



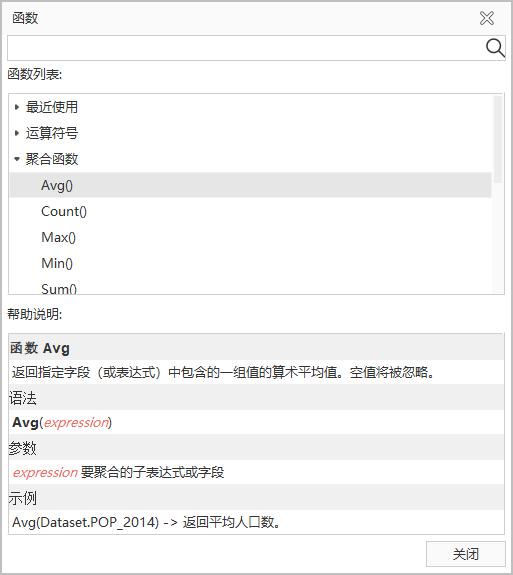
构建查询语句的常用函数包括聚合函数、数学函数、字符函数及日期函数等,在SQL查询对话框中,提供了函数帮助,可快速查看函数释义,选择符合需求的函数并输入到表达式中。函数帮助界面如下图:
- 搜索框:提供函数搜索框,在函数列表和帮助说明中搜索指定的字符串,并高亮显示搜索结果。
- 函数列表:以最近使用、运算符号、聚合函数、数学函数、字符函数、日期函数的分组方式提供,可根据函数类型快速定位函数。
- 帮助说明:根据函数列表中选中的函数,显示该函数的释义、使用语法、参数信息,以及给出使用示例。
在下文的所有表格中,支持的引擎列后的括号内容表示该函数在相应数据库引擎下的书写格式。例如,“√(Stddev)”表示在 OraclePlus 和 PostgreSQL 数据库中,应书写为“Stddev”。
运算符号
运算符号用于构造 SQL 查询条件,包括常用的数学运算符、逻辑运算符和一些比较特殊的运算符。
| 运算符 | 含义 | 示例 |
|---|---|---|
| 算术运算符 | ||
| + | 加法 | Dataset.RENT + Dataset.UTILITIES <= 800 |
| - | 减法 | Dataset.POP_2019 - Dataset.POP_2010 |
| * | 乘法 | Dataset.DENSITY * Dataset.AREA > 5000000 |
| / | 除法 | Dataset.VALUE / Dataset.POP = 50000 |
| \ | 取商 | Dataset.VALUE \ Dataset.POP > 100 |
| % | 取模 | Dataset.VALUE1 % Dataset.VALUE2 |
| Mod | 取模 | Dataset.VALUE1 Mod Dataset.VALUE2 |
| 比较运算符 | ||
| = | 等于 | Dataset.CODE = 100 |
| > | 大于 | Dataset.POP_2002 > 5000000 |
| < | 小于 | Dataset.INDUST_GROWTH < 0 |
| >= | 大于等于 | Dataset.RENT + Dataset.UTILITIES >= 800 |
| <= | 小于等于 | Dataset.RENT + Dataset.UTILITIES <= 800 |
| <> | 不等于 | Dataset.VALUE <> 100 |
| ! | 非,与“>”、“<”联合使用成!<(不小于)、!>(不大于) | Dataset.VALUE !> 100 |
| 逻辑运算符 | ||
| AND | 连结两个布尔型表达式并当两个表达式都为 TRUE 时返回 TRUE。 | Dataset.CODE = 100 AND Dataset.VALUE > 20000 |
| NOT | 对任何其它布尔运算符的值取反。 | NOT IsBACHELOR |
| OR | 将两个条件结合起来,如果两个布尔表达式中的一个为 TRUE,那么就为 TRUE。 | Dataset.SALES > 20000 OR Dataset.ORDERS > 20000 |
| IN | 如果操作数等于表达式列表中的一个,那么就为 TRUE。 | Dataset.PROVINCE In ("GUANGDONG","BeiJing") |
| Between | 确定一个表达式在某个范围之内,那么就为 TRUE。一般与 AND 同时使用。 | Dataset.SALES Between 4095 AND 20000 |
| Like | 确定搜索结果完全与指定的模式匹配。 | Dataset.COUNTRY Like "CANADA" |
| 其他 | ||
| Is NULL | 确定一个表达式是为 NULL,主要是文本型字段。 | Dataset.CONTINENT Is NULL |
| Is TRUE | 确定一个表达式为 True,主要是布尔型字段。 | Dataset.Value < 0 Is TRUE |
| Is FALSE | 确定一个表达式为 False,主要是布尔型字段。 | Dataset.Value > 0 Is FALSE |
| # | 匹配任意单个数字字符。 | Dataset.SmID like '1#3' |
| ´ | 用于字符型字段、日期型字段等的输入。 | Dataset.COUNTRY like '*国' |
| ˆ | 求a值的b次幂。不支持UDB/UDBX、Oracle、SQLPlus、MySQL引擎,适用于PostGIS引擎。 | Dataset.SmID > 2^3 |
| · | 用于手动输入字段信息时使用。 | Dataset.COUNTRY |
| * | 匹配任意数量的字符。可以在字符串中的任意位置使用星号 (*)。 | Dataset.COUNTRY like '*国' |
聚合函数
聚合函数是在数据库查询语言中用于对一组值执行特定计算的一类函数,其目的是将多行或多列的数据汇总成一个单一的结果值。
除了COUNT函数外,其他聚合函数都会默认忽略空值,并且不能应用于文本数据类型。
在 SuperMap iDesktopX中,聚合函数的参数一般为属性表和字段名,如Avg(Dataset.POP_2014),“Dataset.POP_2014”表示属性表的名称为“Dataset”,字段名称为“POP_2014”。
若需要在SQL查询对话框中使用聚合函数,请直接在结果保留字段中填写表达式,比如需要查询“SmArea”字段的最大值,则直接在结果保留字段中填写“Max(SmArea)”。
| 聚合函数 | 中文名称 | 含义 | 支持的引擎 | 示例 | |||
| UDB/UDBX | OraclePlus | SQLPlus | PostgreSQL | ||||
| Avg | 平均值(均值) | AVG(expression)返回在查询的指定字段(或表达式)中包含的一组值的算术平均值。空值将被忽略。 | √ | √ | √ | √ | Avg(Dataset.POP_2014) |
| Count | 计数 | COUNT(expression)返回各组中的记录数。 | √ | √ | √ | √ | Count(*) |
| Max | 最大值 | Max(expression)返回在查询的指定字段(或表达式)内所包含的一组值的最大值。 | √ | √ | √ | √ | Max(Dataset.POP_2014) |
| Min | 最小值 | Min(expression)返回在查询的指定字段(或表达式)内所包含的一组值的最小值。 | √ | √ | √ | √ | Min(Dataset.POP_2014) |
| Sum | 求和(总和) | Sum(expression)返回在查询的指定字段(或表达式)中所包含的一组值的总计。 | √ | √ | √ | √ | Sum(Dataset.POP_2014) |
| Stdev | 样本标准差(标准差) | Stdev(expression)返回以查询的指定字段(或表达式)中包含的一组值作为总体样本抽样的标准偏差的估计值。对于 Orcale 数据源,其函数名称为 STDDEV。 | √ | √(Stddev) | √ | √(Stddev) | Stdev(Dataset.POP_2014) |
| Stdevp | 总体标准差 | Stdevp(expression)返回以查询的指定字段(或表达式)中包含的一组值作为总体样本的标准偏差的估计值。 | × | √(Stddev_pop) | √ | √(Stddev_pop) | Stdevp(Dataset.POP_2014) |
| Var | 样本方差(方差) | Var(expression)返回以查询的指定字段(或表达式)中包含的一组值作为总体样本抽样的方差的估计值。对于 Orcale 数据源,其函数名称为 VARIANCE。 | √ | √(Variance) | √ | √(Variance) | Var(Dataset.POP_2014) |
| Varp | 总体方差 | Varp(expression)返回以查询的指定字段(或表达式)中包含的一组值作为总体样本的方差的估计值。 | × | √(Var_pop) | √ | √(Var_pop) | Varp(Dataset.POP_2014) |
数学函数
数学函数通过输入一个或多个参数,并返回一个经过特定数学运算处理的结果。
在 SuperMap iDesktopX 中的表达式一般采用属性表的字段名,如 Cos(Slope),“Slope”表示字段名。
| 数学函数 | 含义 | 支持的引擎 | 示例 | |||
| UDB/UDBX | OraclePlus | SQLPlus | PostgreSQL | |||
| Abs |
返回指定数字的绝对值,类型与指定数据类型相同。 适用于短整型、长整型、单精度、双精度、货币等类型字段(或表达式)。 |
√ | √ | √ | √ | Abs(Dataset.Temperature) |
| Acos |
返回以弧度表示的角度值,取值范围从-π到π,该角度值的余弦为给定的 float 表达式。 适用于单精度或双精度类型字段(或表达式),表达式的取值范围从-1到1,否则查询结果为空。 |
