



使用说明
叠加分析作为 GIS 领域中的一项关键空间分析功能,其基于统一的空间参考系统,通过对两个数据集执行一系列集合运算,生成包含几何信息和属性信息的新数据集。
分布式矢量叠加分析提供了以下两种工具,适用于不同的计算需求:
1、【叠加分析】
- 支持通过连接【读取矢量数据】工具输入多种来源的矢量数据,如GDB 、ShapeFile、PostGIS、Oracle等;
2、【DSF叠加分析】
- 仅支持输入从SuperMap DSF数据源中读取的数据集,通常通过连接【读取DSF目录】工具获取输入数据。
- DSF 是一种为分布式计算优化过的矢量数据存储方式,能够显著提高大数据量的计算性能,适用于千万级及以上的大规模矢量数据叠加分析。
叠加类型
分布式矢量叠加分析支持多种运算类型:
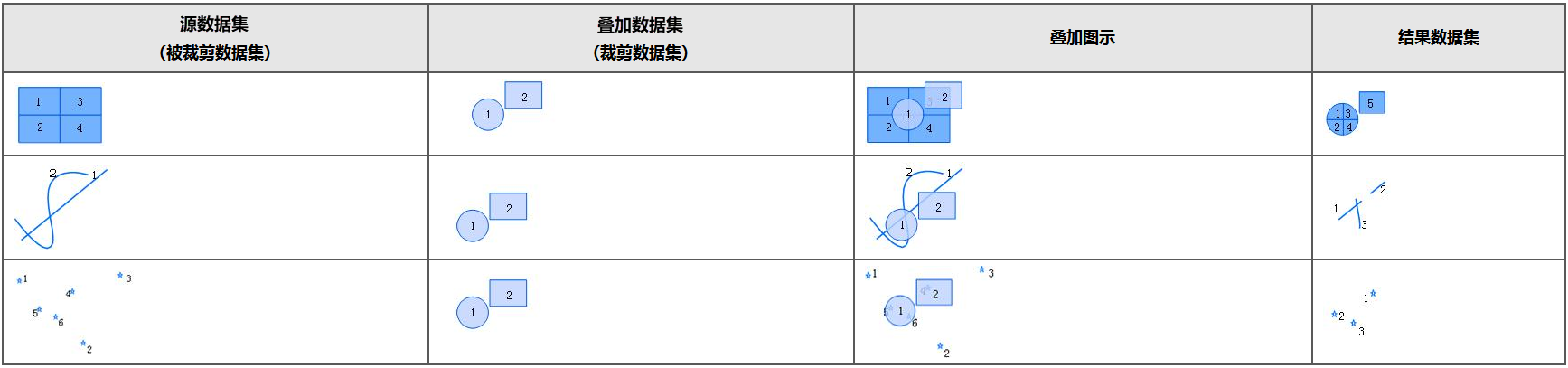
- 裁剪:从源数据集中提取被叠加数据集覆盖的部分写入结果数据集。结果数据集保留了源数据集的属性信息,但其中面积、周长、长度的属性值会被重新计算。
注意事项:
自SuperMap 11i(2024)版本起,对裁剪算法进行了优化。优化后的“裁剪运算”与“求交运算”得到的结果数据集空间几何信息不同,裁剪运算是沿叠加数据的边缘对源数据进行裁剪,有效避免源数据被叠加数据内部的几何形状所分割,最大程度的保留源数据的几何完整性。

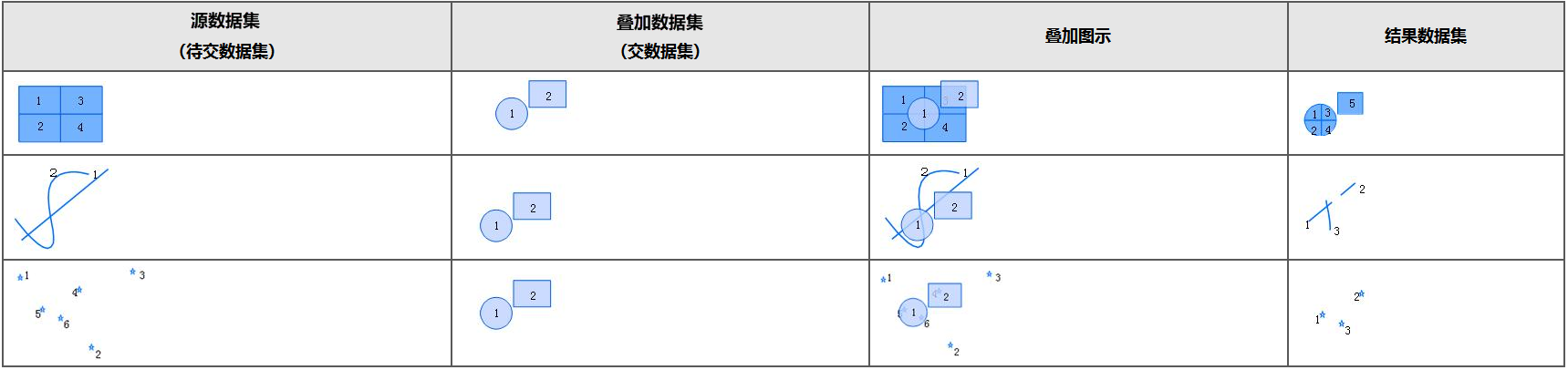
- 求交 :提取源数据集与叠加数据集相交的部分写入结果数据集。
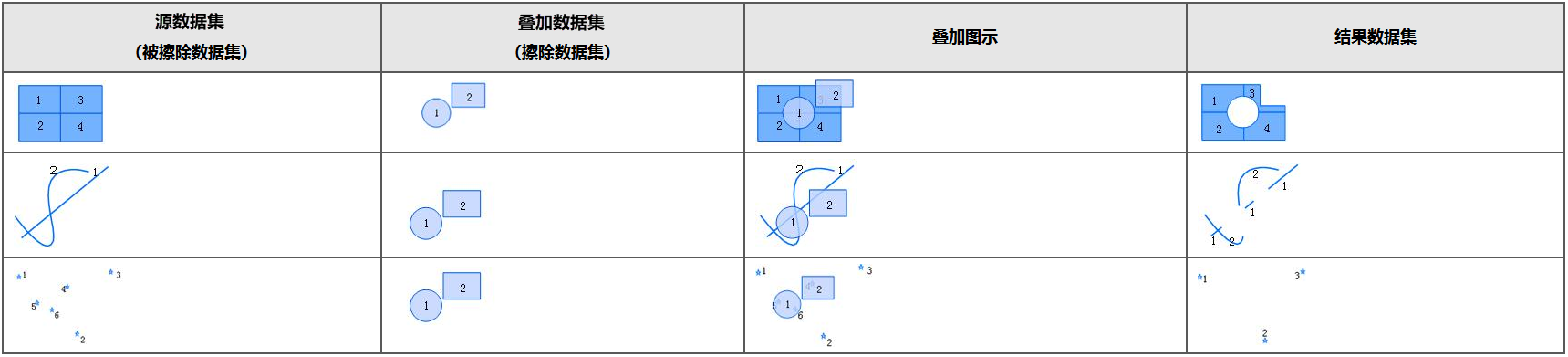
- 擦除:与裁剪运算相反,叠加数据集定义了擦除区域,源数据集中凡是在擦除区域内的对象都将被删除,而在擦除区域外的对象都将保留。
- 标识:标识运算结果图层范围与源数据的范围相同,但是包含来自叠加数据集的几何形状和属性数据。
- 更新:用叠加数据集替换与源数据集重叠的部分,结果数据集保留了更新数据集的几何信息和属性信息。

- 交集取反:对于源数据集每一个面对象,去掉其与叠加数据集中几何对象相交的部分,保留不相交的部分。

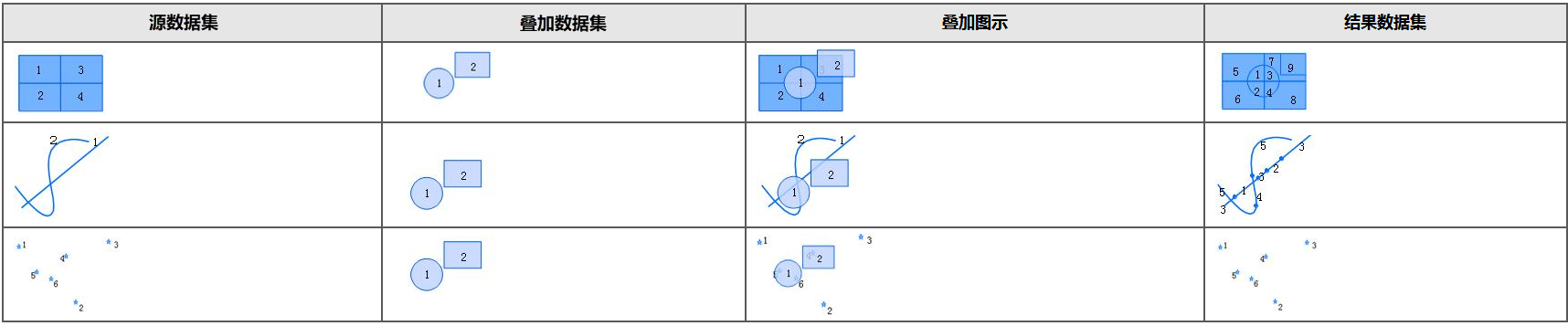
- 联合:进行联合运算后,两个面数据集相交处的多边形被分割,且两个数据集的几何形状和属性信息都会被输出到结果数据集中。

节点容限
在叠加分析的过程当中,节点容限的设置对于确保结果正确性至关重要。节点容限设定了节点捕捉的容忍程度,即当数据中两点的距离小于节点容限时,会被认为是同一个节点并进行合并节点操作;而当距离大于节点容限时,节点则保留不变。因此,数据制作的精度越高,需要设置的节点容限值就越小。然而,过小的节点容限值,会增加叠加分析所需的耗时。因此,在实际应用中,根据需要设定合适的节点容限值。
为提升工具易用性,分布式叠加分析工具对于不同坐标系的数据,提供了不同的默认容限值,能够在大多数情况下能保证数据的无损和高效计算。
- 数据集坐标系为地理坐标系时,默认节点容限值为 1.0e-8;
- 数据集坐标系为空或为投影坐标系时,默认节点容限值为 1.0e-3。
参数说明
| 参数名 | 参数释义 | 参数类型 |
|---|---|---|
| 源数据 | 输入被叠加的源数据,支持点、线、面数据集 | FeatureRDD |
| 叠加数据集 | 输入用于叠加的数据集,只支持面数据集 | FeatureRDD |
| 被叠加的源数据中需要保存的字段名称集合 (可选) |
被叠加的源数据中需要保存的字段名称集合。若源数据和叠加数据存在同名字段,结果数据集中来自源数据的字段名为“字段名_1”,来自叠加数据的字段名为“字段名_2” | String |
| 叠加数据集中保存的字段名称集合 (可选) |
叠加数据集中需要保存的字段名称集合。若源数据和叠加数据存在同名字段,结果数据集中来自源数据的字段名为“字段名_1”,来自叠加数据的字段名为“字段名_2”。需要注意的是,裁剪、擦除、更新模式无需设置该参数。 | String |
| 叠加分析运算类型 | 选择叠加分析运算类型。需要注意的是,不同运算类型对应支持不同的源数据类型: 1、裁剪、求交、擦除和标识运算,源数据支持点、线或面数据集。 2、更新、交集取反和联合运算,源数据仅支持面数据集 |
JavaSpatialOperatorType |
| 节点容限 (可选) |
默认值是 0.0,代表的是当数据集的坐标系为地理坐标系时,使用1.0e-8 的节点容限。当坐标系为空或投影坐标系时,使用 1.0e-3 的节点容限。 容限用于判定点与点的关系,点与线的关系。当点和点在容限之内,将会合并为一点,当点与线的距离在容限之内,线将会被点打断。 |
Double |
| 保持源数据重叠关系 (可选) |
默认勾选。需要注意的是,该选项仅对标识操作生效。 如果源数据为线,线在多个面对象内(面对象有重叠),勾选该参数后返回一个对象,否则返回多个对象。 如果源数据为面,当源数据和叠加数据的拓扑关系都比较复杂(比如都存在面重叠时),勾选参数后按照源数据的重叠关系进行输出。 例如,源数据和叠加数据都有两层面重叠,不勾选时输出结果对象有四层重叠,勾选时保持源数据的两层重叠。 |
Boolean |
输出结果
| 参数名 | 参数释义 | 参数类型 |
|---|---|---|
| 叠加分析结果数据集 | 分布式分析工具的计算结果存储在内存中,需要通过连接【保存矢量数据】工具,将结果数据集写出到数据库或本地。 | FeatureRDD |
应用示例
叠加分析作为一项非常重要的空间分析功能,广泛应用于自然资源管理、城市建设评估、国土空间规划等领域。例如,使用叠加分析来评估特定行政区域内土壤资源的分布与利用状况,具体步骤如下:
步骤一:数据准备
准备全国土地利用数据以及目标行政区的区划面数据,并确保两个数据的坐标系一致。
步骤二:构建模型进行叠加分析
1、输入数据:通过【读取矢量数据】工具输入全国土地利用数据和行政区划面数据,并将其分别作为“源数据”和“叠加数据”连接到【叠加分析】工具的输入参数;
