拆分
使用说明
拆分是指根据指定字段的属性值,将源数据集中的几何对象分组,并为每个分组生成一个新的结果数据集或独立数据源。该功能可高效地将一个包含多种类别的大数据集按业务属性拆分为多个独立的数据集,便于分类管理、分发或专题应用。
应用场景
-
根据行政区划代码拆分数据,用于分区域统计制图。
-
根据图幅编号划分数据,便于按图幅范围分发。
-
根据机构类型拆分全国文化教育机构点数据,分类存储以提升管理效率。
功能条件说明
-
拆分字段不支持二进制、字节类型。
-
若拆分字段的唯一值过多,可能生成大量结果数据集,请注意存储容量。
-
多文件输出时,输出路径需存在且有写入权限。
参数说明
| 参数名 | 参数释义 | 参数类型 |
|---|---|---|
| 源数据源 | 指定需要进行拆分的数据集所在的数据源。 | DatasetSource |
| 源数据集 | 指定需要进行拆分的数据集。 | DatasetVector |
| 拆分字段 | 指定用于拆分的字段。系统将根据该字段的属性值对数据进行分组。不支持二进制、字节类型。 | String |
| 过滤表达式 | 输入 SQL 表达式,仅拆分符合条件的数据。若为空,则表示所有记录都会按拆分字段进行拆分。例如,只拆分北京市的数据,输入:所属省 = '北京市'。 | String |
| 输出方式 | 指定结果数据的存储结构。提供两个选项:
|
ExportTypeEnum |
| 结果数据源 | 当输出方式为单文件时可用。
指定用于存储所有拆分结果数据集的目标数据源。 |
Datasource |
| 输出格式 | 当输出方式为多文件时可用。
指定结果数据源的格式。默认为UDBX,另外提供UDB和FileGDB两个选项。 |
EngineType |
| 输出路径 | 当输出方式为多文件时可用。
指定存放结果数据源的文件夹路径,系统将在该文件夹下按结果名称命名规则创建多个数据源。 |
String |
| 结果名称 | 指定用于命名拆分结果的字段。
|
String |
输出结果
- 单文件:所有拆分结果数据集存入指定的目标数据源,可在工作空间管理器中立即查看。
- 多文件:每个拆分结果单独存为一个数据源,保存在输出路径指定的文件夹中(可通过输出窗口快速打开文件夹)。若需浏览结果数据,可按需将这些数据源添加到工作空间管理器进行查看。
应用示例
案例说明
在处理全国文化教育机构数据时,原始数据 CultureService_p 点数据集包含了学校、图书馆、博物馆等多种类型的机构,所有数据混杂在同一个数据集中,不利于按类别进行专题制图、统计分析或数据分发。通过数据集拆分功能,可以按Type字段(机构类型)快速将数据拆分为多个独立数据集,实现分类存储和管理。
数据说明
- 数据源:示例数据包 SampleData\AnalyticalMap\HeatMap\heatMap.udbx 数据源。
- 数据集:CultureService_P 点数据集,包含全国文化教育机构的点位信息。
- 关键字段:
- Name:机构名称(如“北京大学”、“国家图书馆”)。
- Type:机构类型(如“中学”、“图书馆”、“博物馆”),将作为拆分字段。
主要操作步骤
- 在工作空间管理器中,打开heatMap.udbx数据源。
- 单击数据选项卡 ->数据处理组的Gallery下拉菜单 ->矢量分组 ->拆分按钮,打开拆分对话框。
- 在源数据分组中设置待拆分数据:
- 数据源:选择heatMap数据源。
- 数据集:选择CultureService_P数据集。
- 拆分字段:选择Type字段。
- 在结果数据分组中配置输出参数:
- 输出方式:保持默认选项,即单文件。
- 数据源:选择heatMap数据源。
- 结果名称:保持为空,即直接使用拆分字段值命名结果数据集。
- 单击执行,完成拆分。
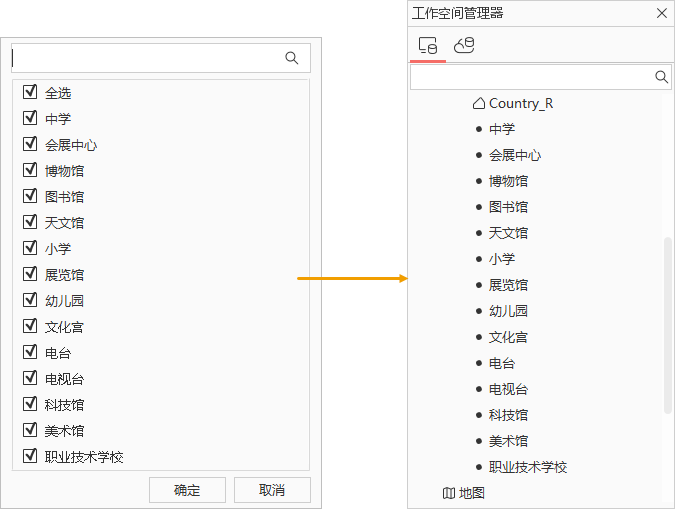
结果展示
拆分完成后,在heatMap数据源下自动生成多个数据集,数据集名称即为Type字段的各个唯一值,如“中学”、“博物馆”、“文化宫”等。