The tool can classify dense points as a cluster. The tool provides three clustering methods including Density Clustering, Hierarchical Clustering (HDBSCAN), and Ordering Clustering (OPTICS).
 Related Concepts
Related Concepts
- MinPts: the minimum points of a cluster.
- Clustering Radius ε: within a defined radius, the feature will consider points (counts are greater than MinPts) a cluster.
- Core Point: At least MinPts points are within distance ε of the core point, and those points are directly reachable from the core point.
- Border Point: a border point has fewer than MinPts points within its ε-neighborhood but is in the neighborhood of another core point.
- Noise Point: a noise point doesn't belong to any cluster.
- Core distance: the distance between the x point and the k point. The algorithm is corek(x). k is the value of MinPts. For example, if k is 5, the k point is the fifth point near to the x point.
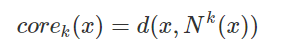
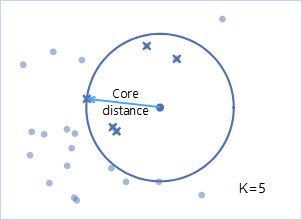
- Reachable Distance: compared the distance between two points with the core distance, the bigger one will be the reachable distance.
As the following picture shows, minPts is 3 and the clustering radius ε is d(P,5). The core distance of the point P is d(P,1). Since the distance from the point 2 to the point P is less than the core distance, the reachable distance of the point 2 is the core distance d(1,P), while the reachable distance of the point 4 is d(4,P).
Theory of the Analysis
- Density-based Spatial Clustering (DBSCAN)
The algorithm considers a certain dense points as a cluster. It isn't sensitive to noise points. Therefore, noise points won't have any effects on the clustering result. Besides, the algorithm can find clusters in any shape.
DBSCAN Theory: according to the given clustering radius (Eps) and the minimum number of point (MinPts) it determines all core objects and generates clusters.
If you are not satisfied with resulting clusters, you can adjust Eps and MinPts continuously until you get the satisfactory result. If you keep MinPts, the larger the Eps, the more points in one cluster. If you keep Eps, the larger the MinPts, the more noise points. The smaller the MinPts, the more core points.
Application: the algorithm applies to the situation that the clustering distance is defined. For example, there were 3 accidents within 2km neighborhood in one year. The area is considered an accident prone area. With the DBSCAN algorithm we can set the clustering radius to 2000m and MinPts to 3 to search accident prone areas.
- Hierarchical Density-based Spatial Clustering of Applications with Noise (HDBSCAN)
The algorithm can separate the sparse noise points from different densities of points according to the specified minimum number of points (MinPts). A hierarchical cluster creates the most stable cluster levels and group clustering points as many as it can.
HDBSCAN Theory: the algorithm is an improvement of the DBSCAN algorithm. It corrects the ineffective clustering result because of improper EPS, thereby reducing the sensitivity of result to parameters. In the meanwhile, HDBSCAN doesn't need to detect each point. To know about specific information on HDBSCAN, please refer to How HDBSCAN Works.
Analysis steps: based on the specified MinPts calculates each core distance and reachable distance, constructs the minimum spanning tree, connects and merges trees. And then splits the minimum spanning tree according to the following two conditions to get a stable cluster.
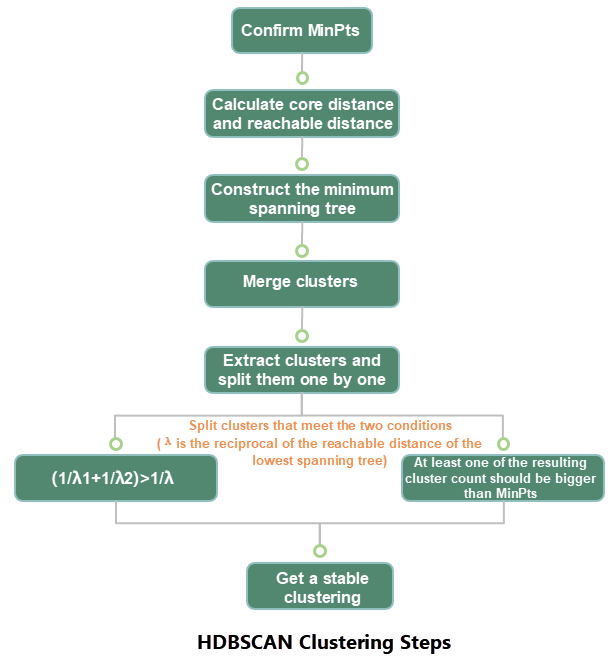
Extract clusters as the following conditions:
- Supposes the reachable distance of a spanning tree is λ. Find a proper point. At this point splits it into two clusters. Their reachable distances are λ1 and λ2 respectively. The 1/λ must be bigger than 1/λ1 plus 1/λ2. And repeats this step.
- If the number of points in both child clusters is less than the specified MinPts, the father cluster won't be split.
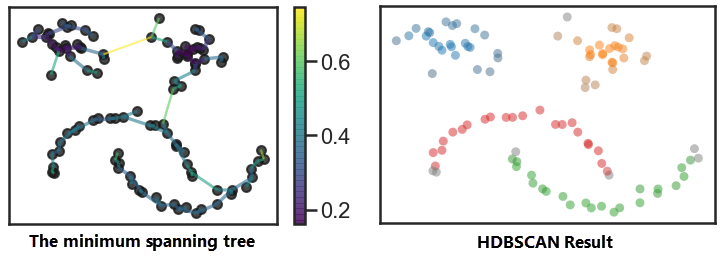
- Ordering Points to Identify Clustering Structure (OPTICS): the algorithm makes the clustering result not extremely dependent on Eps and MinPts. It separates noise points from different densities of clustering points in combination with the tightness of two adjacent features. The algorithm is most flexible compared with other clustering algorithms. But it is compute-intensive.
Sample Applications
- According to users' location information, you can provide new store locations of your chain restaurant.
- Urban underground water supply network may have some potential problems such as pipeline rupture and bursting. You can perform a density cluster analysis and set up emergency repair stations in areas with dense burst points to facilitate the construction personnel to quickly rush to the construction.
- The density-based clustering allows you to check the city's traffic accident-prone sections, for example: within 2000m or the entire road bridge, culvert, road sections with more than 3 major traffic accidents in a year.
- You can perform a cluster analysis on the distribution locations of animals and plants to know more about the inherent structure.
- Anomaly detection: In data cleaning, some typical problematic data can be eliminated. Besides, it can also be used to find abnormal users, such as anti-theft brushing and anti-repling.
Function Entrances
iDesktopX provides two functional entrances.
- Spatial Analysis > Spatial Statistic Analysis > Cluster Distributions > Density Clustering.
- Toolbox > Spatial Statistical Analysis > Cluster Distributions > Density Clustering.
Main Parameters
The three algorithms required different parameters.
| Clustering Mode | DBSCAN | HDBSCAN | OPTICS |
|---|---|---|---|
| Required Parameter | Clustering radius Point Count Threshold |
Point Count Threshold | Clustering radius Point Count Threshold Cluster Sensitivity |
| Resulting Field | Source data ID(Source_ID) Cluster Mode (Cluster_ID) |
Source data ID(Source_ID) Cluster Mode (Cluster_ID) Clustering Probability (Prob) Outlier (Outlier) Cluster Representative (Exemplar) Clustering Stability (Stability) |
Source data ID(Source_ID) Cluster Mode (Cluster_ID) Point Order (ReachOrder) Reachable Distance (ReachDist) |
- Source Data: specify the input dataset.
- Cluster Method: the product provides three cluster methods.
- Density Clustering: finds dense clustering points and sparse noise points according to the specified radius. This algorithm needs two parameters including clustering distance and point count threshold.
- HDBSCAN: separates sparse noise points from different densities of clustering points according to changeable distances and point count threshold. This algorithm needs only one parameter point count threshold.
- OPTICS: separates sparse noise points from different densities of clustering points according to the distance and tightness of adjacent elements. This algorithm needs three parameters including clustering radius, point count threshold, and cluster sensitivity.
