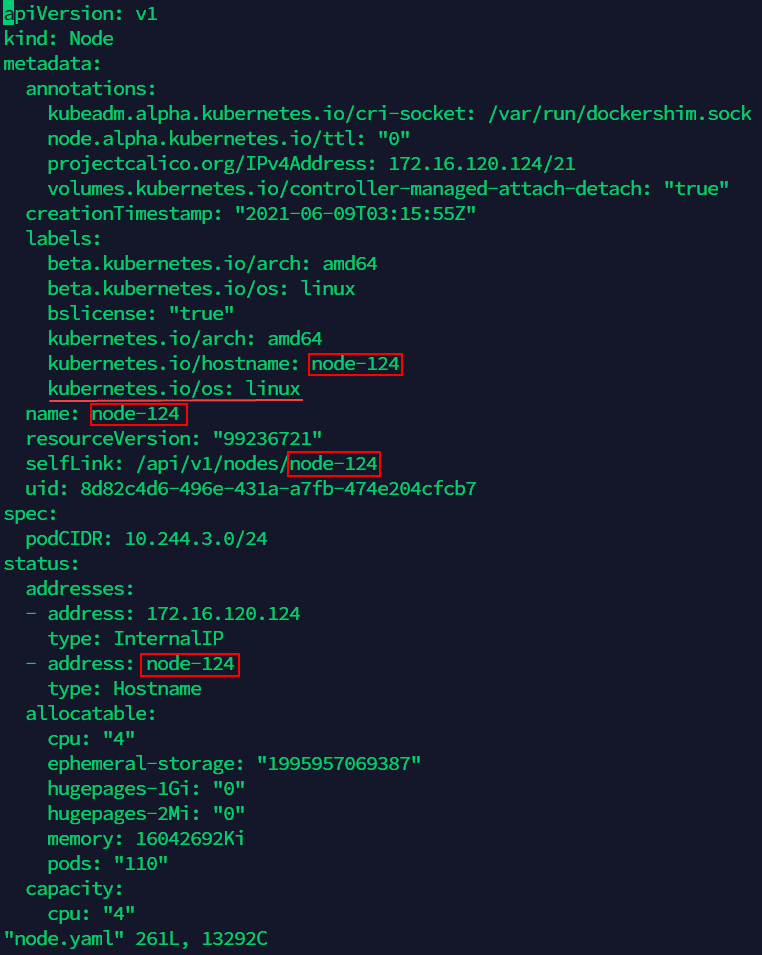
(7) Edit ‘kubeadm-config ConfigMap’ in the namespace of kube-system, modify the old name of Master node server to the new name(as the screenshot below, there is only one place to modify):
kubectl -n kube-system edit configmap kubeadm-config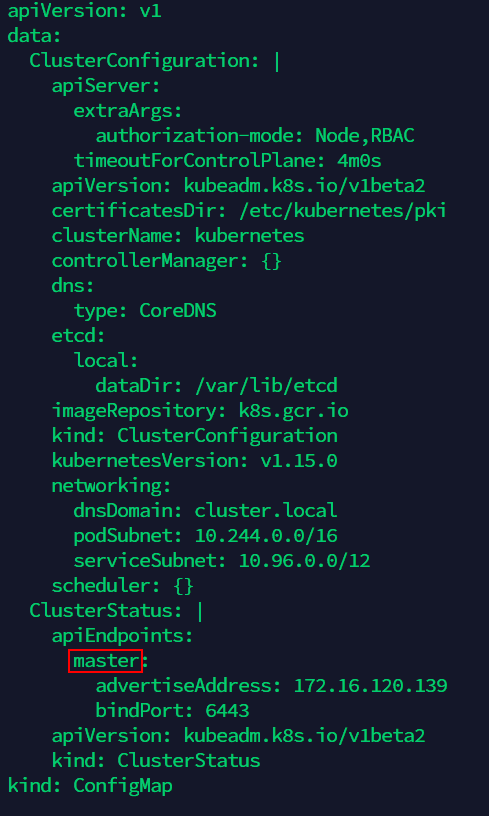
(8)Generate certificate for new server, replace the old certificate. Execute the following operation:
cd /etc/kubernetes/pki/ mkdir -p ~/tmp/BACKUP_etc_kubernetes_pki/etcd/ mv apiserver.crt apiserver-etcd-client.key apiserver-kubelet-client.crt front-proxy-ca.crt front-proxy-client.crt front-proxy-client.key front-proxy-ca.key apiserver-kubelet-client.key apiserver.key apiserver-etcd-client.crt ~/tmp/BACKUP_etc_kubernetes_pki/. mv etcd/healthcheck-client.* etcd/peer.* etcd/server.* ~/tmp/BACKUP_etc_kubernetes_pki/etcd/ kubeadm init phase certs all cd /etc/kubernetes mkdir -p ~/tmp/BACKUP_etc_kubernetes mv admin.conf controller-manager.conf kubelet.conf scheduler.conf ~/tmp/BACKUP_etc_kubernetes/. kubeadm init phase kubeconfig all mkdir -p ~/tmp/BACKUP_home_.kube cp -r ~/.kube/* ~/tmp/BACKUP_home_.kube/. cp -i /etc/kubernetes/admin.conf $HOME/.kube/config(9) Apply the ‘node.yaml’ file of Worker node server which is modified in step (6):
kubectl apply -f node.yaml(10) Delete the old Worker node server:
kubectl delete node <old-nodeName>(11) Restart kubelet and docker services:
systemctl daemon-reload && systemctl restart kubelet && systemctl restart docker