2、参数配置:在【叠加分析】工具参数中,选择“求交”作为运算类型,这表示将生成一个新的数据集包含源数据与叠加数据集相交的区域,并保留两个数据集的全部属性信息。由于数据采用地理坐标系,默认使用1.0e-8节点容限足以保证计算结果的精确性,无需调整容限值;
3、结果保存:通过连接【保存矢量数据】工具,将叠加分析结果保存到指定的数据库或本地文件夹中,当模型执行完成后即可查看叠加分析结果数据。
注意事项
一. 字段大小写转换
使用此工具时,请注意,输入数据中的所有大写字段会自动转换为小写,并反映在输出结果数据中。因此,如果您在数据处理中发现结果不符合预期,可能是因为字段大小写转换导致的问题,请检查您的输入数据和分析结果,确认字段大小写的一致性。
二. 功能变更
自SuperMap 2025(12.0.1)版本起,支持不同坐标系的数据叠加分析。目前不支持设置坐标系转换参数,当源数据和目标数据基于不同的椭球体(例如,将基于 Krasovsky_1940 椭球的 Beijing_1954 坐标系,转换到基于WGS_1984椭球的坐标系)时,转换结果可能不准确,导致图层之间出现偏移。
自 SuperMap 2025(12.0.1)版本起,叠加分析工具进行算法升级,主要包括以下方面:
新算法具备更强的几何容错能力,可直接处理输入数据中的几何错误,包括:悬线、零长线段、共点共线、点序走向不一致及自相交的问题。-
通过设置容限,可更精确地控制计算误差,有效避免因容限配置不当或数据质量问题引发的错误,显著提升算法的稳定性与输出结果的准确性。
如需启用新算法,请修改以下配置文件中的相应配置项:
在【iDesktopX产品目录】\bin\SuperMap.xml 配置文件中,将 IsUseNewAnalysisAlgorithm 设为“TRUE”。
在【iServer产品目录】\support\objectsjava\bin\SuperMap.xml 配置文件中,将 IsUseNewAnalysisAlgorithm 设为“TRUE”。