- Radius: for different algorithms radiuses have different meanings.
- The DBSCAN algorithm will find more than MinPts points within the radius distance and group them as a cluster.
- For the OPTICS algorithm, the radius is the biggest reachable distance that is the distance from a point to its adjacent undetected point. The algorithm will search all adjacent distances within the radius and compare them with the core distance.
- Distance Unit: the unit of clustering distance. The provided units include cm, mm, dm, m (by default), km, yard, mile, and feet.
- Point Count Threshold: the minimum number of points in one cluster.
- Cluster Sensitivity: the value ranges from 0 to 100. The cluster with the value close to 100 is more dense than the cluster with the value close to 0. Similarly, the cluster with lower reachable distance is more dense.
Output
- Source_ID(Source ID): SmIDs of source points.
- Cluster_ID(clustering category): the category of each point. The points with the same Cluster_ID will be in the same cluster. -1 means the point is a noise point.
- Prob(Cluster probability): the probability that a point belongs to a cluster. 1 means there is a great probability that the point belongs to the cluster. 0 means the point may be an outlier.
- Outlier (outlier): the element may be an outlier. 1 means there is a great probability that the point is an outlier. 0 means the point is not an outlier.
- Exemplar(cluster representative): the point that has the value 1 is the most representative point in a cluster.
- Stability(stability of cluster): the stability of each cluster category.
