



In the model builder, the substitution of inline variables is expressed by enclosing them with a percentage sign (% * *%). Substitution of inline variables can replace parts of the input parameters. Flexibly using inline variable substitution during model construction can greatly reduce our workload, achieve standardized data processing, and achieve higher model reuse rates. At the same time, after selecting the corresponding inline variable replacement, you can also enter '#' to automatically display the list of available attributes. Selecting the desired attributes constitutes the complete inline variable replacement.
Various usage methods for replacing inline variables
A complete inline variable replacement needs to be enclosed in '%'. Enter '%' in the text box to automatically display the list of parameters that can be referenced.
Depending on the specific situation, after selecting the corresponding variable replacement in the row, you can also enter '#' to automatically display the available specific attributes.
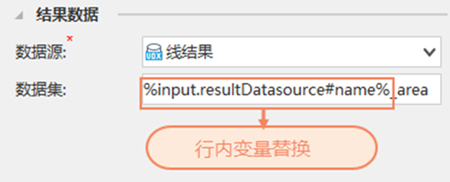
In line variable substitution can be used in all text boxes of the tool parameter interface, such as result data names, SQL query statements, etc.
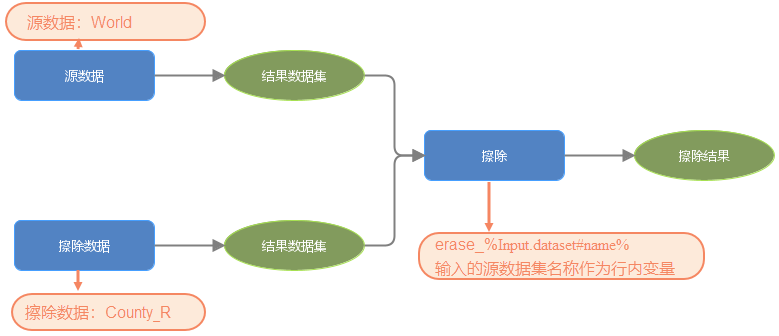
In line variable replacement supports adding strings before and after string variables to form a new string. In the following model, use inline variables to replace the naming of the Result Dataset for erasure analysis Input. dataset% refers to the source dataset, # name refers to the name, and the combination of% input. dataset # name% represents the name of the source dataset. The source dataset is named 'World', therefore, during model execution,% input. dataset # name% will be used to replace 'World', and the string '_' will be used to output the Target Dataset Name as' erase_World '.
- In line variable substitution supports the use of four arithmetic operations before and after numerical variables to generate new numerical values. For example, when calculating the segmentation of a certain area, you can refer to the following model. This model contains two variables, namely Area 1 and Area 2, both of which are of the double precision type. When running the area segmentation tool, the variable Name will be replaced with the specified value, Area 1 will be replaced with "4", Area 2 will be replaced with "10", and the final area size of the area segmentation will be the value "14" after adding these two values.
Typical usage scenarios include:
- By combining inline variables with variables, variables can be applied as global variables to different tools in the model.
- The combination of inline variable replacement and iterative tools can standardize the data names of batch processing results, making the data results traceable.
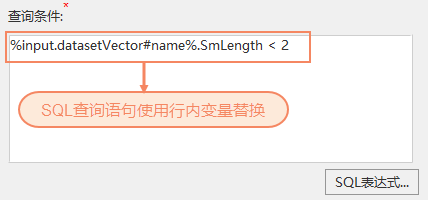
- In line variable substitution is used in SQL query statements, which eliminates the need to frequently modify SQL statements when input data changes, resulting in higher model reuse rates.
Scenario 1: Using variables as global variables
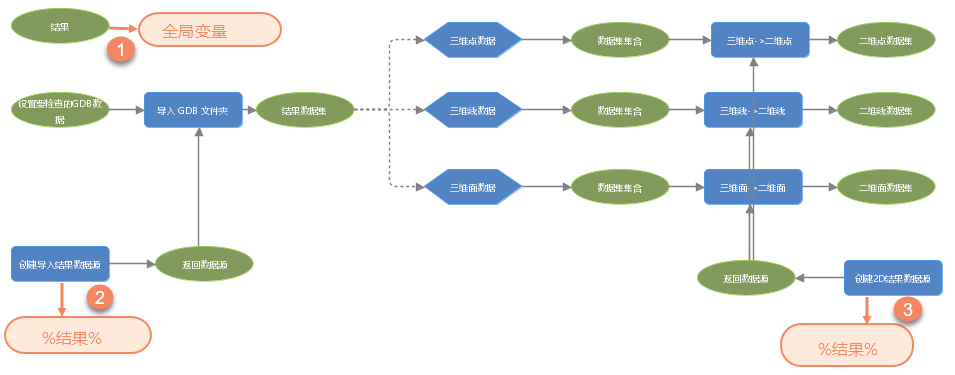
Variables are mainly used to store data in the model. When the model is too complex, variables can be added to the model as parameters for other tools to simplify the model. In the following model, it is necessary to convert gdb data into udbx data and convert the three-dimensional data in gdb data into two-dimensional data. The variable "result" in this model is a global variable, and the storage path for the "result" has been set. Afterwards, for "Create Import Result Datasource" and "Create 2D Result Datasource", inline variables are used to replace the% result%. Finally, during model operation, all running results will be replaced by inline variables. When it is necessary to modify the storage location of the running results, only the parameters of the "results" need to be modified.
