写出UDB/UDBX表结构
使用说明
根据输入的数据表结构信息,向UDB/UDBX文件型数据源中创建或更新对应的数据表及其属性结构。
输入数据
| 参数名 | 参数释义 | 参数类型 |
|---|---|---|
| 输入 | 含有表结构信息的数据源,通常由其他转换器的输出提供。 | IFeatureCollection |
参数说明
| 参数名 | 参数释义 | 参数类型 |
|---|---|---|
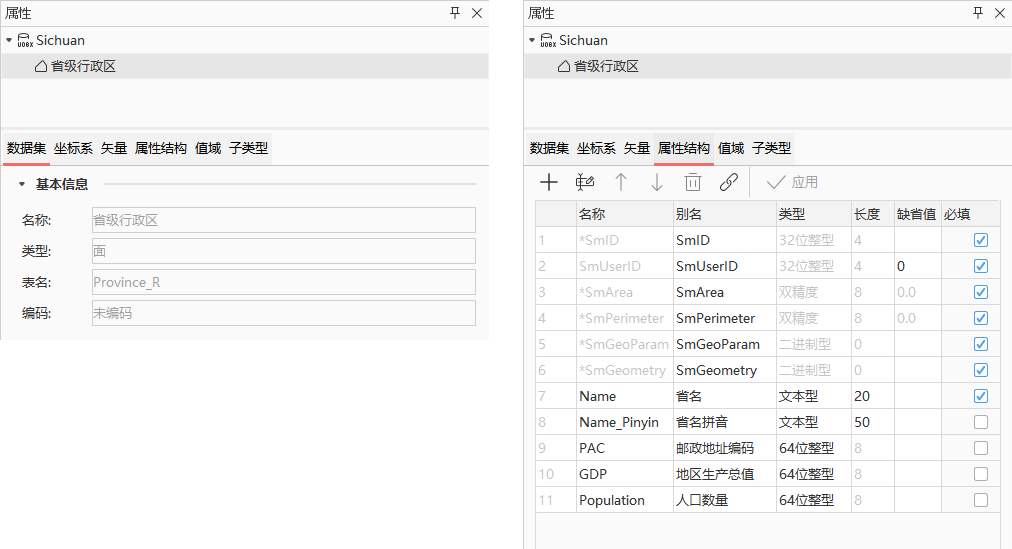
| 写出路径 |
指定本地目录中的UDB/UDBX文件型数据源。 |
String |
| 写出方式 | 指定数据表操作方式:
|
WriterType |
| 数据表名 | 指定数据表名所在的列,将自动读取该列的值作为创建或更新的数据表名称。数据表名称需遵循以下命名规范:
|
String |
| 数据表别名 |
可选参数,指定数据表别名所在的列,将自动读取该列的值作为创建或更新的数据表别名。
|
String |
| 数据表类型 |
指定数据表类型(几何类型)所在的列,支持的值有table、point、piontz、line、linez、linem、polygon、polygonz、text、model、cad。 若此列的值为空,或含有其他值,则执行失败。 |
String |
| 字段名称 |
指定字段名称所在的列,将自动读取该列的值作为创建或更新的字段名称。字段名称需遵循以下命名规范:
|
String |
| 字段别名 |
可选参数,指定字段别名所在的列,将自动读取该列的值作为创建或更新的字段别名。
|
String |
| 字段类型 |
指定字段类型所在的列。支持的类型有如下,不区分大小写。
|
String |
| 字段长度 |
可选参数,用于指定文本型或字符型字段的长度所在列。如未指定或该列值为空,则采用默认字段长度,文本型和字符型字段的默认长度将分别设为255和1。 对于16位整型、32位整型、64位整型、双精度、单精度、布尔、日期、字节及二进制类型字段,此设置不适用,其长度始终采用程序预设值。 |
String |
| 字段默认值 | 可选参数,指定字段默认值的列。例如,Education_P数据表中Province字段的默认值为“四川省”,成功创建表结构后,向该表创建对象时,Province字段的值都会自动填充为“四川省”。 | String |
| 字段必填 |
可选参数,指定字段是否为必填的列。
|
String |
| 字段顺序 | 可选参数,指定字段在数据表中的排列顺序。若不指定或该列的值为空,则根据该列的顺序创建字段。 | String |
输出结果
| 参数名 | 参数释义 | 参数类型 |
|---|---|---|
| 统计数据 | 统计成功写出的数据信息。 | IFeatureCollection |
| 无效数据 | 当前转换器无法处理的记录。 | IFeatureCollection |
应用示例
数据说明
Excel中的数据表信息如下所示,包含Province_R和Education_P两个数据表。
| 数据表名称 | 数据表类型 | 数据表别名 | 字段名称 | 字段类型 | 字段长度 | 字段别名 | 字段默认值 | 字段必填 | 字段排序 |
|---|---|---|---|---|---|---|---|---|---|
| Province_R | polygon | 省级行政区 | Name | 文本型 | 20 | 省名 | Y | 1 | |
| Name_Pinyin | 文本型 | 50 | 省名拼音 | N | 2 | ||||
| PAC | 64位整型 | 8 | 邮政地址编码 | N | 3 | ||||
| GDP | 64位整型 | 8 | 地区生产总值 | N | 4 | ||||
| Population | 64位整型 | 8 | 人口数量 | N | 5 | ||||
| Education_P | point | 教育机构 | Name | 文本型 | 20 | 机构名称 | Y | 1 | |
| Province | 文本型 | 20 | 所属省份 | 四川省 | Y | 4 | |||
| City | 文本型 | 20 | 所属城市 | Y | 3 | ||||
| Country | 文本型 | 20 | 所属区县 | Y | 2 |
操作说明
- 在新建的模型窗口中添加读入Excel转换器,指定数据来源并勾选首行为字段信息复选框。
- 添加写出UDB/UDBX表结构转换器,将其与上一步的读入Excel转换器相连接。
- 在写出UDB/UDBX表结构中配置表结构对应关系,如下图:
- 执行模型。
结果展示
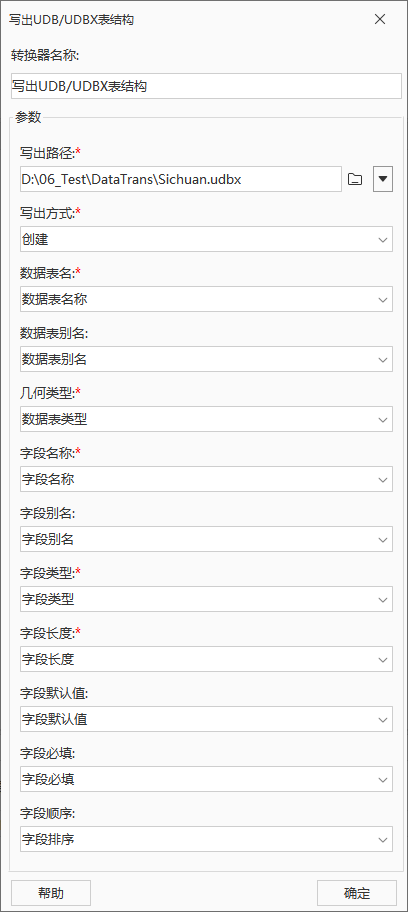
在SuperMap iDesktopX打开Sichuan.udbx数据源可查看具体创建结果,如下所示,创建了省级行政区和教育机构两个数据集(在SuperMap iDesktopX中数据集以别名显示)。

以省级行政区为例,通过数据集属性查看属性结构信息,结果如下图: