



数据血缘的保存与应用
使用说明
数据血缘是指数据在产生、处理、流转的消亡过程中,数据之间形成的一种类似于人类社会血缘关系的关系,是数据治理中的一个概念,简单来说是表达数据是怎么来的,以及数据经过了哪些处理分析过程。知识图谱为数据血缘的提取、存储、查询、可视化提供方案。
SuperMap提供将处理自动化(GPA)执行过程的数据血缘关系写入图数据库,通过构建的数据图谱可以直观展示数据处理流转过程,并提供对数据集进行向上溯源和向下追踪的能力。
- 对需要查询的数据集进行向上溯源,可获取其生产链路,当该数据出现质量问题时,可帮助解释来源,定位原因。
- 对需要查询的数据集进行向下追踪,可获得该数据的后续影响情况。
将处理自动化的数据血缘保存至图数据库,即处理自动化工具、数据集以及属性作为图谱实体,数据的处理过程作为图谱关系。如下图所示,输入数据集为降水量数据,经过更新列处理,得到新的降水量数据集,其中图谱节点为输入和输出数据,以及GPA工具,关系为input(输入)和output(输出)。

操作步骤
- 启用数据血缘:
- 处理自动化选项卡->数据血缘->:保存数据血缘,启用后可将执行流程写入到图数据库中。
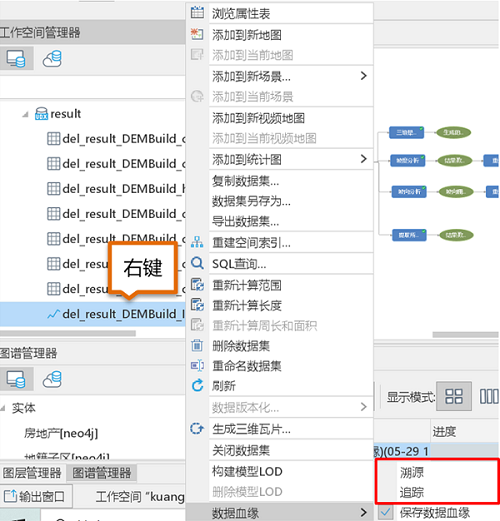
- 直接在工作空间管理器中选择数据集->右键->数据血缘->保存数据血缘。
- 勾选保存数据血缘后若没有连接图数据库,需要先进行连接,才能进行数据血缘的保存和应用。
- 执行处理自动化(GPA)模型。
- 对执行的结果数据集进行血缘的查询或探索:
- 知识图谱选项卡->图谱查询,可使用cypher查询。
- 直接在工作空间管理器中选择数据集->右键->数据血缘->溯源/追踪。
- 打开数据血缘的图谱后,可在图谱窗口点击数据实体的节点属性,包含有数据地址、记录数、坐标、范围、执行时间等属性,通过链路中的数据属性变化可以辅助探索数据的变化情况。