- ReachOrder(Points order): the order of processing points.
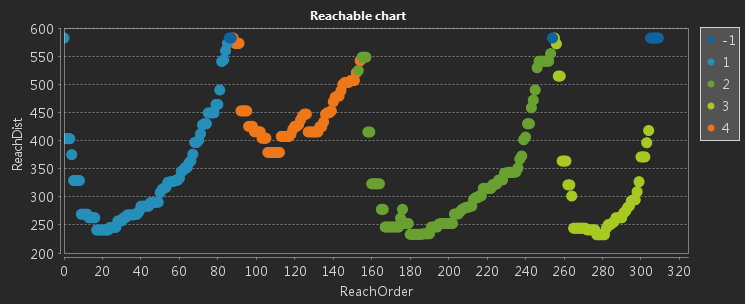
- ReachDist(Reachable distance): the reachable distance from a point to its adjacent point. We can create a reachable chart according to ReachOrder and ReachDist to assess sensitivities of clusters. The less the ReachDist, the denser the cluster. As the following pictures show, the yellow cluster has a bigger reachable distance, and so sparse.
Instance
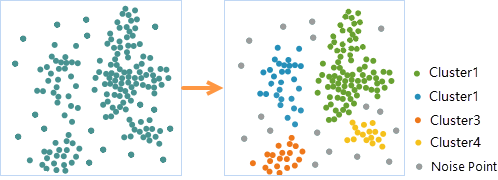
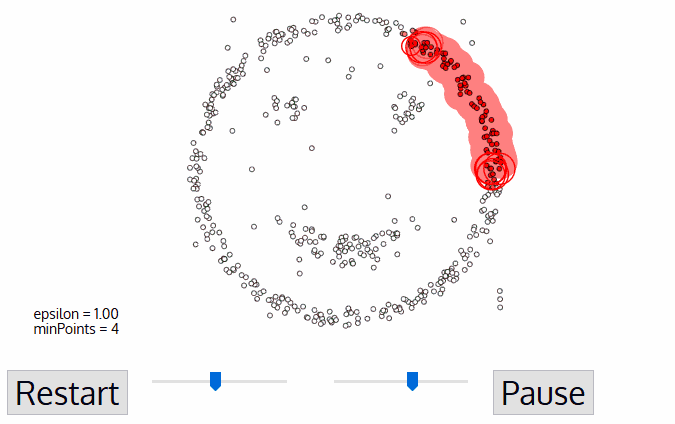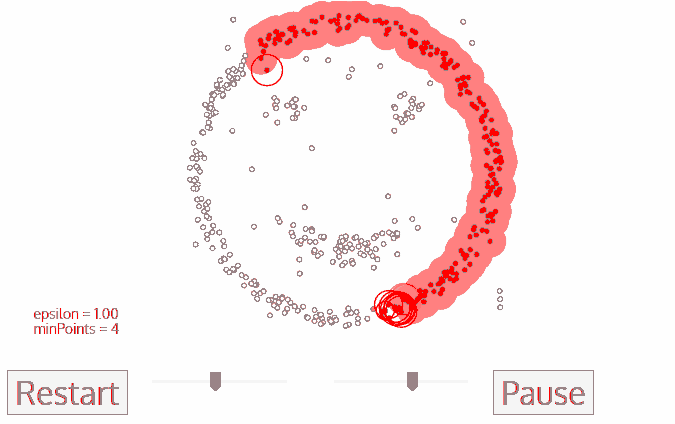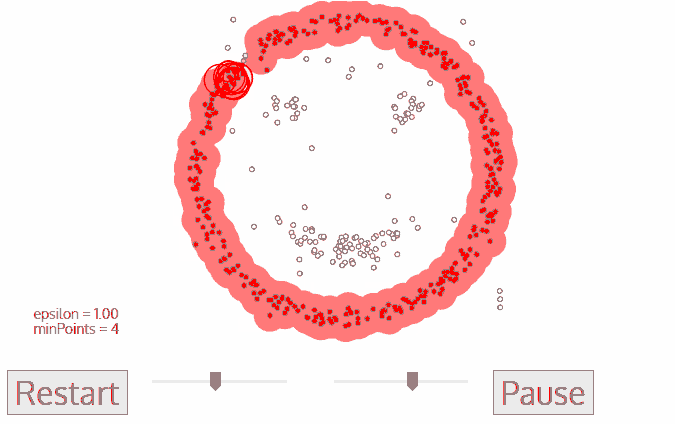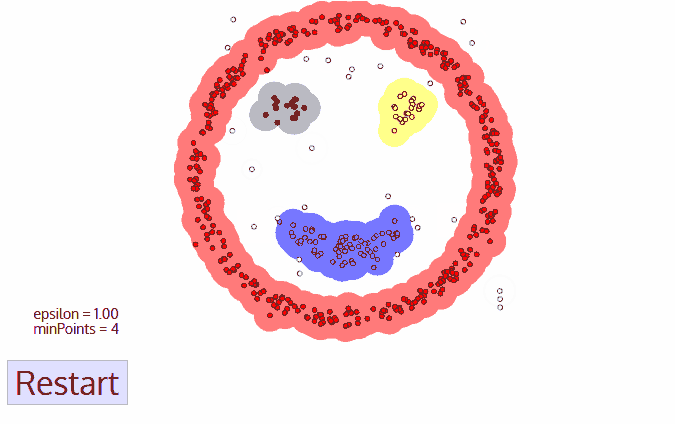
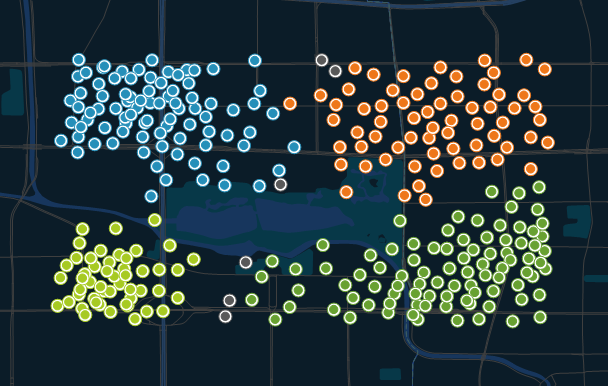
If we get the data on the starting point for customers of a certain chain restaurant in a certain area, there are more customers in the store recently, and so the waiting time for queuing is longer. In order to better serve customers and shorten the queue time, the boss decides to open a new store. And then we can use the density-based clustering tool to analyze the distribution of customers and open new stores in areas where customers are densely distributed. Taking into account the distance of customers dining, I used the method of sequential density clustering to analyze the data, and the results are shown in the figure below. The customers of restaurants in this area can be divided into four clusters, and the gray is the noise. At the same time, site selection can be carried out in four cluster areas.
 Related Topics
Related Topics