



使用说明
在没有模型的情况下,可通过训练数据生成工具,基于原始遥感影像数据和矢量标注数据,生成模型训练需要使用的训练数据。由于遥感影像数据体量较大,且卷积神经网络对于运行内存的要求较高,因此需要训练数据生成工具,将影像数据和标签数据同步切分成一张张小图片和标签,生成适合神经网络模型训练的数据。
若训练数据用途为“超分辨率重建”,则只需要输入低分辨率的样本影像,无需样本标签。
参数说明
-
训练数据用途:根据用途而定,支持选择二元分类、地物分类、目标检测、对象提取、场景分类、通用变化检测和超分辨率重建。
-
文件类型:
-
当训练数据用途为二元分类、地物分类、目标检测、对象提取、场景分类、超分辨率重建时,文件类型可选数据集和文件夹两种类型。
-
选择数据集则样本影像支持输入文件型影像数据(如*.tif、*.img等)、影像数据集和镶嵌数据集。
-
选择文件夹则需要输入影像文件夹路径。
-
-
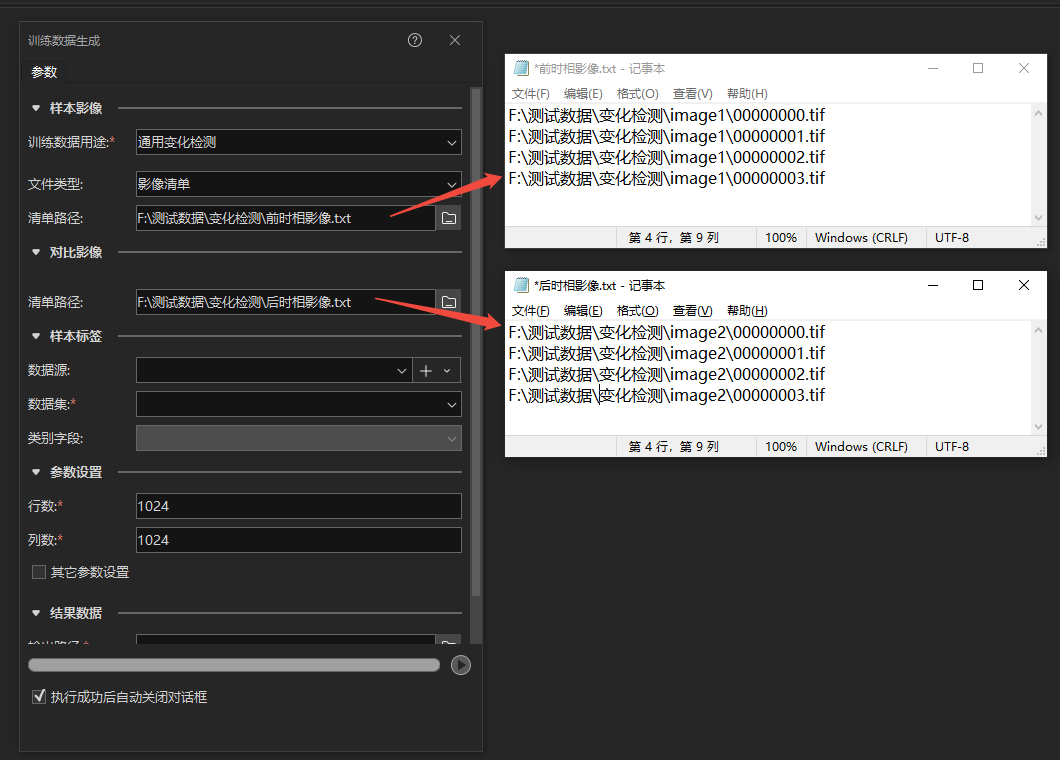
训练数据用途为通用变化检测时,文件类型可选数据集和影像清单两种类型。
-
选择数据集则样本影像和对比影像支持输入文件型影像数据(如*.tif、*.img等)和影像数据集。
-
选择影像清单路径支持txt和csv格式,清单中每一行对应一个影像文件路径,并且样本影像清单与对比影像清单中的每一行一一对应。
-
-
 注意事项:
注意事项:
-
超分辨率重建,仅支持输入三波段影像。
-
二元分类、地物分类、目标检测、对象提取、场景分类和通用变化检测支持三波段和多波段影像(含有4个及以上波段的影像)。
-
目标检测支持单波段和三波段的SAR影像数据。
-
通用变化检测输入的一对样本影像和对比影像的坐标系、分辨率必须保持一致。
-
影像名称及影像所在路径中不可包含“,”字符。
-
样本标签数据源/数据集:训练数据的矢量标签,支持udbx数据源下的矢量面数据。当训练数据用途为超分辨率重建时,该参数隐藏。
注意事项:
-
样本标签数据集的坐标系需与样本影像保持一致
-
数据源/数据集名称及其所在路径中不可包含“,”字符
-
类别字段:根据用途而定:
-
用途为目标检测时,多类目标需选择样本矢量属性表中对应的类别字段,单类目标需选择该参数为空。
-
用途为二元分类时,该参数不可填。
-
用途为地物分类时,选择样本矢量属性表中对应的类别字段。
-
用途为场景分类时,选择样本矢量属性表中对应的类别字段。
-
用途为对象提取时,多类对象需选择样本矢量属性表中对应的类别字段,单类对象需选择该参数为空。
-
用途为通用变化检测时,该参数不可填。
-
用途为超分辨率重建时,该参数隐藏。
-
-
行数/列数:设置切图的行数和列数,单元为像元(Pixel),默认值为1024px。在模型训练过程中,相同的网络结构输入的训练数据尺寸越大,其占用的内存/显存越多;相同大小的地物在不同尺寸的训练数据上的训练效果也不相同。因此,通过改变该参数,可将影像数据切分成不同大小的训练数据,以适应不同情况对训练数据的要求。基于现支持的深度学习网络结构特点,图片大小的行数和列数应相同。
-
其他参数设置:为满足用户多元化需求,勾选其他参数设置,可以自定义以下参数:
-
范围数据源/数据集:可输入与样本影像坐标系相同的面数据集,用于限制训练数据生成范围。
-
图片格式:训练数据的图片格式,支持TIFF、JPEG、PNG三种格式。
-
垂直/水平偏移:有时为了扩充训练数据并保证每个标签都可以完整的参与训练而不被切分,图片需要重叠切分,该值为重叠切分时不同方向上偏移的大小,建议设置为样本行列数的一半。样本数据量足够大时,该值推荐设置为0,即不重叠切分。
-
索引起始值:系统会对切分生成的图片进行自然数顺序编码,默认从00000000开始,如用户需要进行特殊替换,则可自行设定起始值。默认值为-1,表示如果选择的输出路径及数据名称文件夹下存在已经产生的训练数据,则默认向其中追加新生成的训练数据。若该值不为-1,则在该文件夹下从设置的起始值开始生成数据,已有的同序号数据将被覆盖。
-
保存无标签数据:勾选时可保存无标签的切片,用于补充负样本或平衡正负样本。
-
超分倍率:仅在训练数据用途为“超分辨率重建”时可见,可填2或4,以训练二倍超分模型或四倍超分模型。
-
-
输出路径:指定训练数据保存路径,注意路径中不可包含“,”字符。
-
数据名称:指定保存训练数据的文件夹名称,名称中不可包含“,”字符。如果选择的输出路径及数据名称文件夹下存在已经产生的训练数据,且索引起始值为-1,则会向其中追加新生成的训练数据。
相关主题