



Manage Replica overview
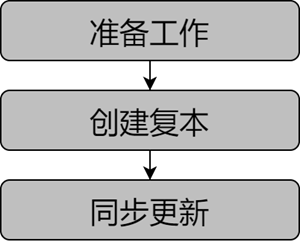
Manage Replica refers to the Copy Dataset that has been versioned to another Datasource to facilitate the collection and distribution of data. Manage Replica's workflow consists of three components:
Before doing Manage Replica, we need to understand the purpose of the replica and what data version to replicate from (currently only support Create Replica from the master version). For example, the copy is used for field work, but only the data of a certain area needs to be checked and updated. At this time, it is necessary to confirm that the Dataset content in the main version is Newest Version, and the All Data set of Create Replica is stored in the consolidated database, and confirm the scope of the area. Then start Create Replica.
Create Replica is to transfer the Copy Dataset in the master version to udbxDatasource, which is convenient for field workers or contractors to edit and process the data when they are unable to connect to the internal network.
Synchronous update is to update the edited copy of Data to the existing or newly created data version for the purpose of data collection and consolidation. If you update to the Existing Data version, the default update is to the master version data, and Replica Data overwrites the master version. If the data is updated to the new data version, a new subversion will be created, and after the synchronization update is completed, the Toggle The current version will be automatically updated to the new subversion. Handle edit conflicts may be required .
- Preparations
- Create Replica
- Synchronize updates
Use of Manage Replica
Different from Manage Data Version, Manage Replica can meet (but not limited to) the following scenario requirements to provide you with more convenient Data Management.
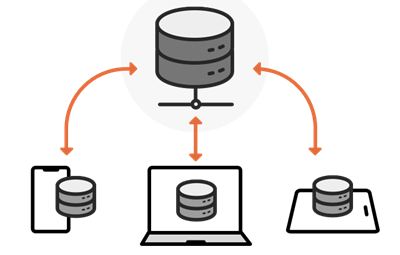
For data security, some data can only be viewed and edited on the internal network. However, field workers often need to go to the site to check the data and revise the data content, so they must Edit Data under the condition of external network. The copy version can copy and transmit the relevant data to the relevant equipment, which is convenient for field workers to operate. At the same time, when the operation is completed, you can re-connect to the internal network to synchronously update the edited data content to the database.
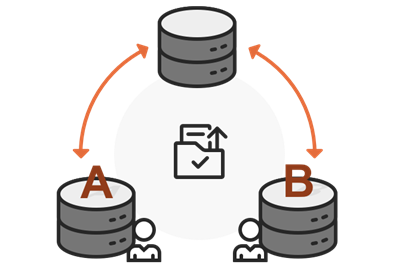
Some departments need to collect and organize a large amount of data. In order to speed up the work progress, the data modules are often outsourced to the relevant units, so that the relevant units can collect and update the data. Finally, the data processed by various contractors need to be merged and sorted out to facilitate Statistic Analysis. Manage Replica can replicate data by region, distribute data from different regions to different contractors, and synchronize Zonal Data to the same database.
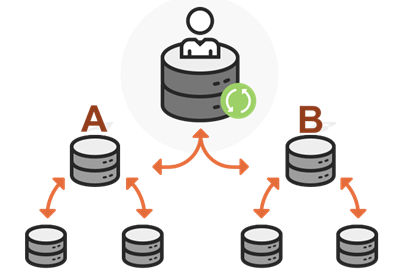
In different levels of Data Management, for example, national departments need to distribute data to provincial departments for maintenance and updating, while provincial departments distribute data to municipal departments for maintenance and updating, and the data updated by these municipal departments will eventually be merged into the database of national departments. Therefore, the data needs to be distributed layer by layer through Manage Replica, and finally recovered uniformly.
- Field work
- Work of the Contractor
- Data distribution and collection of relevant departments
Related topics