√ | √ | √ | √ | Acos(data) |
| Asin |
返回以弧度表示的角度值,取值范围从-π到π,该角度值的正弦为给定的 float 表达式。 适用于单精度或双精度类型字段(或表达式),表达式的取值范围从-1到1,否则查询结果为空。 |
√ | √ | √ | √ | Asin(data) |
| Atan | 返回以弧度表示的角度值,该角度值的正切为给定的 float 表达式。 | √ | √ | √ | √ | Atan(data) |
| Ceiling |
返回大于或等于所给数字表达式的最小整数。 适用于短整型、长整型、单精度、双精度、货币等类型字段(或表达式)。 对于 Oracle 数据源,其函数名称为 CEIL。 |
√ | √(CEIL) | √ | √ | Ceiling(data) |
| Cos | 返回给定表达式中给定角度(以弧度为单位)的三角余弦值,类型为双精度。 | √ | √ | √ | √ | Cos(Dataset.Radian) |
| cot | 返回给定 float 表达式中指定角度(以弧度为单位)的三角余切值。 | √ | √ | √ | √ | Cot(angle) |
| Degrees | 当给出以弧度为单位的角度时,返回相应的以度数为单位的角度。 | √ | × | √ | √ | Degrees(angle) |
| Exp | 返回所给的 float 表达式的以 e(约等于2.71828182845905)为底的指数值。 | √ | √ | √ | √ | Exp(data) |
| Floor | 返回小于或等于所给数学表达式的最大整数。 | √ | √ | √ | √ | Floor(23.45),Floor(-123.45) |
| Log |
返回所给数学表达式的自然对数,不适合 UDB 数据源使用。 对于 Oracle 数据源,函数格式为 Log(n,m),表示以 n 为底,m 的对数。 |
√ | √ | √ | √ | Log(Dataset.SmID),Log(n,m) |
| PI | 返回 PI 的常量值,函数输入为空。 | √ | √ | √ | PI()*Dataset.SMID as Test | |
| Power | 返回给定表达式乘指定次方的值,第一个参数指定数值型字段(或表达式),第二个参数指定次方数。 | √ | √ | √ | Power(expression,2) as Area | |
| Radians | 对于在数字表达式中输入的度数值返回弧度值,并对弧度值进行了向下取整操作。 | √ | √ | √ | √ | Radians(angle) as NewAngle |
| Rand | 返回 0 到1 之间的随机 float 值,函数输入为空。 | √ | Rand() | |||
| Round | 返回指定数值型字段(或表达式)的四舍五入到指定的小数位数的数字。第一个参数指定数值型字段(或表达式),第二个参数指定小数位数。如果没有指定小数位数时,默认四舍五入为最接近的整数。 | √ | √ | √ | √ | Round(Dataset.SmArea,2),Round(Dataset.SmArea) |
| Sign | 返回给定表达式的正负信息,包括正 (标记为+1)、零 (标记为0) 或负 (标记为-1) 号。 | √ | √ | √ | √ | Sign(data) |
| Sin | 返回给定角度(以弧度为单位)的三角正弦值,类型为双精度。 | √ | √ | √ | √ | Sin(Dataset.COLOR_MAP) |
| Square | 返回给定表达式的平方。 | × | × | √ | √ | Square(Production) |
| Sqrt | 返回给定表达式的平方根。 | √ | √ | √ | √ | Sqrt(Production) |
| Tan | 返回输入表达式的正切值。 | √ | √ | √ | √ | Tan(Dataset.COLOR_MAP) |
字符函数
字符串函数用于对字符和二进制字符串执行多种操作,并返回处理字符数据所需的值。
| 字符函数 | 含义 | 支持的引擎 | 示例 | |||||
| UDB/UDBX | OraclePlus | SQLPlus | PostgreSQL | MySQL | ||||
| ASCII | 返回字符表达式最左端字符的 ASCII 代码值。 格式:ASCII(character_expression)character_expression 为文本类型字段组成的表达式。 |
√ | √ | √ | √ | Ascii(String) | ||
