Instructions for use
Instructions for use
Single-point Regional Estimation, that is, SPAStatistical Inference method, takes the relevant variables as covariates when there is only one effective sample point for the survey object and the full coverage data of the relevant variables with large correlation can be obtained at the same time. A method of unbiased estimation of the population mean through this single sample point. When there is a strong correlation between the covariance and the survey object, the model can achieve an unbiased estimate of the target population.
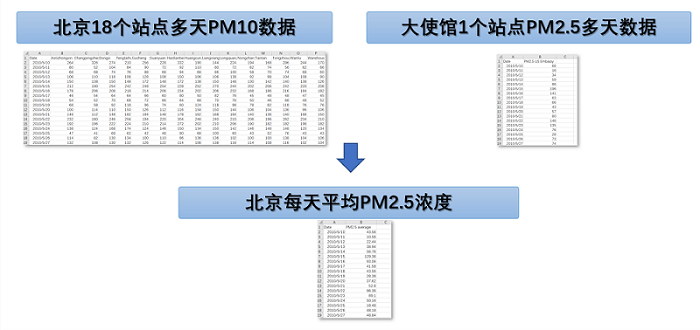
For example, when there is only one station's PM2.5 concentration data, it is difficult to interpolate the average value of the whole city, but if there is PM10 data of 18 stations in Beijing, the data trend of the data can be used as a reference to interpolate into PM2.5 data to estimate the average concentration of PM2.5 in Beijing.
Note: Functional principle and case cited from: Wang JF, Hu MG, Xu CD, Christakos G, Zhao Y.2012.Estimation of citywide air pollution in Beijing.PLoS ONE (1):e53400.
Function entrance
- Spatial Statistical Analysis tab-> Spatial Sampling and Statistical Inference-> Single-point Regional Estimation. (iDesktopX)
- Toolbox, Spatial Statistical Analysis, Spatial Sampling and Statistical Inference, Single-point Regional Estimation。 (iDesktopX)
Parameter Description
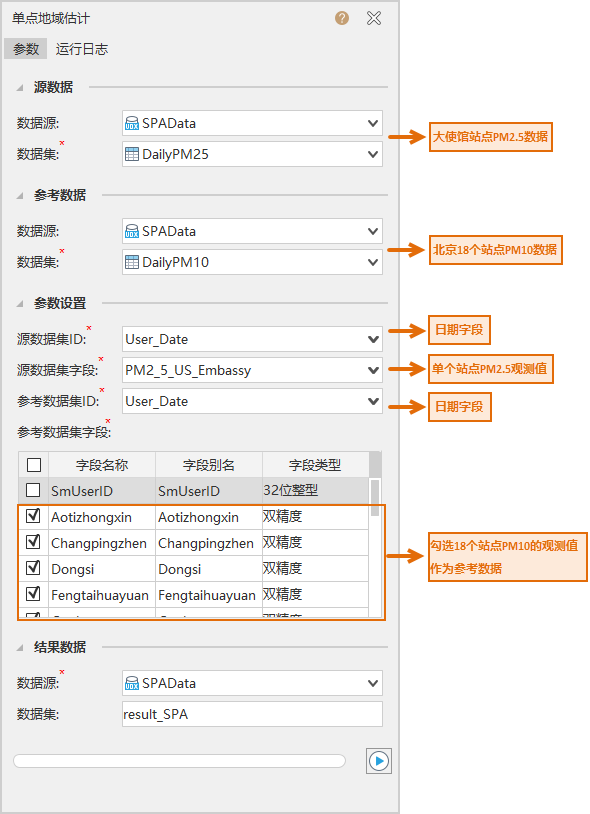
- Source Data: Set the Dataset for SPAStatistical Inference and the Datasource where it is located. In the case, it is the PM2.5 data of the embassy (multiple days).
- Reference Data: Set Reference dataset and its Datasource. In the case, PM10 data of 18 stations in Beijing (multiple days).
- Parameter Settings:
Source DatasetID: The specified Source Dataset unique Field. In the case, it is the field marked with date in PM2.5 data.
Source Dataset Field: The specified Source Dataset data Field. In this case, it is the field that records the PM2.5 observation value of the embassy.
Reference datasetID: The specified Reference dataset is unique to Field. In the case, it is the field marked with date in the PM10 data, which is consistent with the Source DatasetID.
Reference Dataset Field: Check the specified reference dataset data field. In the case, it is the field for recording PM10 observation values of multiple stations, with 18 items checked.
- Result Data: Set Result Dataset and its Datasource.
- Click the Execute button to execute the prepared analysis function. After the execution completed, the Output Window will prompt whether the Result succeeds or fails.
Application case
There are PM10 mass concentration values of 18 observation stations in Beijing (multiple days) and PM2.5 mass concentration values of one observation station of the US Embassy in China (multiple days). Based on these two data, we want to infer the average PM2.5 concentration of the whole area of Beijing. Since the concentrations of PM10 and PM2.5 are correlated, most PM10 is contributed by PM2.5. Therefore, the SPA single-site HELL statistical model can be used for the analysis. The data, Parameter Settings, and Show Result of the case are as follows:
Case Data: Click here to download the < a class = "contentpagehyperlink" href = "./data/SPAData. Zip" "=" "> SPA case data . After downloading, unzip it for use.
Parameter Settings: After downloading the above case data, open the SPAData. Udbx on the desktop and perform the Parameter Settings as shown in the following figure to execute the spa analysis.
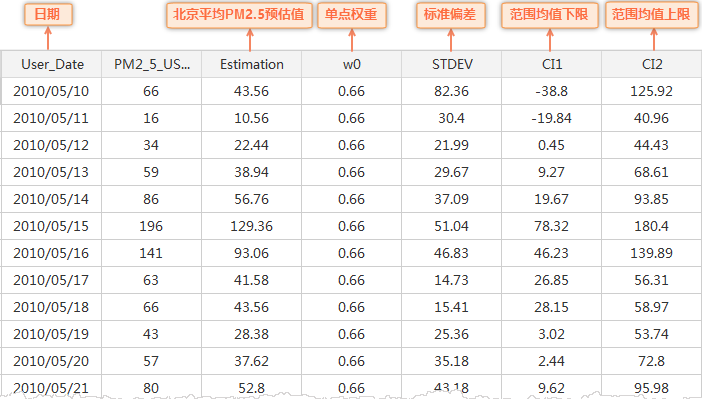
Result description: After SPASingle-point Regional Estimation, the average value of PM2.5 in Beijing can be obtained. The Result Data is shown in the figure below: