
处理组件包含提示词模板、保存文件、分割文本、结构化输出等多种子组件,负责在工作流中对数据进行加工和转换,具有多种实用功能,例如:
- 通过提示模板组件为您的LLM和智能体注入指令与上下文
- 使用解析器组件从大型数据块中精准提取所需内容
- 借助智能函数组件通过自然语言实现数据筛选
- 通过保存文件组件将数据持久化存储至本地设备
- 利用类型转换组件将数据转换为不同格式,解决组件间的兼容性问题
提示词模板
提示词模板组件可用于创建专门的提示内容,为大语言模型或智能体提供指令与上下文信息。这类提示内容独立于聊天消息、文件上传等其他输入形式。
提示词模板采用结构化输入方式,通过自然语言、固定值和动态变量相结合的形式,为模型提供基础背景信息。其主要作用包括:
- 为用户查询定义统一结构,便于模型准确理解并作出恰当回应
- 为模型输出定义特定格式要求(如JSON或结构化文本)
- 为模型设定特定角色(例如“您是一位乐于助人的助手”或“您是微生物学专家”)
- 使模型能够调用聊天记忆记录
- 提示模板组件还可将包含变量的指令输出至工作流下游的其他组件。
保存文件
保存文件组件用于将其他组件生成的数据保存为文件,该组件支持多种文件格式,并允许将文件存储在存储空间或本地文件系统中。
在工作流中配置并使用保存文件组件的操作步骤如下:
- 将其他组件的DataFrame、Data或Message类型输出端连接至保存文件组件的"输入"端口。如需创建多个文件或以不同格式保存数据或存储到多个位置,可将同一输出连接至多个保存文件组件;
- 在"文件名"参数中输入文件名及可选路径,该参数用于控制文件存储位置,支持以下格式:
- 默认位置:仅输入文件名时,文件将保存在数据目录
- 子目录存储:如需在子目录中保存文件,请在文件名中包含路径。若指定子目录不存在,系统将自动创建(例如输入"files/my_file"将在/data/files目录下创建my_file文件,并自动生成files子目录)
- 绝对/相对路径:如需保存至其他位置,可输入绝对或相对路径(例如"/Desktop/my_file"将文件保存至桌面)
- 点击组件顶部菜单中的控制项,选择所需文件格式后点击关闭,可选文件格式取决于输入数据类型:
- DataFrame:CSV(默认)、Excel(需openpyxl依赖)、JSON(备用默认)、Markdown
- Data:CSV、Excel(需openpyxl依赖)、JSON(默认)、Markdown
- Message:TXT、JSON(默认)、Markdown
- 点击运行组件测试保存操作,然后点击检查输出查看文件保存路径,组件输出的Message包含以下信息:原始数据类型、文件名与扩展名、基于"文件名"参数生成的绝对路径
若文件名中包含子目录或其他非默认路径,这些路径信息也会完整呈现在Message输出中。例如,若将CSV文件命名为"~/Desktop/my_file",则可能会输出如下结果:
DataFrame saved successfully as '/Users/user.name/Desktop/my_file.csv' at /Users/user.name/Desktop/my_file.csv
-
可选操作:如需在工作流中使用已保存的文件,需通过API调用或其他组件从指定文件路径读取该文件
通过以上配置,即可灵活实现数据持久化存储功能。
分割文本
分割文本组件可根据文本块大小、分隔符等参数,将输入数据切分为多个文本片段。该组件通常用于对数据进行分块处理,以便后续进行分词和向量数据库嵌入操作。
该组件支持接收Message、Data或DataFrame类型输入,可输出Chunks或DataFrame两种格式。选择Chunks输出时将返回由多个Data对象组成的列表,每个对象包含一个独立文本片段;选择DataFrame输出时则将文本块列表转换为结构化数据框,并额外包含文本内容与元数据列。
结构化输出
结构化输出组件借助大语言模型,通过自然语言格式指令与输出模式定义,将任意输入转换为结构化数据(Data或DataFrame格式)。例如,您可以从电子邮件、科学论文等文档中提取特定细节信息。
在工作流中使用结构化输出组件的操作步骤如下:
- 提供输入消息:输入消息是待提取结构化数据的原始素材,可来自几乎所有组件(通常来源于聊天输入、文件组件或其他能提供非结构化/半结构化输入的组件)。
 注意:
注意:并非所有原始素材都需要完全转换为结构化输出。该组件的优势在于:即使数据未明确标注或完全匹配关键词,您仍可指定需要提取的信息。大语言模型将根据您的指令分析原始素材,提取相关数据并按规范格式化,所有无关内容均不会出现在最终输出中。
- 定义输入消息与输出模式:通过输入消息明确需要从原始素材中提取的数据内容,通过输出模式定义最终Data或DataFrame输出的数据结构。
- 输入指令:作为提示词,告知大语言模型需要提取的数据内容、格式要求、异常处理方式等与结构化数据准备相关的指令
- 输出模式:通过字段(键名)和数据类型定义表,将大语言模型提取的数据组织成结构化Data或DataFrame对象(详见输出模式选项说明)
- 连接语言模型组件:接入已设置为输出LanguageModel类型的语言模型组件。大语言模型将结合结构化输出组件提供的输入消息和格式指令,从输入文本中提取特定数据片段,并依据输出模式将模型响应转换为最终的Data或DataFrame结构化对象。
- 可选操作:通常可将结构化输出传递至下游组件(如解析器或数据操作组件),将提取的数据用于后续处理工作流。
解析器
解析器组件通过模板或直接字符串化方式,从结构化数据(DataFrame或Data)中提取文本内容,输出结果为包含解析文本的Message类型数据
此组件使用模板将DataFrame或Data对象格式化为文本,并可以选择使用stringify直接将输入转换为字符串。
要使用此组件,请在模板中创建变量,方式与在提示词组件中相同。对于DataFrames,使用列名,例如Name: {Name}。对于Data对象,使用{text}。
基本使用方法
在模板中创建变量(方法与提示词组件相同):
- 处理DataFrames:使用列名作为变量,例如:姓名:{Name}
- 处理Data对象:使用{text}变量
与结构化输出组件配合使用方法
- 将结构化输出组件的DataFrame输出端连接至解析器组件的DataFrame输入端;
- 将文件组件连接至结构化输出组件的消息输入端;
- 将OpenAI模型组件的语言模型输出端连接至结构化输出组件的语言模型输入端;
- 在结构化输出组件中,点击Open Table按钮,进入表格构建界面(包含名称、描述、类型等多列配置项);
- 创建与文件数据对应的字段结构。例如构建员工信息表,可添加id、name、email等字段行,数据类型均设置为字符串;
- 在解析器组件的模板字段中,输入将DataFrame输出解析为结构化文本的模板。变量创建方式与提示词组件一致;
- 运行工作流后,点击解析器组件的查看输出内容按钮即可查看解析生成的文本;
- 可选操作:连接聊天输出组件后,打开试验场交互界面查看最终输出效果。
类型转换
类型转换组件用于实现不同数据类型之间的相互转换,支持处理Data、DataFrame及Message三种数据类型。
批量运行
批量运行组件可对DataFrame中指定文本列的每一行数据调用语言模型,并返回包含原始文本和LLM响应的新DataFrame。输出结果包含以下列:
- 文本:来自输入DataFrame的原始文本
- model_response:对应每个输入文本的模型回复
- batch_index:DataFrame中所有行的处理序号(从0开始计数)
- metadata:有关处理过程的其他信息(可选列)
在工作流中使用批量处理组件
若将批量处理组件的输出传递至解析器组件,您可在解析模板中使用变量引用输出列,例如{text_input}和{model_response}。具体操作工作流如下:
- 将任意语言模型组件连接至批量处理组件的语言模型端口
- 将其他组件的DataFrame输出连接至批量处理组件的DataFrame输入端口(例如连接包含CSV文件的文件组件)
- 在批量处理组件的列名字段中,输入待处理文本所在列的列名(例如若需处理CSV文件中"name"列的文本,则输入"name")
- 将批量处理组件的批处理结果输出端连接至解析器组件的DataFrame输入端口
- 可选:点击批量处理组件顶部菜单中的控制选项,启用系统消息参数后输入处理指令(例如"为每个姓名生成商务名片")
- 在解析器组件的模板字段中,构建处理批量输出列(text_input、model_response、batch_index)的模板:
例如,以下模板使用了批处理后DataFrame中的三列数据:
record_number: {batch_index}, name: {text_input}, summary: {model_response}
点击解析器组件的运行按钮,并通过查看输出内容查看最终生成的DataFrame。如需在试验场中查看输出效果,可将聊天输出组件连接至解析器组件。
数据操作
数据操作组件用于对数据对象执行各类操作,包括键值对的提取、筛选和编辑等功能。完整操作选项如下表。该组件将输出包含修改后数据的新数据对象。
| 操作名称 | 必需输入参数 | 功能说明 |
|---|---|---|
| Select Keys | select_keys_input | 从数据中筛选特定键 |
| Literal Eval | 无 | 将字符串值解析为Python字面量 |
| Combine | 无 | 合并多个数据对象 |
| Filter Values | filter_key, filter_values, operator | 根据键值对过滤数据 |
| Append or Update | append_update_data | 添加或更新键值对 |
| Remove Keys | remove_keys_input | 移除指定键 |
| Rename Keys | rename_keys_input | 重命名数据中的键 |
在工作流中使用数据操作组件
以下示例演示如何通过Webhook载荷数据在工作流中使用数据操作组件:
1、创建新工作流,添加Webhook组件和数据操作组件,将Webhook组件的输出连接至数据操作组件的“数据”端口
所有数据操作都需要至少一个来自其他组件的数据输入。若前置组件无法直接输出数据格式,可先使用类型转换组件进行格式转换,也可考虑使用专用于处理原始数据类型的组件(如解析器或DataFrame操作组件)
2、在"操作"参数中,选择需要执行的操作。本例选择"键值筛选"操作。提示:每次仅能选择单一操作。如需执行多项操作,可将多个数据操作组件串联使用。对于更复杂的多步操作,建议考虑使用智能函数组件
3、在"选择键"配置区,添加name、username和email字段键。点击添加更多新增字段键每
本例假设Webhook接收的载荷始终包含name、username和email键。键值筛选操作将从每个传入载荷中提取这些键对应的值
4、可选步骤:如需在试验场中查看输出,可将数据操作组件的输出连接至聊天输出组件
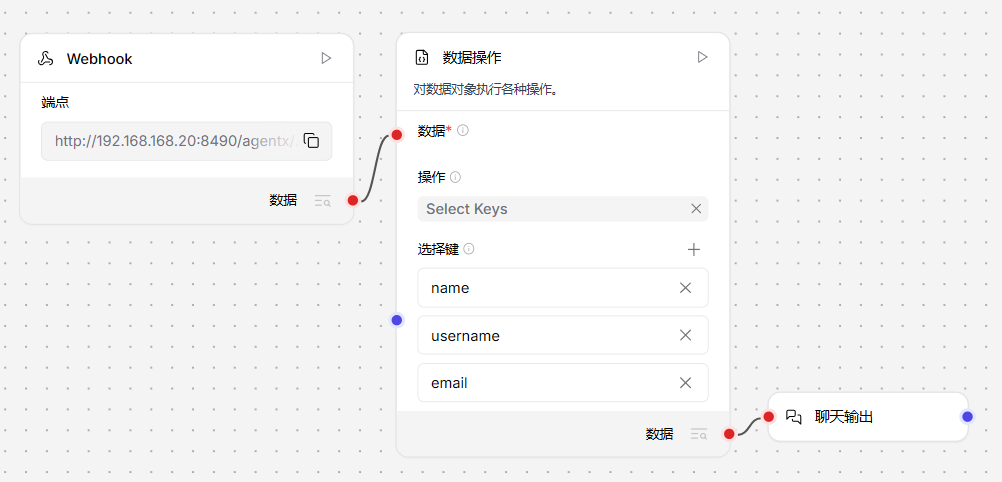 |
| 图:基于数据操作组件的工作流构建示例 |
5、向工作流的Webhook端点发送测试请求以验证工作流运行
6、通过以下任一方式查看"键值筛选"操作生成的数据结果:
- 若已连接聊天输出组件,打开试验场界面查看聊天形式的结果展示
- 点击数据操作组件上的查看输出内容按钮直接查看数据
智能函数
智能函数组件通过接入大语言模型,能够根据自然语言指令生成 Lambda 函数,用以筛选或转换结构化数据。使用时需将其连接至语言模型组件,由语言模型根据您在“指令”参数中提供的自然语言描述生成相应函数。随后,大语言模型将执行该函数处理输入数据,并将处理结果以 Data 格式输出。
使用建议
请尽量使用简洁、清晰的指令,重点说明期望的结果或具体操作,例如:“筛选数据,仅保留‘状态’为‘活跃’的条目”。建议指令控制在一句话以内,因为句末标点(如句号)可能引发错误或意外行为。
如需提供与 Lambda 函数生成无直接关系的更详细说明,可将这些内容输入至语言模型组件的“输入”字段,或通过提示模板组件传递。
DataFrame操作
DataFrame操作组件用于对数据表(DataFrame)进行行列操作,包括结构调整、记录修改、排序筛选等功能。完整操作选项请参阅下表。
该组件输出结果为包含修改后数据的新DataFrame。
| 操作 | 描述 | 所需输入 |
|---|---|---|
| Add Column | 添加一个具有常量值的新列 | new_column_name, new_column_value |
| Drop Column | 移除指定的列 | column_name |
| Filter | 根据列值过滤行 | column_name, filter_value |
| Head | 返回前 n 行 | num_rows |
| Rename Column | 重命名现有列 | column_name, new_column_name |
| Replace Value | 替换列中的值 | column_name, replace_value, replacement_value |
| Select | Columns 选择指定的列 | columns_to_select |
| Sort | 按列对 DataFrame 进行排序 | column_name, ascending |
| Tail | 返回后 n 行 | num_rows |
在工作流中使用DataFrame操作组件
以下步骤详细说明如何在工作流中配置DataFrame操作组件。您可参照示例工作流或使用自有工作流进行操作,唯一前提是前置组件需生成可供传递的DataFrame输出。
