迭代循环,是指自动地重复某个过程。迭代循环主要用于需要自动执行重复任务的情况,相比于手动执行重复任务,迭代循环能够极大节省执行任务所需的时间和精力。迭代循环分为两种模式,分别是配对循环和嵌套循环。默认模式为配对循环。
- 配对循环:即对集合数据中的每个数据按顺序进行一对一的匹配。需要注意的是,当元素的个数分别为 m,n 个时,执行的次数为 m,n 中的最小值。即 m>n 时,循环只会执行 n 次。
- 嵌套循环:即对集合数据中的每个数据进行交叉循环匹配。
使用说明
1.将集合数据集连接到单值输入上。
2.鼠标右键工具节点-迭代模式-配对循环/嵌套循环。
3.需要注意的是,迭代循坏只有在多重循环下使用,才会有意义。
4.迭代循环只有在单值输入的情况下使用,才具有意义,否则不能得出正确的迭代结果。
使用场景一:迭代数据集批量处理
当数据源中的数据集数量非常大时,可以使用迭代数据集对数据进行批量处理。对迭代数据集进行迭代循环时,可根据实际情况,选择迭代模式,实现迭代批处理。
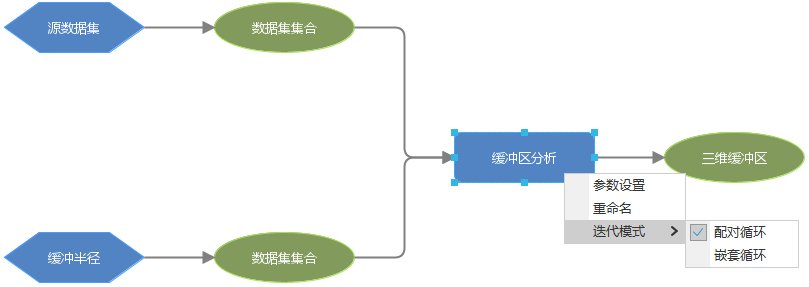
在下方模型中,需要对迭代数据集进行缓冲区分析,当两个迭代数据集连接在缓冲区分析工具节点时,即可选择迭代模式,之后模型运行时就可以对两个迭代数据集进行配对循环/嵌套循环。
使用场景二:集合型变量批量处理
变量支持创建集合数据,可批量设置多个数据。同时集合型变量支持跨数据源选择数据,通过使用迭代循环,可以实现批处理。例如,对某区域的三个数据分别进行缓冲区分析,具体操作步骤如下:
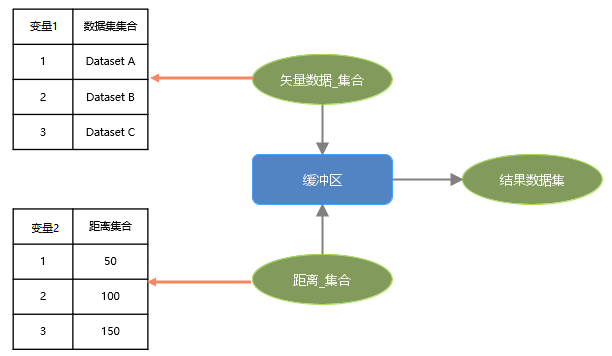
创建集合型变量:点击"处理自动化"选项卡,选择"变量"组,下拉菜单中将显示可在模型中使用的所有数据类型的列表。双击矢量数据集类型的变量,勾选集合选项,则可在属性面板通过“添加”按钮,添加三个矢量数据集。接着,创建整型变量并添加缓冲距离,分别设置50、100、150 三个距离。在画布中构建得到如下模型:
选中【缓冲区】工具节点,通过右键菜单可以选择配对/嵌套循环。两种循环模式的区别如下:
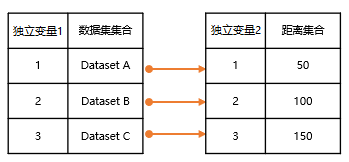
配对循环。如下图所示,按照数据对应关系,Dataset A 对应距离 50;Dataset B 对应距离 100;Dataset C 对应距离 150 分别进行缓冲区分析,最终得到三个结果。
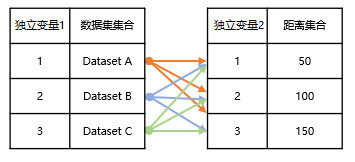
嵌套循环。如下图所示,Dataset A 按照 50、100、150 做三次分析、同理 Dataset B、Dataset C 也分别会按照三个距离做分析,最终得到九个结果。
使用场景三: 数据集批量处理
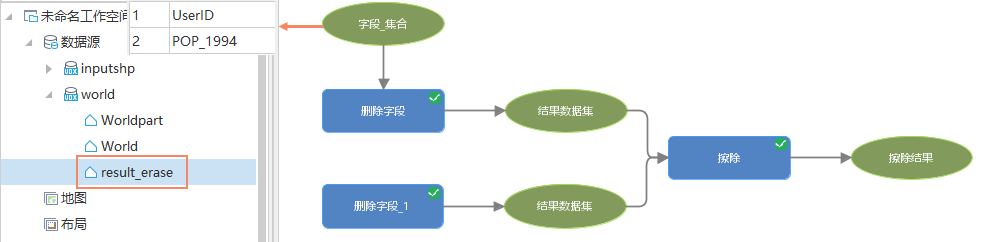
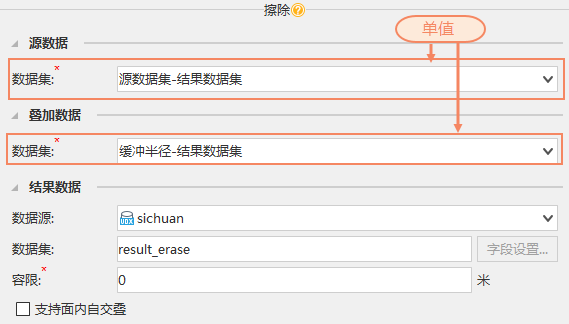
对源数据进行批量处理,有时只需要输出一个结果数据集。例如,批量删除World数据集中的UserID和POP_1994字段,再将Worldpart数据集从World数据中擦除。
按照嵌套循环的原理,由于【字段_集合】中填了两个值,因此【擦除】会执行两次生成两个结果数据集 result_erase 和 result_erase_1。这两个数据集相同,因此默认对计算结果进行智能去重,最终得到一个结果数据集result_erase,避免了资源浪费。