



Feature Description
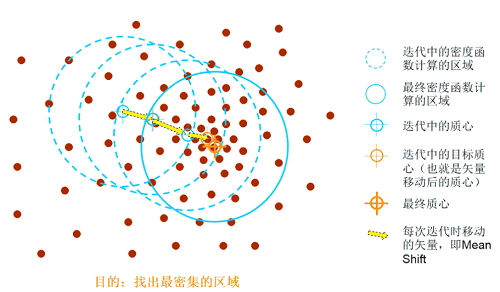
Mean Shift (Means Shift algorithm) is a clustering algorithm based on iterative solution of cluster centers. Unlike K-means clustering, it does not require pre-determining the number of clusters K. The principle of mean shift clustering is: starting from the initial cluster center points, it continuously searches for new cluster center points along the direction of increasing point density within the bandwidth until the termination conditions are met. The termination conditions are that the moving distance between the centers of two consecutive clusters during iteration is almost unchanged or the maximum number of iterations is reached (default iterations: 300).
Parameter Description
| Parameter Name | Default Value | Parameter Interpretation | Parameter Type |
|---|---|---|---|
| Source Dataset | Sets the vector dataset to be analyzed, supporting point datasets. | DatasetVector | |
| Target Datasource | Specifies the datasource where the resulting dataset is stored. | Datasource | |
| The Name Of The Resulting Dataset | Specifies the name of the resulting dataset. | String | |
| Bandwidth | -1 | The bandwidth value is the search radius when taking a cluster center point as the core. The unit is consistent with the coordinate system, and the value should be greater than 0. The default value is -1, and the system will automatically calculate a default bandwidth value. The aggregate result is affected by the bandwidth. If the bandwidth is set too small, convergence is slower, and the number of clusters is excessive; if the bandwidth is set too large, some clusters may be lost. | double |
| Custom Initial Cluster Center Seed Points | Custom initial cluster centers. By default, it is not set. The filling form is [{"x":0.0,"y":0.0},{"x":9.0,"y":9.0}]. | Point2Ds |
Output Result
1. A Cluster_ID field is added to the source dataset to indicate the result cluster categories;
2. The result vector dataset represents the cluster center points of the final clustering.