| Char | 将 int 型表达式的值由 ASCII 代码转换为字符型的字符串。 格式:Char(integer_expression) integer_expression 为0~255之间整数表达式。如果整数表达式不在此范围内,将返回 NULL 值。 |
√ | √(Chr) | √ | √(Chr) | √ | Char(data) | |
| InStr | 返回字符串中指定表达式的起始位置。 格式:InSt([start_location],expr1,expr2)start_location 是在 expr1中搜索 expr2时的起始字符位置,expr1为一个字符串型表达式,其中包含要寻找的字符,expr2为一个字段串型表达式,标识要搜索的指定序列。起始字符位置不进行设置时,默认从第一个字符开始搜索。 |
× | √ | × | × | × | InStr(1,Dataset.CAPITAL,"京"),InStr(Dataset.CAPITAL,"京") | |
| Length | 返回给定字符串表达式的长度(字符个数),空格计算在内。如果字段为空,则返回值为空。 格式:Length(string_expression) string_expression 为要计算的字符串表达式。对 SQL 数据源,函数为 Len(string_expression)。 |
√ | √ | √(Len) | √ | √ | Lenth(Dataset.CAPITAL) | |
| Lower | 将大写字符数据转换为小写字符数据后返回字符表达式。 格式:Lower(character_expression) character_expression 是字符类型表达式。 |
√ | √ | √ | √ | √ | Lower(Dataset.CAPITAL) as capital | |
| Ltrim | 删除指定字段串表达式的起始空格,返回无起始空格的字符串。 格式:Ltrim(character_expression) character_exprssion 是字符类型表达式。 |
√ | √ | √ | √ | √ | Ltrim(Dataset.CAPITAL) | |
| Replace | 用第三个表达式替换第一个字符串表达式中出现的所有第二个给定字符串表达式。 格式:Replace('string_expr1','string_expr2','string_expr3') string_expr1是待搜索的字符串表达式;string_expr2是待查找的字符串表达式;string_expr3是替换用的字符串表达式。 |
√ | √ | × | × | × | Replace(Dataset.CAPITAL,"尔","而") | |
| Reverse |
返回字符表达式的反转。对Oracle 数据源查询时,中文字符可能不处理或出现乱码。 Oracle和SQLPlus中“Char”是由字符数据组成的表达式。 MySQL中“Char”可以是表达式,也可以是文本型字段。 |
× | √(中文字符会乱码) | √ | × | √ | Reverse(Dataset.CAPITAL) as NewName | |
| Rtrim | 去除字符型表达式的所有尾随空格,返回无尾随空格的字符串。 格式:Rtrim(character_expression) character_expression 是由字符数据组成的表达式。 |
√ | √ | √ | √ | √ | Rtrim(Dataset.CAPITAL) | |
| Soundex | 返回由四个字符组成的代码 (SOUNDEX) 以评估两个字符串的相似性。 格式:Soundex(character_expression) character_expression 是字符数据的字母数字表达式。 |
× | √ | √ | × | × | Soundex(word) | |
| Space | 生成由指定个数的空格组成的字符串。如果指定个数为负值,则返回空字符串。 | × | × | √ | × | × | Dataset.COUNTRY+Space(3)+Dataset.CAPITAL as World_CAPITAL | |
| Substr | 返回文本字符表达式的一部分。 格式:Substr(expression, start, length)。expression 是字符串类型的不包含聚合函数的表达式;start 是一个整数,指定子串的开始位置;length是一个整数,指定子串的长度(要返回的字符数或字节数)。 |