1、创建新工作流或打开现有工作流
2、添加DataFrame操作组件,将前置组件的DataFrame输出端连接至本组件的DataFrame输入端。所有DataFrame操作都需要至少一个DataFrame输入。若组件无法直接输出DataFrame格式,可先使用类型转换组件进行格式转换,也可考虑使用专用于处理原始数据类型的组件(如解析器或数据操作组件)
3、在"操作"参数中,选择需要执行的操作。例如选择"Filter"操作,可根据指定列和值过滤数据行。每次仅能选择单一操作。如需执行多项操作,可将多个DataFrame操作组件串联使用。对于复杂的多步操作(如大幅结构调整或数据透视),可考虑使用基于大语言模型的组件(如结构化输出或智能函数组件)进行预处理或替代方案
4、配置“操作”参数(具体参数因所选操作而异)。例如选择"筛选"操作时,需通过"列名"、"筛选值"和"筛选运算符"定义过滤条件
5、点击DataFrame操作组件的"运行组件"测试工作流,通过"查看输出内容"查看筛选操作生成的新DataFrame
6、如需在试验场中查看输出,请将组件输出连接至聊天输出组件,重新运行组件后点击试验场即可
LLM路由器
LLM路由器组件基于OpenRouter模型规范,将请求智能路由至最合适的大语言模型。
在工作流中使用时,需将多个语言模型组件连接至LLM路由组件。其中一个模型作为裁决模型,负责分析输入消息以理解评估上下文,从其他连接的LLM中选取最合适的模型,并将输入路由至所选模型。被选中的模型处理输入后,返回生成的响应。
LLM路由组件输出选项
该组件提供三种输出类型,您可通过组件输出端口附近的选项进行设置:
- 输出:输出由被选中的LLM生成的对话回复(Message格式),适用于常规对话交互场景
- 选定的模型信息:输出包含被选中模型详细信息的数据对象(Data格式),包括模型名称、版本等元数据
- 路由决策:输出裁决模型的决策依据(Message格式),包含选择特定模型的原因分析(例如:"输入查询内容过长,在参与筛选的3个模型中最终选定处理长文本能力最强的GPT-4")
Python解释器
该组件支持在工作流中执行已导入依赖包的Python代码。且只能调用您当前环境中已预安装的软件包。若执行时出现ImportError,请先确保目标包已完成安装。
在工作流中使用Python解释器组件
1、在“全局导入”参数中添加需要导入的包(至少一个),多个包名用逗号分隔,例如:math,pandas
2、在Python代码字段中输入要执行的代码,可通过print()函数查看输出结果
3、可选:在顶部菜单启用工具模式后,可将Python解释器组件作为工具连接至智能体组件。例如同时连接Python解释器和计算器组件作为智能体的工具,测试其如何选择不同工具解决数学问题
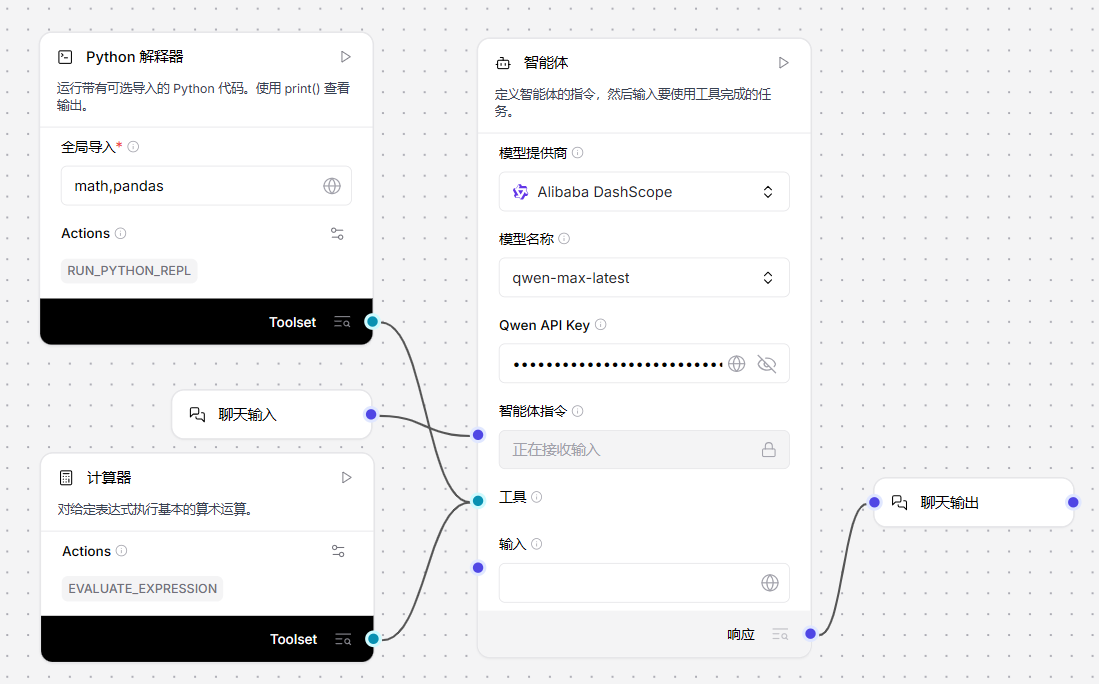 |
| 图:基于Python解释器组件的工作流构建示例 |
4、向智能体提出基础数学问题(计算器工具支持加减乘除及乘方运算),智能体将自动调用evaluate_expression工具正确解答
5、向智能体提供完整Python代码示例(使用已导入的pandas包创建DataFrame表格,并返回均方根计算结果),智能体将准确选用run_python_repl工具执行代码
即使未在对话中声明包导入,智能体仍可通过全局导入的pandas包使用pd.DataFrame创建表格,因为Python解释器组件已在全局导入字段中预先配置了pandas包。