



Feature Description
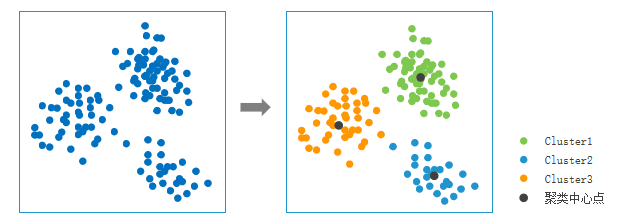
The k-means clustering algorithm is an iterative clustering analysis algorithm. Its principle is to pre-divide data into K groups, select K objects as initial cluster centers, and then assign each object to the nearest initial cluster center. A cluster center and the objects assigned to it represent a cluster. Each time a sample is assigned, the cluster center is updated. This process repeats until the desired result is achieved. Iteration termination conditions can be that no object is reassigned to a different cluster, no cluster center changes further, or the maximum number of iterations (default iterations: 300) is reached.
The k-means method is sensitive to outliers. Therefore, anomalies/outliers can be removed before analysis; otherwise, they may affect the aggregate result.
Application Scenarios:
- Distribution center site selection, e.g., a supply chain needs to add distribution centers to meet business needs. After determining the number of distribution centers based on cost, site selection is required to ensure that each supply point can be assigned to the nearest distribution center.
- Multi-point task assignment, e.g., direct sales personnel need to visit retail supermarkets. How to reasonably assign multiple supermarkets to N direct sales personnel? K Means analysis can be used to cluster supermarkets with similar geographical locations into one group, with each salesperson corresponding to a cluster.
Clustering analysis is an exploratory analysis. Its results may not directly solve the problem but can provide guidance.
Parameter Description
| Parameter Name | Default Value | Parameter Interpretation | Parameter Type |
|---|---|---|---|
| Source Dataset | Set the vector dataset to be analyzed. Supports point datasets. | DatasetVector | |
| Target Datasource | Specifies the datasource where the resulting dataset will be stored. | Datasource | |
| Result Dataset Name | Specifies the name of the resulting dataset. | String | |
| Number of Clusters | 1 | The number of clusters is the desired number of groups to obtain through clustering. Generally, a suitable K value is chosen based on prior knowledge of the data, or multiple attempts are made to select the optimal number. The default value is 1. | int |
Output Result
1. A "Cluster_ID" field is added to the source dataset to represent the resulting cluster category;
2. The resulting vector dataset represents the final K cluster center points.