



Instructions for Use
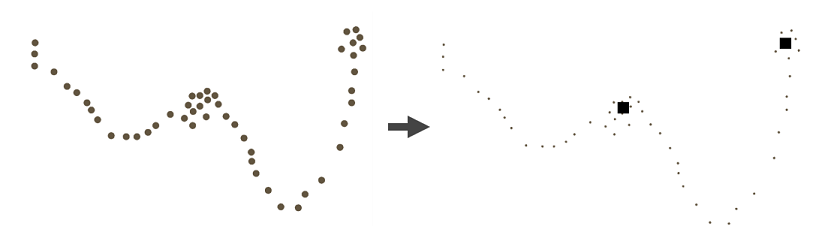
Resident analysis is the clustering of spatial dimensions on point datasets containing temporal information using density clustering (DBSCAN) algorithms or square grids. Density clustering requires a threshold of points greater than 1. When using density clustering, isolated points (noise points) that do not belong to any class may be generated, and each isolated point will be treated as a separate point cluster when calculating the residence point. The result returns a point dataset that retains the value of the point identification field and the sum of the time interval values. The returned result type is Feature Dataset (FeatureRDD). The following is a schematic diagram of residence analysis: !
{kind=link}
Analysis principle
The basic principle of square grid clustering is based on a grid aggregation algorithm, which divides map point elements into grids. Then, the number of point elements within each grid unit is calculated and used as the statistical value of the grid. The weight information of points can also be introduced, and the weighted value of points within the grid unit is considered as the statistical value of the grid. The density clustering method DBSCAN can divide areas with sufficient high density into clusters and discover clusters of any shape in noisy spatial data. It defines a cluster as the maximum set of points connected by density. DBSCAN uses point count threshold and clustering radius (e) to control cluster generation. The area within the radius of a given object is called the e-neighborhood of the object. If an object's e-neighborhood contains at least the minimum number of MinPtS objects, it is called a core object. Given a set of objects D, if P is within the e neighborhood of Q and Q is a core object, we say that object P is directly density reachable starting from object Q. DBSCAN searches for clusters by examining the e-domain of each point in the data. If the e-domain of a point P contains more than MinPts points, a new cluster is created with P as the core object. Then, DBSCAN repeatedly searches for objects directly reachable from these core objects and adds them to the cluster until no new points can be added.
Application Scenario
*Calculate a large amount of mobile signaling data, including user ID, time, location, and other information, and analyze the K locations where each user has the longest residence time.
Parameter Description
| Parameter Name | Default Value | Parameter Definition | Parameter Type |
|---|---|---|---|
| Original Point Dataset | Original Point Dataset | FeatureRDD | |
| Point identification field | Point identification field, where points with the same identification are grouped together, for example, phone number | String | |
| Field used to identify element time | Field used to identify element time. If the time field is not set, the default time field will be found from the element dataset. If there is no default time field, an exception will be thrown | String | |
| Number of permanent positions | 0 | Take maxTop permanent positions for the same identification point | Integer |
| Density clustering radius | If a threshold of density clustering points is set and the threshold is greater than 1, spatial clustering uses density clustering (DBSCAN), which represents the density clustering radius. Otherwise, square grid clustering is used, which represents the width of the grid. Example of filling: 30.0 Meter | JavaDistance | |
| Density clustering point count threshold | 0 | If spatial clustering requires the use of density clustering, this parameter needs to be set to be greater than or equal to 2, indicating the minimum number of density clustering points threshold. If the number of points threshold is less than 2, spatial clustering will use square grid clustering | Integer |
| Time weight (Optional) |
Time weight, where each item of the time weight value corresponds to the weight value of the time period (without dates). For example, for the period from 8:00 to 9:59:59, the time weight can be set to 1. From 10:00 to 12:00, a weight value of 2 can be set, so that when calculating, for the time length belonging to the specified time interval, the time weight value will be multiplied as the basis for selecting the longest dwell time. The weight value is 1 when it is not within the specified time weight interval. If the specified time weight interval overlaps, the value with the highest weight value will be taken as the weight value for this time interval. For example, if the weight from 8:00 to 10:00 is 1, and the weight from 9:00 to 12:00 is 10, then the weight from 9:00 to 10:00 is 10, and the weight from 8:59:59 is 1. Set the format as "08:00:00,09:59:59,10" | JavaLocalTimeWeight | |
| The type of result returned by the dwell point | includes returning the average center, convex hull, and all dwell points | JavaStayLocationResultType |