√ | √(文本类型不适用) | √ | √(或Substring) | Substr ( string, position, 1 ) | ||
| Unicode | 按照 Unicode 标准的定义,返回输入表达式的第一个字符的整数值。 格式:Unicode('ncharacter_expression')。 |
× | × | √ | × | × | Unicode(Dataset.CAPITAL) as Unicode | |
| Upper | 返回将小写字符数据转换为大写的字符表达式。 格式:Upper(character_expression) character_expression 是由字符数据组成的表达式。 |
√ | √ | √ | √ | √ | Upper(Dataset.CAPITAL) | |
| Left | 返回输入字符串最左边n个字符的字符串。 格式:Left(string,n),string为输入的字符串;n为整数,代表要返回的字符数。 |
× | × | × | √ | √ | Left(“Hello”,2) -> “He” | |
| Right | 返回输入字符串最右边n个字符的字符串。 格式:Right(string,n),string为输入的字符串;n为整数,代表要返回的字符数。 |
× | × | × | √ | √ | Right(“Hello”,2) -> “lo” | |
日期函数
日期函数用来查询关于日期的信息。仅日期类型字段可用。
| 日期函数 | 含义 | 支持的引擎 | 示例 | |||
| UDB/UDBX | OraclePlus | SQLPlus | MySQL | |||
| Day | 返回指定日期天部分的整数,等价于 Datepart('d',data)。适用于 SQL 数据源的日期型字段(或表达式)。 格式:Day(date) date 为日期型字段(或表达式)。 |
× | × | √ | √ | Day(Dataset.GETDATE) |
| GetDate | 按 SQL 标准格式返回当前系统的日期和时间,函数输入为空。 | × | × | √ | × | GetDate() |
| GetUtcDate | 返回表示当前 UTC 时间(格林尼治标准时间)的日期值,函数输入为空。当前的 UTC 时间得自当前的本地时间和运行 SQL Server 的计算机操作系统中的时区设置。 | × | × | √ | × | GetUtcDate() |
| Hour |
从日期中提取小时,返回指定日期的小时部分。 格式:Hour(date)date 为日期型字段(或表达式)。 |
× | × | √ | √ | Hour (“2023-05-20 14:25:33”) |
| Minute |
从日期中提取分钟,返回指定日期的分钟部分。 格式:Minute(date)date 为日期型字段(或表达式)。 |
× | × | √ | √ | Minute(“2023-05-20 14:25:33”) |
| Month | 返回指定日期月份部分的整数,等价于 DatePart("m",date)。适用于 SQL 数据源的日期型字段(或表达式)。 格式:Month(date)date 为日期型字段(或表达式)。 |
× | × | √ | √ | Month(Dataset.GETDATE) |
| Second |
从日期中提取秒,,返回指定日期的分钟部分。 格式:Second(date)date 为日期型字段(或表达式)。 |
× | × | √ | √ | Second(“2023-05-20 14:25:33”) |
| Year | 返回指定日期年份部分的整数。等价于 DatePartdate)。适用于 SQL 数据源的日期型字段(或表达式)。 格式:Year(date)date 为日期型字段(或表达式)。 |
× | × | √ | √ | Year(Dataset.GETDATE) |
| to_date | 当用户输入字符串型时间,并用此时间值构造查询条件时,需遵循一定的规则,此时需将时间值写到to_data()的括号中进行格式化。 格式:to_date(2018-5-11 14:28:00)。 |
√ | √ | × | × | Province_R.DataDate > to_date(2019-11-07 00:00:00) |
 注意事项:
注意事项:datepart 参数设置表
| 设置 | 说明 |
| yyyy | 年 |
| q | 季度 |
| m | 月 |
| y | 某年的某一天 |
| d | 天 |
| w | 工作日 |
| ww | 周 |
| h | 时 |
| n | 分 |
| s | 秒 |
相关主题