Scenario 2: Replace the result data name with the input data file name
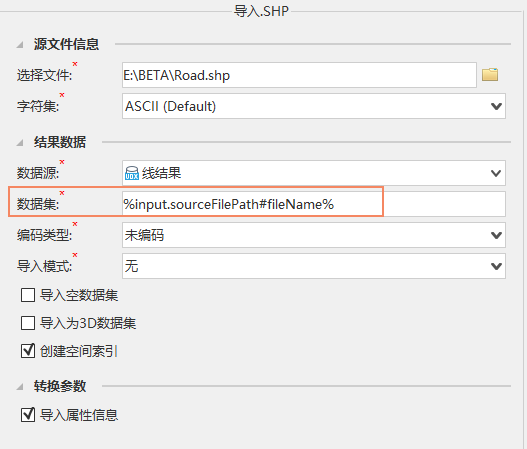
When importing shapefile files into udbx, you can choose the file name as an inline variable. In the following model, the input data path is E: BETA Road.shp, the Output Result dataset uses% input. sourceFilePath% to refer to the input path, and # fileName to refer to the file name. Therefore, during model execution, the 'Road' file name will be replaced by% input. sourceFilePath # fileName%, and the output dataset name will be 'Road'.

Scenario 3: Standardizing Result Data Names in Batch Processing
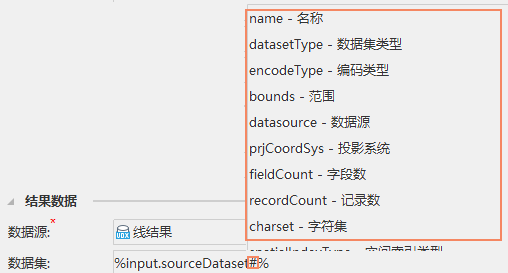
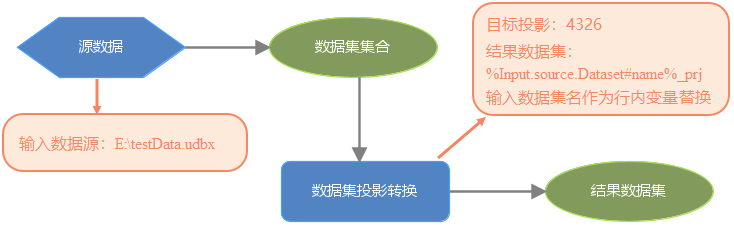
When batch processing of datasets or data files in the data source is required, "iterative datasets" or "iterative files" are usually used. The use of inline variable substitution in combination with "iterative dataset" or "iterative file" enables standardized naming of the results of batch data processing. In the following model, perform batch projection transformation on all datasets in the testData.udbx data source. When naming the Result Dataset for projection transformation, use% input. sourceDataset # name% to refer to the input dataset Name. Use the 'Iterative Dataset' tool to traverse the datasets in the udbx data source, and the result is a new dataset name composed of adding '_prj' to each input dataset name.
Instructions:
Enter '%' in the parameter box that needs to be replaced with inline variables, and the program will automatically pop up a list of parameters that can be referenced. Simply select the parameter. Usually, the path or dataset of the parameter is specified. If you need to specify specific attributes under the parameter (path or dataset), you can enter the '#' connector to automatically pop up a list of referenced attributes. Selecting the desired attributes constitutes a complete inline variable replacement. Example: When using iterators for batch data processing, a result will be output for each iteration file. The input data file Name can be replaced as an inline variable, replacing the dataset name of the Output Result to better identify the data result file.
Appendix - Data Types and Properties Supported for Inline Variable Replacement
| Data Type | Attribute English name | Attribute Chinese Name |
|---|---|---|
| Raster Dataset | name DatasetType encodeType bounds datasource prjCoordSys width height maxValue minValue noValue pixelFormat |
name Dataset Type Encoding Type Range Data Source Projection System Width Height Max Min No Value Pixel Format |
| Image Dataset | name DatasetType encodeType boundaries datasource prjCoordSys width height bandCount |
name Dataset Type Encoding Type Range Data Source Projection System Width Height Number of Wavebands |
| Vector Dataset | name datasetType encodeType bounds datasource prjCoordSys fieldCount recordCount charset spatialIndexType |
name Dataset type encoding type range data source projection system number of fields number of records character set spatial index type |
| Data Source | name engineType prjCoordSys workspace |
name Data Source Type Projection System Workspace |
| Field | name caption type |
name Field alias Field type |
| Workspace | name type |
name workspace type |
| Point Geometry Object | X Y |
X Y |
| Line geometry objects | boundaries inner length |
range inner point length |
| Surface Geometry Object | boundaries inner area perimeter |
range inner point area perimeter |
| Projection System | name epsg |
name EPSG |
| Double precision | hex octal octal binary round ceil floor |
hexadecimal octal binary round up round down |
| Single precision | hex octal octal binary round ceil floor |
hexadecimal octal binary round up round down |
| Integer | hex octal binary |
hexadecimal octal binary |
| Long Integer | hex octal binary |
hexadecimal octal binary |
| String | length upperCase lowerCase |
length uppercase lowercase |
| File Path | fileName fileExtension parentFile |
File Name Extension Parent Directory |